

September 17, 2019
Dremio Noses Into Cloud Lakes with Analytics Speedup

Most of today’s big data action is occurring in the cloud, where companies are building massive data lakes atop object storage systems like AWS S3 and Microsoft ADLS. While object stores offer tremendous scalability, they’re notoriously slow. Those who are tired with slow responses may want to check out the latest from Dremio, which today unveiled some innovative ways to speed SQL queries on the cloud.
The original design point for Dremio — which is based on the open-source, in-memory, columnar data format called Apache Arrow — was to make it easier for data scientists and analysts to join and query data located in multiple locations (HDFS, cloud, databases, etc.). By leaving the data where it originally resides and providing a semantic data access layer atop it, Dremio could effectively provide the benefits of a data warehouse without the time, expense, and complexity of engineering ETL scripts and data warehouse assembly.
As the technology has been adopted (4 million weekly downloads of Arrow, per Dremio), the use case has changed slightly, at least for Dremio. Instead of just giving customers access to the data, customers want the Dremio software to execute with the same level of performance that they’ve grown accustomed to with traditional data warehouses, such as Teradata, Amazon Redshift, and Snowflake.
That’s a challenge when working on S3 and ADLS, says Dremio CEO and co-founder Tomer Shiran. “Those systems have much higher latency then what you can get from local storage,” he says. “People are used to using NVMe or their local system or using an all flash array. They’re used to much, much higher performance then what you can get from these systems.”
Dremio 4.0 was developed to accelerate SQL queries in the cloud
Dremio addressed the data-serving shortcoming of S3 and ADLS with the new columnar cloud cache (C3) and predictive pipelining features in Dremio version 4.0, which was unveiled today.
The new columnar cache feature accelerates queries by automatically caching bits and pieces of data that’s being accessed through Dremio from S3 for the first time. Dremio actually caches it in an NVMe drive that is local to the cloud cluster on which Dremio is running in AWS or Azure, Shiran says.
“So the second time a piece of data is accessed, it’s cached locally,” he says. “What we found is that on average most pieces of data are accessed tens of times. So this gives us an average of 10x [performance] improvement across the system.”
But that wasn’t enough. To accelerate performance the first time a user requests a given piece of data from S3 or ADLS, Dremio developed its predictive pipelining feature. This new feature anticipates which piece of data a user is likely to access next, and prepares it for analysis in the Dremio query engine.
The predictive pipeline is column-aware, and request a column-oriented data format, such as Parquet or ORC, to work. Shiran explains how it works:
“We can predict what the next piece of data will be, what the query engine will read, based on the pattern of that query, which columns are begin accessed, and so forth,” he said. “This new predictive pipeline technology is all about pre-fetching data, one second in advance, so that we’re never sitting there idle, waiting for data sets to come back from S3 [and ADLS].”
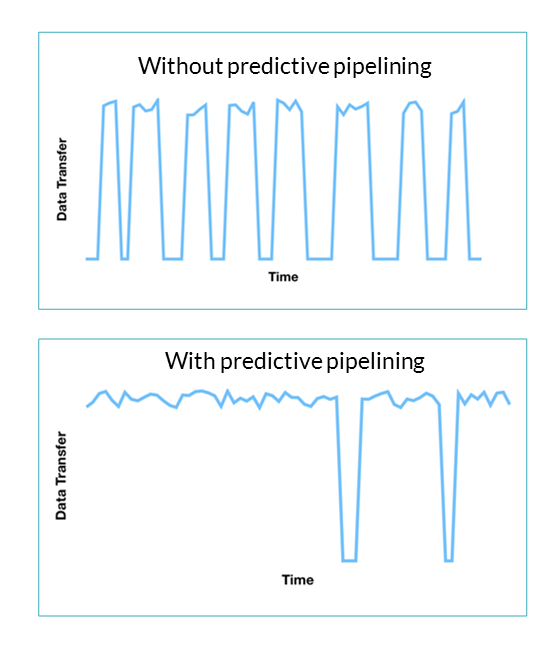
Dremio 4.0’s predictive pipelining helps to smooth out data access patterns and make more use of the cloud’s network capacity
The end result of all this is the delivery of a “no ETL” data warehousing solution, Shiran says.
“We’re eliminating the need for Redshift,” he says. “Dreamio is really an alternative for a data warehouse where you don’t have to load the data and move it and copy it and all that. The only way this can be possible is if you can query the data where it lives and provide the same performance that you can get with something like Redshift or Snowflake or Teradata or one of those systems that require you to load the data in advance.”
Because the public clouds have grown so popular lately, Dremio also worked to bolster security aspects of how its software runs in the clouds. The company has hooked into the native security services that these clouds use, such as Active Directory, including integrating with single sign on (SSO) functions to simplify the log-on process.
It also unveiled the Dremio Hub, which is a clearinghouse where customers can get native connectors. The company is offering connectors for Snowflake, Salesforce, and several other data sources. Third-parties are also free to offer their own connectors. The Santa Clara, California company also recently named Datastax co-founder Billy Bosworth to its board. Bosworth also sits on the board of Tableau.
Related Items:
Dremio Fleshes Out Data Platform
Cisco Backs Data Startup Dremio
Dremio Emerges from Stealth with Multi-Threat Middleware
Applications:
Data Mining
Technologies:
Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States