

July 14, 2022
StarRocks Brings Speedy OLAP Database to the Cloud

(Blue Planet Studio/Shutterstock)
Companies that keep hitting their heads on performance limitations of existing analytics databases may want to check out the fast new cloud analytics offering rolled out today by StarRocks, the commercial entity backing the Apache Doris project.
The column-oriented, MPP database that would become Apache Doris was originally developed by engineers at Chinese Internet giant Baidu after they struggled to get the necessary query performance out of their existing Hadoop clusters. The company was using Apache Hive and Apache Impala, but it eventually found the scale of its business exceeded what those Hadoop-era SQL engines could deliver on their own.
Baidu commenced its Palo Project to build a replacement system. The architecture devised by Baidu engineers integrates technology form Impala and Mesa, a distributed data warehouse created by Google to store critical data related to its ads business. In particular, the attributes connected with Mesa–specifically, the ability to provide near real-time data ingestion and queryability–as well as the new vectorization technology that Baidu brought to bear, would lend themselves to the speed of Palo (renamed Doris).
Baidu open sourced Doris in 2017 and entered the Apache Incubator project in 2018. Over the years, the software has been adopted by more than 500 organizations, including many of China’s top Internet companies like ByteDance, Tencent, and Xiaomi, as well as American firms like Airbnb and Trip.com.
StarRocks was incorporated in May 2020 to commercialize Doris. The San Jose-based company has raised $60 million to date while developing an enterprise version of the software. Today it launched its first hosted offering, called StarRocks Cloud, which is available as a beta on AWS, with general availability excepted in the third quarter. Support for other clouds will follow.![]()
The database is designed for customers who need low latency and high concurrency for analytical queries. However, those have been difficult attributes to deliver with traditional databases working on snowflake and star schemas, says StarRocks’ Vice President of Strategy Li Kang.
“The challenge is that when you query against the set of tables that you’ve joined together, the query performance struggles, and that’s for pretty much all the databases,” he says. “All the data warehouse, all the query engines have similar issues.”
Instead of snowflake and star schemas, some customers with the biggest real-time analytics needs have shifted to using denormalized tables, which can speed up queries and lower latencies on decision-making. ClickHouse and Apache Druid are examples of data analytics engines that use the denormalized approach.
The denormalized approach delivers great query performance, according to Kang. However, it also introduces other data challenges.
“The data pipeline becomes very complex,” he tells Datanami. “You have to flatten those tables and that also add delays to data ingestion, which is obviously a problem for real time.”
Problems also arise if a change has to be made to the star schema, such as if the business needs to add new dimension tables or modify an existing dimension table. “You have to rebuild and repopulate that fact table or set of fact tables,” Kang says.
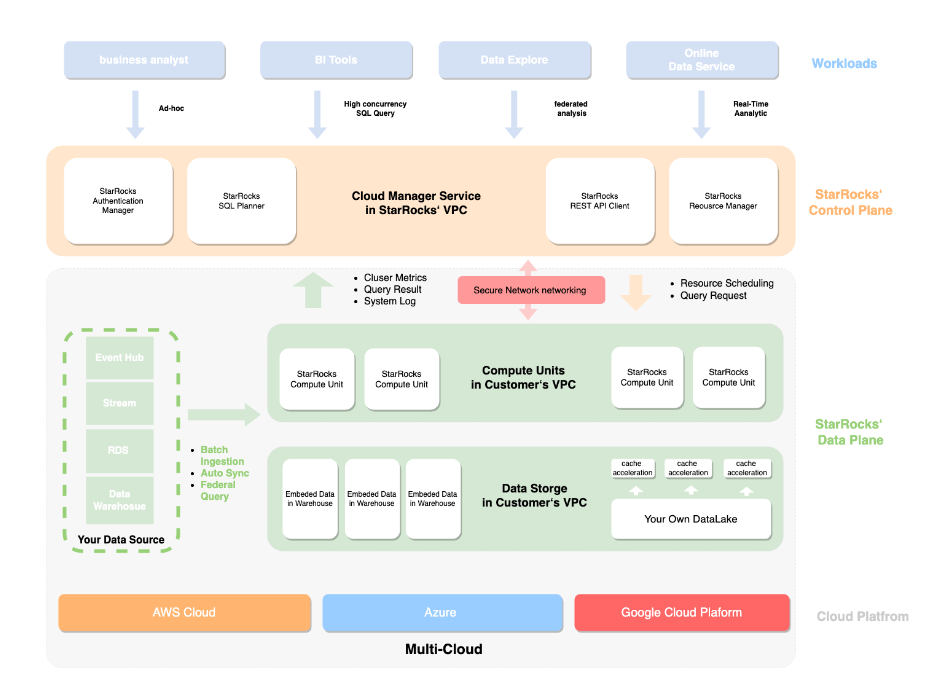
StarRocks architecture
The rise of real-time data flows via technologies like Apache Kafka has done much to help the transactional side of the house. However, real-time analytics hasn’t kept up, Kang says.
“And the main reason is, the technical infrastructure…just cannot meet a lot of the business requirements,” he says. “StarRocks was developed to address these challenges.”
StarRocks offers flexibility to query data in a number of ways. It can query star schemas directly with all the joins, and still deliver good performance, Kang says. “And for extreme use cases, if you still need to build a denormalized table, we can also give you better performance than our competitors,” he says.
It can also work directly data contained in S3, a la Presto, Trino, or Dremio. However, to achieve the best performance, the data must be ingested into the database’s proprietary format. StarRocks can ingest data at a rate of 100 MBps, Kang says.
However, the query performance utilizing star schemas is the most significant breakthrough from StarRocks, he says.
StarRocks can maintain a high level of query performance on star schemas even while data is being updated and changed, Kang says. StarRocks’ denormalized competitors can support about 10 to 100 concurrent users, he says, while StarRocks customers can run over 10,000 queries per second, representing tens of thousands of concurrent users.
This is not the type of OLAP system designed for business analysts to be submitting queries against from a Tableau or PowerBI front-end. “These types of applications usually are not for strategic decision making,” Kang says.
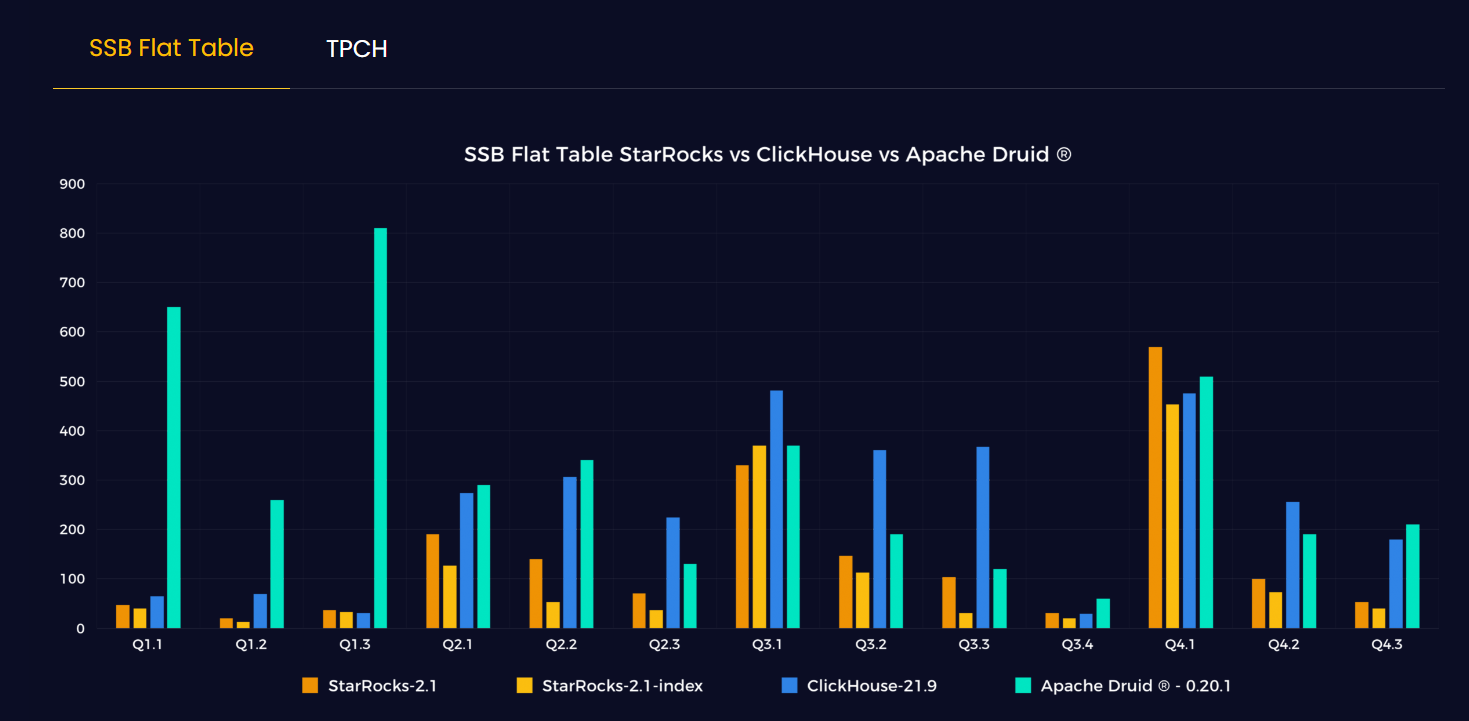
StarRocks outperformed ClickHouse and Druid on denormalized tables (Image courtesy StarRocks)
Instead, StarRocks is designed to automate large numbers of decisions that need to be made in close to real-time, such as ad placement or price adjustments, Kang says.
“So they need to support large number of concurrent users, maybe even end users or consumers themselves directly,” he says. “High concurrency is a key point.”
The company has run benchmarks to gauge StarRocks performance against denormalized competitors, like ClickHouse and Druid. “In the denormalized table queries, our performance was in the range of 2x to 3x faster than Druid and ClickHouse,” he says.
The company also benchmarked StarRocks against headless query engines that work on standard star schemas, like Presto, Trino, and Dremio. The company ran two sets of tests.
“If we bring data into our own storage engine–when we operate as a database–then the performance gain is 10x,” against Trino, Kang says. “If we leave data on the data lake, which is probably more of an apples-to-apples comparison to Trino because that’s how they operate–and query the data lake directly, in that scenario, we are 3x to 4x faster than Trino.”
While StarRocks in some ways is an amalgam of existing tech (Impala and Mesa) and plays well with other projects and products in the big data ecosystem (Kafka, Flink, etc.), it is not dependent on other products or frameworks to function. That results in a simplified, self-contained architecture that is easier to manage and scale.
“So it’s very easy for us to scale out, and we implement linear scalability,” Kang says. “The result is a reduced total cost of ownership.”
The new StarRocks Cloud further reduces the need for engineers to manage software or hardware. Running on AWS, StarRocks Cloud gives customers the option to ingest data directly into the StarRocks storage engine or query data directly from S3. But more importantly, engineers don’t have to worry about creating, maintaining, and scaling clusters.
The current StarRocks Cloud offering is a bring-your-own-cloud (BYOC) product. Customers brings StarRocks Cloud into their VPC, and StarRocks handles the scaling of its software. The company also plans to offer a multi-tenant cloud offering at some point in the future, Kang says.
For more info, check out www.starrocks.com.
Related Items:
Apache Doris Analytical Database Graduates from Apache Incubator
Speedy Column-Store ClickHouse Spins Out from Yandex, Raises $50M
Apache Druid Gets Multi-Stage Reporting Engine, Cloud Service from Imply
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States