

April 7, 2022
Monte Carlo Hits the Circuit Breaker on Bad Data

(Roman Zaiets/Shutterstock)
Data pipelines are critical conduits of information for data-driven companies. But what happens when the data in the pipeline becomes corrupted? In some situations, you want to immediately stop the flow of data, which is the goal of the new Circuit Breakers feature unveiled today by data observability firm Monte Carlo.
Monte Carlo is one of a group of data observability companies aiming to give customers the tools to inspect their real-time data flows with greater clarity. The company uses a variety of statistical methods to keep an eye out for bad data, which can be caused by a host of conditions, including data-entry and coding errors, malfunctioning sensors, and data drift.
Up to this point, Monte Carlo has functioned predominantly as an auditing tool to alert customers to bad data after it occurs, according to company co-founder and CTO Lior Gavish. But with Circuit Breakers, it is now giving customers the capability to take immediate action, he says.
“Monte Carlo has been sort of an after the fact solution, which is what we believe you should do in 99% of cases,” Gavish says. “But [Circuit Breakers] really helps you deal with the 1% of cases where letting bad data through is a detriment.”
For example, letting financial transactions go though with faulty data can have particularly bad consequences, Gavish says. So can sending company-wide communications based on bad data, or prominently presenting bad data as part of a high-stakes feature in a product.
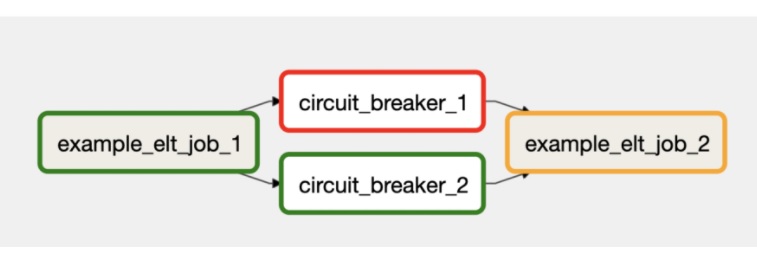
Monte Carlo’s Circuit Breakers let teams pause data pipelines when data quality checks are triggered at the orchestration layer (Image courtesy Monte Carlo)
“There’s a set of use cases in data where the cost of having bad data going forward to get processed is particularly high,” Gavish says. “In those cases, we’ve seen some of our customers want to essentially run validations or tests inline as data is generated and block the data from moving forward in the pipeline when it’s ‘wrong.’”
Circuit Breakers basically integrates the Monte Carlo validations and tests directly into customers’ own data pipelines. When the data values move past some pre-set limit determined by the customer, it triggers the “circuit breaker,” which immediately stops the data from moving through the pipeline.
The new feature is pre-integrated with a handful of ETL tools, the company says. Airflow is the most popular data orchestration tool used by Monte Carlo companies, Gavish says, but Matillion and dbt are also common. With a little bit of work, customers can integrate Circuit Breakers into any ETL tool that is able to execute a Python script, he says.
While customers could write their own circuit breaker, it’s not as easy as it looks, says Gavish, who adds that this was one of the most-requested functions from early Monte Carlo adopters.
“It might sound straightforward. ‘Oh, let’s just run some tests and stop the pipeline,’” he tells Datanami. “But there’s actually a lot of details [about] how to do it in a way that’s fault tolerant and that doesn’t break your pipeline for no reason. There’s a lot of intricacies around how to manage what happens when the pipeline breaks.”![]()
The Monte Carlo software provides more context around the erroneous data than what customers would likely be able to create on their own, Gavish says. Because this context is baked into the software, it can eliminate the need for a user to track down a data engineer to address the problem, he says.
As data pipelines proliferate, customers are finding them perhaps more difficult to manage than they had imagined. This is particularly true for companies that use multiple ELT pipelines to execute multiple transformations as they load data into a warehouse or data lake–or even once the data is loaded into the data warehouse or data lake, which is the case with customers using ELT processing.
“Most of our customers will essentially replicate data from the transactional system into let’s say Snowflake and on Snowflake start transforming it, aggregating it, and joining it to create further abstractions,” Gavish says. “We cover it from the replicated data all the way to the end product that people consume, through BI or other applications.”
Bad data can negatively impact a company’s reputation, but it can also carry a monetary cost, including the costs associated with the computing resource used to execute the data transformation, which will often need to be duplicated.
If a pipeline is churning out bad data for a week or a month, it’s often too difficult to reverse engineer the transformations. Instead, the transformation usually would be run again from the start, which can take a chunk out of a company’s computing budget.
It’s critical to catch the bad data as soon as possible, Gavish says. “If you can catch issues at step one rather than step 50, then you may have saved yourself a lot of trouble figuring out what needs to be regenerated and regenerating it, and making sure the bad datasets haven’t been used internally for various purposes while they were broken,” he says.
It can also reduce the cost of backfilling data. Optoro, a reverse logistics provider, is a Monte Carlo customer that is hoping to stem these costs with Circuit Breakers.
“With Monte Carlo’s Circuit Breakers, we can catch data downtime with Airflow at the orchestration layer, avoiding backfilling costs and preventing cascading data quality issues from affecting downstream dashboards or data science models,” Optoro’s Lead Data Engineer Patrick Campbell says in a press release. “With data observability, my team saves 44 hours each week that would otherwise be spent tackling broken data pipelines and responding to support tickets.”
Related Items:
Monte Carlo Launches ‘Insights’ for Operational Analytics
Inside AutoTrader UK’s Data Observability Pipeline
In Search of Data Observability
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States