

October 27, 2020
Did Dremio Just Make Data Warehouses Obsolete?

(Timofeev-Vladimir/Shutterstock)
Imagine that your users can query a cloud object store from their favorite BI tools, and get responses back in less than a second. Would you still pay for a dedicated cloud data warehouse at that point? According to Dremio, which just announced this new capability, in most cases the answer is a clear “no.”
Dremio today announced its Fall 2020 release, which brings the capability referenced above. Users can now query data sitting in Amazon’s S3 and Microsoft’s ADLS directly from a BI tool like Looker, Tableau, or PowerBI. And thanks to Dremio’s middleware, the queries will exhibit the same performance characteristics as if they were running on a dedicated data warehouse, such as RedShift or Snowflake.
“We are basically enabling companies to run their production BI directly on cloud data lake storage, so they no longer have to move the data from those systems into a data warehouse,” says Tomer Shiran, the co-founder and chief product officer of Dremio. “You’re actually getting faster performance at a much, much lower total cost.”
One of the primary reasons companies use data warehouses is to power production BI workloads. Picture a large financial services firm employing a few thousand analysts to sit at workstations and submit complex SQL queries that drive reports and dashboards. This is what drove companies like Teradata to develop specialized column-oriented relational databases that feature query planners and other inventions to cope with these demanding, at-scale workloads.
When data started flowing en masse to the cloud, those analytic data warehouses followed. Enterprises turned to a new generation of cloud data warehouses, such as Amazon RedShift (based on ParAccel), Microsoft Synapse, and Snowflake to leverage the massive computing capacity of the cloud to power massively concurrent SQL analytic workloads on huge data sets flowing into cloud data storage.
Apache Arrow is being used for caching data in Dremio (Image courtesy Dremio)
The new generation of cloud data warehouses addressed several shortcomings with the on-prem systems they were replacing. But it couldn’t get away from one big shortcoming: The need to move data from the cloud object storage system into data warehouse itself, where specialized storage formats could deliver the query performance that users were expecting.
By enabling SQL queries to run directly against the data stored in S3 and ADLS without a drop-off in performance, Dremio is essentially bypassing the data warehouses and the ETL and data engineering that is required to move data from object stores into data warehouses.
“Nobody wants to move the data. You only move it if you have to,” Shiran says. “It’s expensive. It’s slow. It adds latency to the overall workflow. If we can enable that query directly at the speed that people need, there will be no reason to move that data somewhere else.”
Prior to this release, Dremio’s software already supported ad hoc exploratory queries of data directly on S3 and ALDS. In this scenario, queries could take up to a minute to run. In Dremio’s case, it took a bit of software engineering for Dremio to build the structures necessary to power production BI (i.e. sub-second response tiem) at enterprise scale (i.e. thousands of concurrent users).
According to Shiran, there were three new architectural elements that enabled Dremio to do this, along with one component that already existed, the Reflections, which are pre-aggregations of the data.
The first new thing was caching data in the Apache Arrow format. The company employs the creators of Arrow, the in-memory data format, and it uses Arrow for in the computation engine. But Dremio was not using Arrow to accelerate queries. Instead, it used the Apache Parquet file format to build caches. However, because it’s an on-disk format, Parquet is much slower than Arrow.
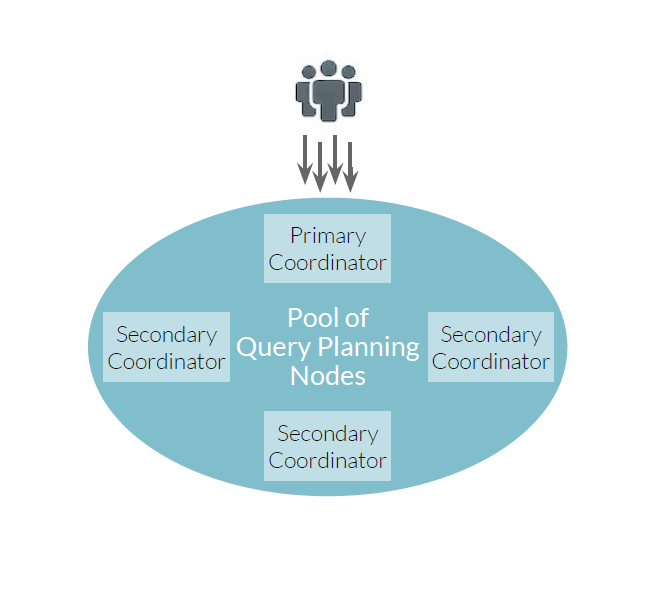
Dremio now supports an unlimited number of scale-out query coordinators (Image courtesy Dremio)
“In the past, we’d create Reflections in Parquet files, but when we wanted to use those Reflections to accelerate a query, we’d have to convert that Reflection from Parquet into the Arrow format,” Shiran says. “That conversion itself is a bunch of compute work, to deserialize and decompress the data, and that adds seconds to the query.”
Using the Arrow format in the Reflections pre-sorts boosts query response times by 10x in many cases, Shiran says.
The second new thing that Dremio had to build was scale-out query planning. This advance enabled the massive concurrency that the biggest enterprise BI shops demand of their data warehouses.
“Traditionally in the world of big data, people had lots of nodes to support big data sets, but they didn’t have lots of nodes to support concurrency,” Shiran says. “We now scale out our query planning and execution separately.”
By enabling an arbitrary number of query planning coordinators in the Dremio cluster to go along with an arbitrary number of query executors, the software can now support deployments involving thousands of concurrent users.
The third new element Dremio is bringing to the data lake is runtime filtering. By being smart about what database tables queries actually end up accessing during the course of execution, Dremio can eliminate the need to perform massive table scans on data that has no bearing on the results of the query.
For example, say the query is filtering on the city name. As that query starts running, the query engine is going to figure out that, when we look for “city name equals Mountain View,” it turns out there are only two cities with that name, Shiran says.
“So we can then send that information to the processes that are scanning the big table, in an adaptive way, and say ‘Hey, stop reading every record from the big table. We don’t need those anymore. We just need the ones that have city ID equals 34.’ Then we can skip all the other partitions in the other [Parquet] pages to get faster response.”
Runtime filtering also helps boost query response time in Dremio’s Fall 2020 release (Image courtesy Dremio)
These types of situation cannot be resolved in the query planner ahead of time, so the system must be smart enough to adapt to what the query is returning. “This really plays a big role when you’re thinking about system like S3 where the data might be coming remotely,” Shiran says. “How much data can I read is actually a very important factor.”
The writing is on the wall regarding where customers want to put their data. The cost, availability, and scalability advantages of object stores are leading them to be the dominant place where companies store data, Shiran says, so it makes sense that it should be queried from there too.
“That has become where all data lands,” he says. “I think the future is that every company will want to have an open data lake architecture, instead of a proprietary monolithic data warehouse.”
That doesn’t mean that data warehouses are completely obsolete, Shiran says. For starters, people are far more familiar with data warehouses than they are with other methods of accessing data remotely from object stores, using something like Dremio or other competing options, like Presto and Hive. The other use case where data warehouses still hold a technical advantage is in transactional systems.
“They’re not obsolete yet,” Shiran says diplomatically. “For [transaction] types of use cases, it still makes sense use a data warehouse. You’re frequenting mutating and updating existing record and things like that.”
But over time, even those transactional advantages will begin to disappear, he says.
Related Items:
Dremio Preps for Growth with $70M in the Bank
Dremio Noses Into Cloud Lakes with Analytics Speedup
Dremio Fleshes Out Data Platform
Applications:
Enterprise Analytics
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States