

February 4, 2022
Graviti Seeks to Corral Unstructured Data for AI

(tookitook/Shutterstock)
In many ways, unstructured data is the bane of the modern data collector. Compared to the svelte nature of structured data, such as numbers safely ensconced in a database, unstructured data like words and pictures are big, chaotic, and difficult to work with. But one company that sees a path through the chaos of unstructured data management is a startup called Graviti.
Managing the lifecycle of unstructured data–which at its most basic form amounts to words and pictures–can be very challenging. The data is bulky, its value murky, and it resists the type of natural categorization that structured data lends itself to. It’s no wonder that an executive at expert.ai recently dubbed unstructured data “the white whale of the business world.” This stuff is hard to work with.
Despite the difficulty of unstructured data, Ahabs abound in the real world, as companies ramp up their collection of unstructured data. One good reason for that is that unstructured data accounts for the vast bulk of new data being generated. According to IDC, 80% of global data generated by 2025 will be unstructured.
Another reason for the interest in unstructured data is AI. Advances in deep learning technology, such as natural language processing (NLP) and computer vision models, specifically target unstructured data types as the fuel for their training. AI adoption is projected to increase markedly in the months and years to come, largely because of the availability of unstructured data for AI model training, as well as the democratization of the AI tools themselves.
One technologist who knows the challenges and rewards of unstructured data is Edward Cui. Before founding Graviti in 2019, Cui was a tech lead and machine learning engineer for Uber, where he worked with the huge stockpile of unstructured data pulled from sensors on self-driving cars.
The sheer volume of unstructured data gathered from Uber’s self-driving car sensors was nearly unfathomable. “We did a statistic that showed the amount of data we collected in a self-driving car division for a week was equal to the data for the entire restaurant business globally for an entire year,” Cui says.![]()
Uber is a sizable company, but even it struggled with the compute necessary to manage the data. What was missing from the equation, Cui says, was a platform that automated many of the mundane tasks involved in unstructured data lifecycle management and downstream AI tasks.
“We’ve tried to develop the infrastructure to manage unstructured data internally, but it is very expensive and takes time,” Cui tells Datanami. “As the self-driving industry exploded, the problem of redundant unstructured data was more significant for AI developers, and it was a key barrier in the entire AI industry. The challenge prompted me to build the Graviti Data Platform, which is a modern data infrastructure designed for unstructured data at scale.”
Graviti, which came out of stealth a week ago, aims to address some of the big challenges that data scientists and AI engineers face in using unstructured data to train machine learning algorithms. The Graviti platform, which is based on S3 and runs in the AWS cloud, helps automate the processes required to manage the data efficiently and get value out of it.
The industry need is there. A survey by Graviti found that 25% of AI researchers spend from half to two-thirds of their time in curating unstructured data, including collecting, cleansing, selecting and exploring data. Nearly all the developers who participated in the survey said their current method of managing unstructured data falls short.
Gravit’s core goal with the Graviti Data Platform is to reduce the amount of time users spend doing the drudge work of managing data, freeing them to spend more time developing models, which is what AI developers ultimately want to do.
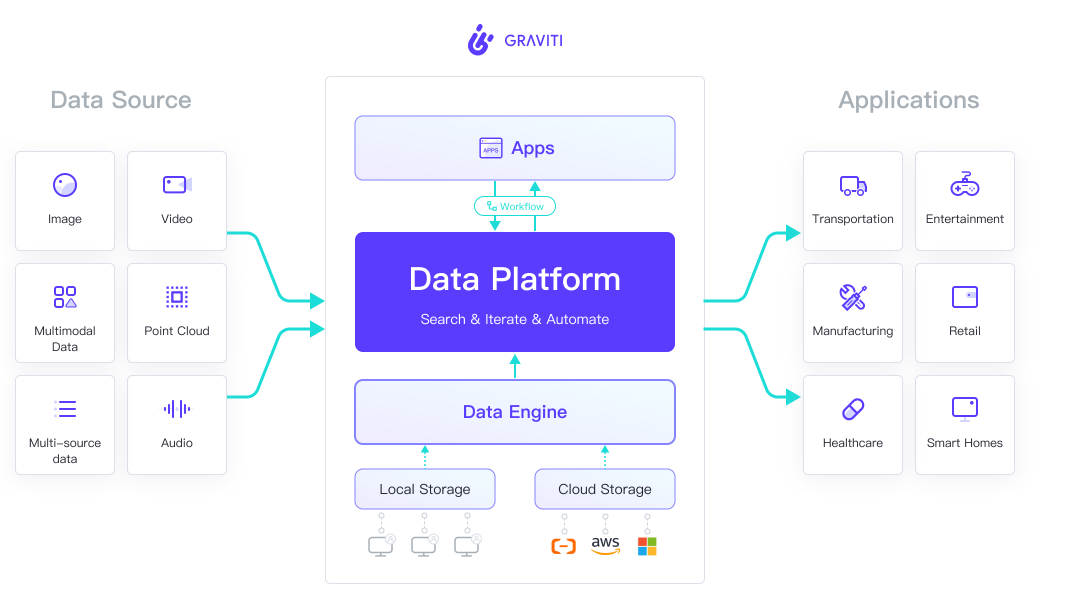
The Graviti Data Platform
It all starts with helping to identify valuable data. The software also manages metadata associated with the source data, annotations (like labels), and predictions in one place. Users have filters that allow them to help them find the best data that matches their needs. As they work with data, a Git-like version control system tracks their usage, enabling teams to work more efficiently, the company says. The platform also brings automation to data pipelines created for model training.
“Data version control, data visualization, and team collaboration are our key product features that help engineering teams to increase their productivity in data management and model training,” Cui explains. “The platform adopted a Git-like structure for managing data versions and collaborating across teams. Role-based access control and visualization of version differences allow your team to work together safely and flexibly. The end result is that Graviti liberates developers from chores, and they can now spend more time analyzing unstructured data and training models.”
The New York company has raised $12 million in a pre-Series-A round. It counts Motional, Alibaba Cloud, and AWS as customers. For more information, see www.graviti.com.
Related Items:
Taming the ‘White Whale’ of Unstructured Data
Big Growth Forecasted for Big Data
Unstructured Data Growth Wearing Holes in IT Budgets
Applications:
Artificial Intelligence
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States