

August 13, 2021
Kinks in the Data Supply Chain

(Iaroslav Neliubov/Shutterstock)
It goes without saying that having a good data supply chain is instrumental in being a data-driven organization. Without a smooth and repeatable process for acquiring, validating, and preparing data for downstream consumption, organizations don’t have much hope in achieving their data-driven goals. Unfortunately, new research suggests sizable constraints are emerging in organization’s data supply chains.
The research comes in the form of a 451 Research report titled “DataOps Dilemma: Survey Reveals Gap in the Data Supply Chain.” Commissioned by Immuta, the survey, which was unveiled earlier this week, reveals that many organizations are struggling to balance competing needs when it comes to data operations.
The survey, which involved 525 enterprise practitioners in the US, Canada, UK, Germany and France and was written by Senior Research Analyst Paige Bartley, looked at various aspects of data culture in organizations today. The survey concluded, not surprisingly, that data is playing an increasingly important role.
For example, the survey found that 71% of respondents agreed that data will become more important to their organization’s decision-making in the future. A similar percentage (72%) said that the number of data consumers in their organizations is steadily increasing. Clearly, organizations are buying into the need to use data as a competitive differentiator, if not a means for basic survival.
But it’s not all puppies and rainbows in data-land, according to 451 Research, which pointed to three main sources of the data supply chain problems.
For starters, industry regulations such as GDPR and HIPAA, while important for protecting the privacy of sensitive personal data, are also taking their toll on the data keepers and their downstream customers.
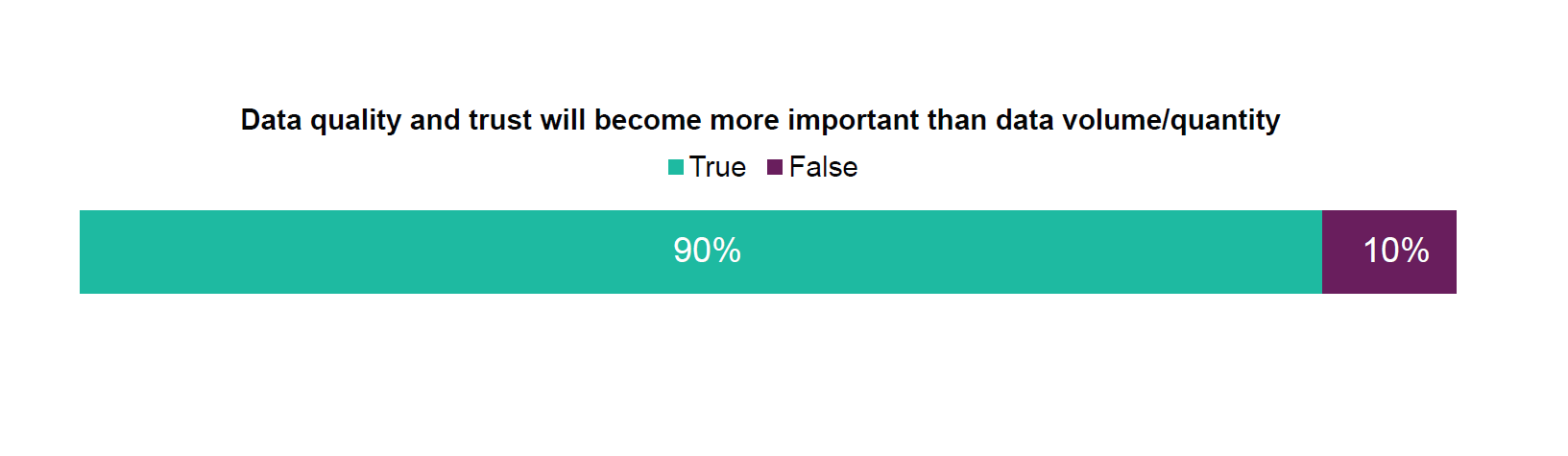
Data quality is valued more heavily than data quantity by a 9 to 1 margin, according to a recent 451 Research survey (Source: 451 Research)
451 Research found that 84% of survey respondents believe data privacy and security requirements “will limit access to data at their organizations” over the next 24 months. Slightly more respondents (86%) say that it’s true that “security and privacy rules [are] making it harder to access and use data,” the report says.
Secondly, a skills shortage among people threatens to disrupt upstream supplies of good quality data to downstream consumers, including people and applications.
451 Research found that 38% of folks in the data supplier role cited a lack of skills as the biggest challenge or pain points. That hints at an important change in the makeup of the data team, according to Bartley.
“Often, the skills discussion in organizations is focused on the data ‘consumer’ side of the equation, with emphasis on employee data literacy programs and ease of use for self-service software such as data visualization tools,” she writes. “However, as the number of trained data consumers grows and data visualization tools become easier to use, the tide seems to have turned. Now, the traditionally more technical data ‘supplier’ roles are falling behind the consumer demand.”
Lastly, the report cites a lack of automation at the technological and process levels are hampering the ability of the overworked staff to keep up with the building demands placed on the data supply chain.
Too much complexity, various bottlenecks, a lack of real-time streaming, and a general lack of automation were cited as by 29% or more of data engineers, architects, and developers, the survey found.
Bartley pointed at one unexpected culprit as hurting the data supply chain: self-service business models. Apparently, self-service programs may not be the panacea that they are often made out to be.
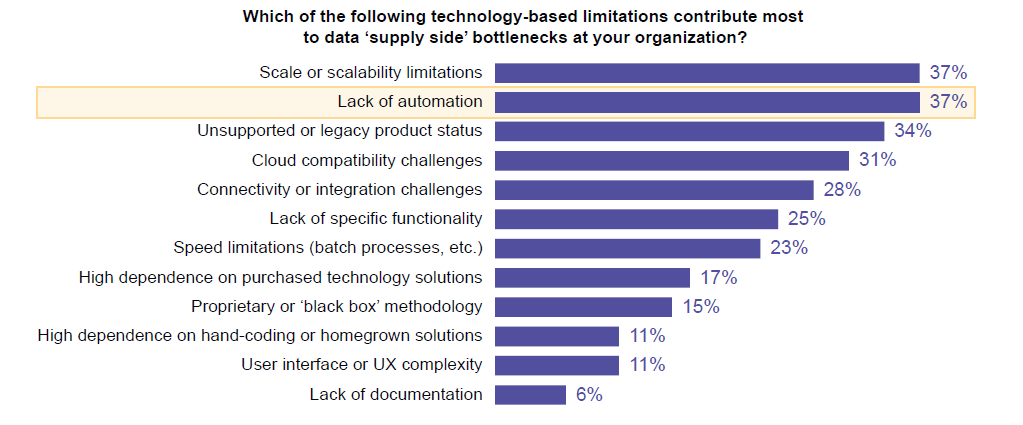
The most commonly cited supply-side data bottlenecks (Courtesy 451 Research)
“Simply put, self-service models are difficult to support when there are points of friction or gaps in the data supply chain,” she writes in the report. “Overall, less than half (48%) of survey respondents either ‘somewhat’ or ‘completely’ agreed that their organization provides self-service data access and use.”
So, what are the impacts of all these challenges on the data supply chain? A big one is the timeliness of the data, the survey suggests.
Data is often out of date by the time it’s used, according to 63% of data scientists and data analysts who took the survey. However, when viewed through the lens of upstream data providers, only 55% of the total number of users who took the survey agreed with that statement, suggesting that data engineers, architects, and developers are not as pessimistic about the data timeliness as users on the sharper end of the data stick. (Or perhaps they’re just out of touch with what is actually happening on the ground.)
451 collected more evidence of a divergence in perception about who’s responsible for the data shortcomings. Data suppliers, who bear the brunt of constant requests for data from data consumers are more sensitive to perceived frustration, Bartley writes.
“While 62% of respondents who self-identified as data suppliers either ‘somewhat’ or ‘completely’ agreed that data consumers in their organization express frustration in their attempts to access use data, only 24% of those who self-identified as data consumers agreed,” she writes in the report. “Data consumers simply may not be aware of the levels of frustration they are conveying to data suppliers, who are already stretched thin and working amid teams suffering from skills shortages.”
Regardless of who’s to blame for the data pain, all of the data players in organizations appear to recognize that that the team as a whole is not working as well as it could.

There is significant spread in self-report DataOps maturity (Source: 451 Research)
When asked to measure themselves on a DataOps maturity curve, the spread was more or less as you would expect. Only 10% of respondents put themselves at the top of the class, in the “optimized” category, where “DataOps is ingrained into the company culture. At the same time, only 5% put themselves at the bottom of the class, the “low maturity” phase where “no DataOps strategy [is] in place.” The vast majority placed themselves in the middle at various stages of nascent, emerging, and accelerated steps on the maturity curve. (451 did not provide the splits for producers/consumers, which would have been interesting.)
Clearly, there is room for improvement in the data supply chain. Having a chief data officer (CDO) is taken as an indication that an organization is serious about tackling its data supply chain challenges, although the different types of CDO (tactical versus strategic) also appear to correlate with eventual success.
At the end of the day, the its up to each individual organization to assess where they lie on the DataOps maturity curve, and what steps they can do to improve their data supply chain. One clear step that nearly all organizations can take is to invest in the upstream data providers and the processes they support, i.e. the data engineers, data architects, and data developers, as well as the technologies, tools, and processes they need to achieve greater automation.
For a full copy of the 451 Research report, click here. Immuta and 451 Research will also be discussing this report during a webinar on August 31 at 1 p.m. ET.
Related Items:
Demand for Data Engineers Up 50%, Report Says
Data Science Needs to Grow Up, Domino Says
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States