

April 27, 2022
Aerospike Adds JSON Support, Preps for Fast, Multi-Modal Future

(cybrain/Shutterstock)
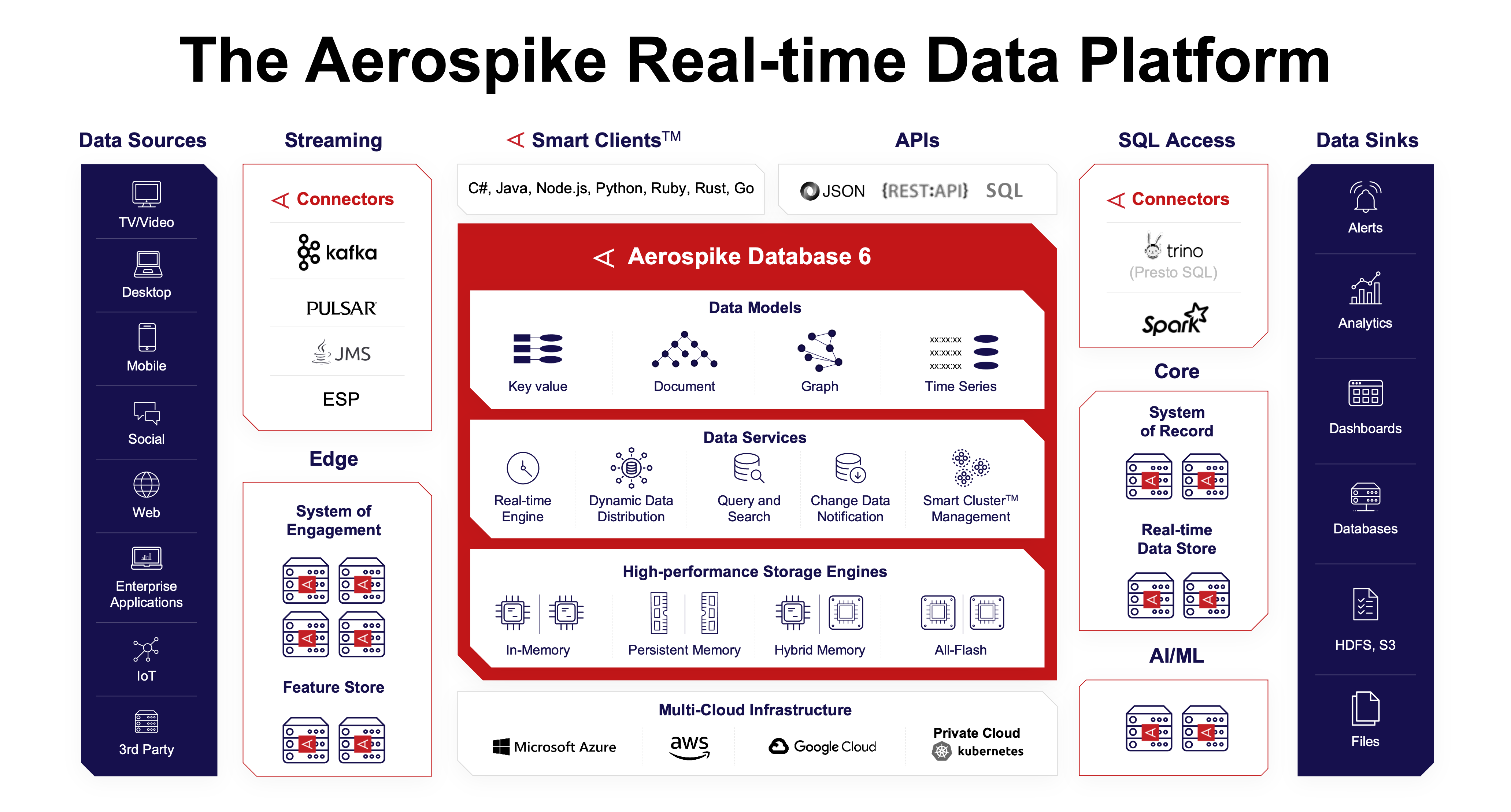
The addition of JSON support in Aerospike Database version 6 shows that Aerospike is not afraid to go head-to-head with bigger database vendors in the NoSQL market. The addition of performance enhancements to secondary indexes also helps. But the Silicon Valley has lot more in store for 2022 as it seeks to address its customers high-performance, real-time data needs, including the addition of graph and time-series libraries.
Support for JSON data types and JSONPath query will allow the Aerospike database to function more like the document stores that Web and mobile developers are selecting for new systems of engagement, namely those created by MongoDB as well as Couchbase.
“We’re [adopting] a document programming model that people are familiar with and they don’t have to think about,” says Lenley Hensarling, chief strategy officer for the Mountain View, California company. “That really just open doors for us.”
Aerospike previously could support its own document model within its key-value store as maps and lists, Hensarling tells Datanami. But it required a bit of additional work to map the JSON object to the database’s native API. By exposing another API that supports JSON and JSONPath query, developers can stay within the paradigm they’re comfortable with, and still get the performance benefit that Aerospike provides. And if needed, they can always drop down into the “native API” for maximum throughput, he adds.
“It has all the scalability and massive parallelism that we have in terms of connection models and in terms of throughput and operations on the server side,” Hensarling says of the JSON and JSONPath query work. “And so what this does is give them access to it without having to learn other things.”
Aerospike recently replaced a large document database in a cloud application that was not meeting the performance expectations of the customers, Hensarling says. “They just ran into a wall,” he says.
By supporting JSON documents in the way that programmers expect, it positions Aerospike as a potential alternative to MongoDB and Couchbase, as well as Datastax to a certain extent. The company hopes that JSON support, combined with Aerospike’s reputation as a fast, in-memory database, will give customers a reason to consider its database earlier on in the database selection process, Hensarling says.
“To some extent, we wind up being niched,” he says. “Now we’re seeing a lot more companies being smart about it because they’ve seen that happen. And they’re coming to us earlier and saying, hey, we’ve got something, we know it’s going scale to terabytes at least. The throughput is going to be high, maybe, eventually.”
Instead of changing out the database after the application has already been developed, which can be an involved project, these startup customers could invest in Aerospike as a sort of insurance plan against the company having difficulty scaling the database if the business plans really takes off, Hensarling says.
“With new tech companies, we call this aspirational scale,” he says. “There are use cases that could need millisecond response times. And the point being that they can just always do that. With Mongo, they’re stuck.”
Multi-Modal
The company is preparing to take more steps in its NoSQL database journey by making investments to eventually support additional data models, including graph data structures and a time-series library, Hensarling says.
“We’re going to be releasing some other things this year, around that…so supporting a time-series library,” he says. “We’re on the path and started investing resources in graph, and we have customers who are running graph at a scale that’s beyond what the other graph players are doing.”
(Image source: Aerospike)
Version 6 also delivers an enhancement to the secondary indexes. With this release, the performance of secondary indexes is just as fast as the primary indexes, Hensarling says.
“We really revamped our secondary indexes,” he says. “Trying to do secondary indexes scale efficiently and to have the same linearity in scale that we have with our primary index and key-value type model–we’ve been able to achieve that. So we can have secondary indexes on very large data sets and handle the very high throughput that we’re known for, and doing queries with those secondary indexes.”
Aerospike currently supports indexing the JSON documents, and in the next release, the company will support indexing down into the document “at any level,” Hensarling says.
Real-Time Data
Aerospike is positioning its database to be a vehicle for managing not just the static data that companies want to store, but also managing the needs of customers with lots of real-time data flows. Hensarling says the enhancements added to the database over the past few years–including cross data center replication and synchronous multi-site clustering–have bolstered customers’ ability to get data where it needs to be.
With the addition of JSON data types and time-series and graph in the future, it’s looking to build on those capabilities to expand what customers can do with real-time data, including machine learning and analytics, Hensarling says.![]()
“It is not just data that’s static, it’s handling that data as it happens and routing it to where it needs to go and being able to match data that comes in,” he says. “You’re essentially appending, appending, appending and then you get a pattern, and you say I want check that pattern, and you can match it against patterns that might be months of data, whereas in the past, because of that transaction time to pull that much data, you have mashed against weeks of data.”
In addition to serving as the primary transaction processing engine, Aerospike is also serving as the source or sink for data moving across message queues like Apache Kafka, Kinesis, and Pub/Sub. It has Apache Spark connections for processing the data using Spark SQL or Spark Streaming. And it’s also increasingly serving as a feature store for machine learning applications that data scientists want to keep updated with the freshest real-world data. It’s doing this in data center and at the edge.
“Databases used to be static. We used to have massive amounts of data that were static, we do a bunch of analysis and tell you what happened,” says Hensarling, who previously managed the JD Edwards EnterpriseOne ERP business for Oracle. “And now we’re actually watching data as it comes in, matching it against massive amounts of data and routing it to other places for machine learning, for different purposes and doing all of that as data occurs. And that’s a big change, because your context of the world is up to date, literally within seconds to milliseconds.”
Related Items:
Aerospike Turbocharges Spark ML Training with Pushdown Processing
Aerospike Delivers Multi-Site Clustering in DB 5
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States