

February 18, 2022
It’s About Time for InfluxData

(paitoon/Shutterstock)
These are heady times for InfluxDB, which is the world’s most popular time-series database, which has been the fastest growing category of databases the past two years, per DB-Engines.com. But when Paul Dix and his partner founded it a decade ago, the company behind the time-series database and the product itself and looked much different. In fact, InfluxDB went through several transformations to get to where it is today, mirroring the evolution of the time-series database category. And more change appears on the horizon.
Dix and Todd Persen co-founded Errplane, the predecessor to InfluxData, back in June 2012 with the idea of building a SaaS metrics and monitoring platform, à la Datadog or New Relic. The company had graduated Y Combinator’s winter 2013 class, attracted some seed funding, and had about 20 paying customers.
Getting the underlying technology right would be critical to Errplane’s success. Dix, who had worked with large-scale time-series data at a fintech company several years earlier, assessed the technology available at the time.
Of course, there were no shrink-wrapped time-series databases available at that time, and so he essentially built one from scratch using open source components. He used Apache Cassandra as the persistence layer, used Redis for the fast real-time indexing layer, wired it all up with Scala, and exposed as a Web service. That was version 1 of the Errplane backend.
By late 2013, Dix was well into version 2, which ran on-prem to differentiate Errplane from the morass of SaaS metrics and monitoring vendors suddenly hitting the market. He once again looked to the great toolbox known as open source for answers.

Paul Dix is the co-founder and CTO of InfluxData
“I picked up LevelDB, which was a storage engine that was written at Google initially by Jeff Dean and Sanjay Ghemawat, who are the two most awesome programmers that Google has ever seen,” Dix says. He wrote V2’s functions in a new language called Go, and exposed the functionality as a REST API.
While the product worked, it was becoming increasingly obvious that the company was struggling. “I said, ‘You know what, Errplane the app is not doing well. This is not going take off. We’re not going to hit escape velocity on this,” Dix says. “But I think there’s something here in the infrastructure.”
It turns out that Errplane’s customers were not so much interested in the server metrics and monitoring aspect of the product as much as the capability to handle large amounts of time-series data. His attention piqued, Dix attended a Monitorama Conference in Berlin, Germany that fall, which is when his suspicious were confirmed.
“What I saw was, from a back-end technology perspective, everybody was trying to solve the same problem,” Dix tells Datanami. “The people at the big companies were trying to roll their own stack. They were looking for a solution to store, query, and process time-series data at scale. It was the same with the vendors that we’re trying to build higher-level applications, which we were ourselves trying to do.”
‘Degenerate’ Use Cases
Time-series data, in and of itself, is nothing special. Any piece of data can be part of a time series just by virtue of having a timestamp. But the types of applications that make use of time-series data do have special attributes, and it’s these attributes that are driving demand for specialized databases to manage that time-series data.
As Dix sees it, applications that make extensive use of time-series data occupy a category that blends elements of OLAP and OLTP workloads, but fits entirely in neither.
“The real-time aspect makes it look kind of like the transactional workload, but the fact that it’s historical data that’s operating at scale and you’re doing a lot of analysis on it makes it look like an OLAP workload,” he says.
You could use a transactional database for time-series data, and people frequently do, Dix says. But scale quickly becomes a problem. “You’re inserting millions if not billions of new records every single day, even before you get really large scales,” he says.![]()
OLAP systems, such as column-oriented MPP databases and Hadoop-style systems, are designed to handle the large volume of time-series data, Dix says. But the tradeoff is that OLAP systems are not designed to deliver continuous real-time analytics on fresh data.
“They would have some period of time where you ingest the data and you convert it into a format that’s easier to query at scale and then you run the report once an hour or once a day,” Dix says.
Data eviction is another aspect of time-series data that demands special treatment. The value of time-series data typically goes down with time, and so to keep costs down, users typically will delete older time series.
“Now, in a transactional database, it’s not designed to essentially delete every single record you ever put into the database,” Dix says. “Most transactional databases are actually designed to keep data around forever. Like, you never want to lose it. So this idea of automatically evicting data as it is ages out is not something those databases are designed for.”
Because of these challenges, all of the big server metrics and monitoring companies eventually build their own proprietary time-series database, Dix says. “They’re not even using off-the-shelf databases anymore because of these different things that make time-series what I call like a ‘degenerate’ use case.”
Timely New Beginning
By 2015, Dix and his partner were ready to ditch Errplane and start selling the back-end as a time-series database. The good news was they were already ahead of the game, because they already had a database they could sell.
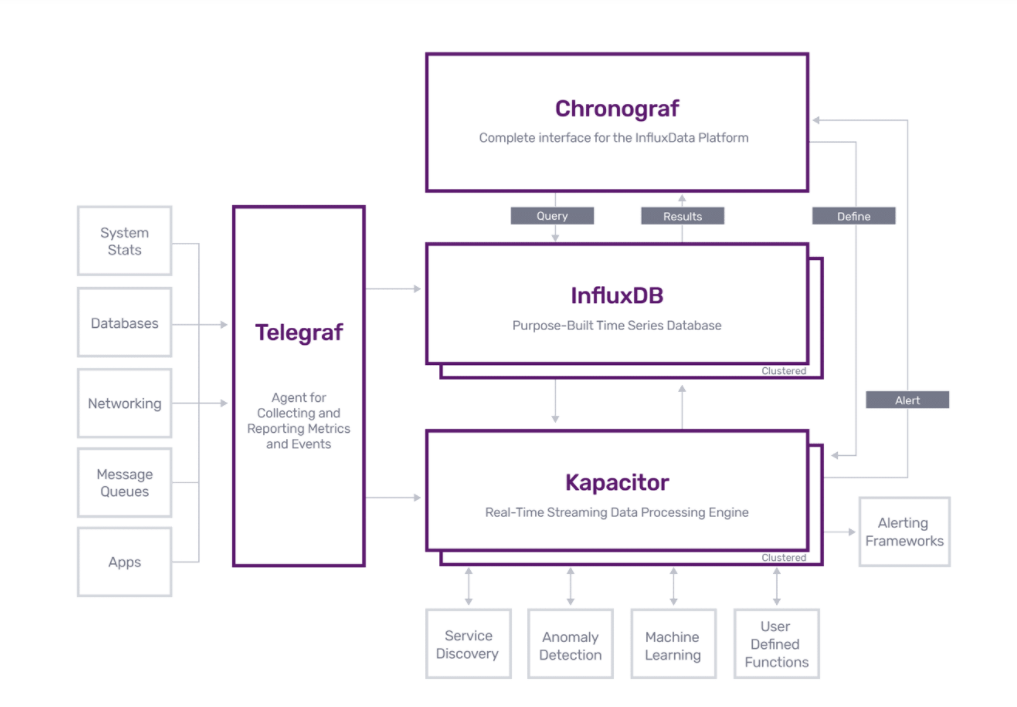
InfluxData’s TICK Platform
“When we released InfluxDB, there was immediate interest,” Dix says. “It was obvious that we were onto something right away. Developers have this problem, and they needed this technology to solve it. How do you store and query time series data? Not just at scale, but how do you do it easily, even at lower scale?”
InfluxDB didn’t need a whole lot of work to get off the ground. The biggest difference between that initial version and the Errplane V2 backend was the need for a query language, which Dix likened to “syntactic sugar” sprinkled on top. That came in the form of a SQL-like language that users could write queries in (as opposed to just using the REST API) called InfluxQL.
But the work was not done. InfluxData raised some additional funding and began developing a new version of the database, as well as surrounding tools (ETL, visualization, alerting) that would eventually become part of the TICK platform.
Dix also set out to rebuild the database, and InfluxDB 1.0 debuted in September 2016.
“That version of InfluxDB, we built our own storage engine from scratch,” Dix explains. “It was heavily influenced by LevelDB and that kind of design. But we called it the time-series merge tree. LevelDB is called a leveled merge tree. So we had our own storage engine for it, but still everything else was Go and that was the open source piece.”
Open to the Cloud
InfluxData shares the source code for its InfluxDB database under the MIT license, allowing anybody to pick up the code and run with it. The San Francisco company also developed a cloud offering on AWS, giving customers a fully managed experience for time-series data. It also developed a closed source version that’s distributed for high availability and scale-out clustering.
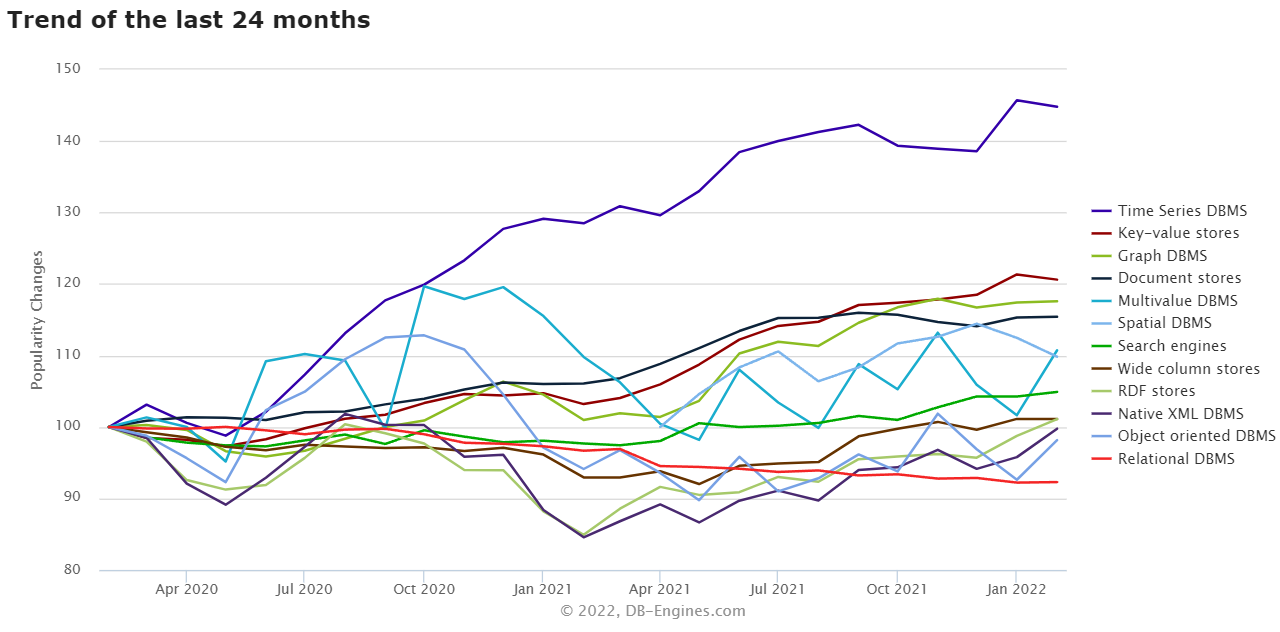
Time-series databases have grown faster than any other database type over the past two years, according to DB-Engines.com
Meanwhile, InfluxData’s platform aspirations were growing. Launched in 2018, TICK was composed of four pieces: a data collector called Telegraf; the InfuxDB database itself; the visualization tool Chronograf; and the processing engine Kapacitor.
“We wanted to figure out a way to tie the four different components together in a more meaningful way, where they have a single unified language,” Dix says, which was addressed with a new language called Flux. “The other thing we wanted to do was to shift to a cloud-first delivery model.”
While the majority of InfluxData’s customers at that time were on-prem, Dix told the development team that he wanted to be able to push out updates to any piece of the platform on any day of the year. The transition was complete in 2019, and today the cloud represents the fastest growing component of InfluxData’s business.
This week, InfluxData unveiled several new features designed to help customers process data from the Internet of Things (IoT), including better replication from the edge to a centralized instance of InfluxDB Cloud; support for MQTT in Telegraf; and better management of data payloads via Flux.
There is also another rewrite of the core underling technology for InfluxDB looming in the near future.
“The big thing that I’m personally focused on, that I’m excited about, is we’re basically building out a new core of the storage technology and that’s going to be replacing everything within a cloud environment this year,” Dix says. “In this case, it’s written in Rust, whereas almost all of our other stuff is written in Go. Now it uses Apache Arrow extensively.”
The use of Arrow will provide a significant speedup for InfluxDB queries, as well as the ability to query larger data sets, Dix says. The company will also be adding the ability to query the database using good old SQL. It will also be augmenting its Flux language (which is used for defining background processing tasks) with the addition of Python and JavaScript, he says.
While InfluxDB has a hefty head start in the time-series database category, per DB-Engines.com, the category as a whole is fairly young and still in the growing phase. For Dix, that means the opportunities for new use cases are wide and growing.
“For me, the key insight around creating InfluxDB was that time-series was a useful abstraction to solve problems in a bunch of different domains,” he says. “Server monitoring is one, user analytics is another. Financial market data, sensor data, business intelligence–the list goes on.”
When you add things like IoT and machine learning, the potential opportunities for time-series analysis grow even bigger. How big will it eventually be? Only time will tell.
Related Items:
How Time Series Data Fuels Summer Pastimes
IT Researchers Tackle Time Series Anomalies with Generative Adversarial Networks
Time-Series Leader InfluxData Raises More Cash
Applications:
Data Mining
Vendors:
InfluxData
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States