

February 25, 2020
Real-Time Data Streaming, Kafka and Analytics, Part 2: Going Beyond Pure Streaming

(Sur/Shutterstock)
Data transaction streaming is managed through many platforms, with one of the most common being Apache Kafka. In our first article in this data streaming series, we delved into the definition of data transaction and streaming and why it is critical to manage information in real-time for the most accurate analytics. As more individuals increase their data literacy and use data to make business decisions, real-time data is becoming a critical factor. To handle this effectively, companies are implementing modern data architectures that can support this real-time requirement, including change data capture (CDC) and Apache Kafka as their streaming platform components of choice.
Apache Kafka is a strong choice to handle real-time data streaming as it ingests, persists and presents streams of data for consumption and use by individuals for analytics. Basically, Kafka operates through three basic components to move data in real-time: producers, brokers and consumers. The producer is a process that writes or sends the data to Kafka. It is then sent along to the Kafka broker, which runs the process and responds to requests from products and consumers. Finally, the consumer is the end process – an application program that reads the records at the end of the stream.
Now, what makes Apache Kafka so powerful with the change data capture (CDC) technology that we referenced in Part 1 is that it can scale with multiple topics and data. This allows for the ingestion and delivery of high-volume CDC data from a variety of sources simultaneously – and it does it in the order in which all the changes happened for pure data integrity. In this part of the series, we will dive deeper into how this data ingestion process works along with data integration through CDC technology.
How It Works: Ingesting and Integrating Data into Apache Kafka
Traditional data ingestion and integration happens through the ELT (Extract, Load and Transform) processes, where data is extracted with CDC, loaded into the analytical target system and then transformed. With the rise of big data, ELT has quickly caught on and Apache Kafka can be used to ingest and move this data in the pipeline. As mentioned above, it would work as data is read and written from various databases using Kafka’s producers and consumers.

(pixelparticle/Shutterstock)
The beauty of the Kafka platform for data ingestion and integration is that its highly efficient thanks to its low latency, high availability and persistence – all key requirements for real-time data integration. There are two methods that companies can select to do this integration.
- Kafka Connect: This is an open-source component that supports connections to common databases. Uses cases may include database ingestion, application server metrics and database extraction processes. Connect allows for these workflows to be processed incrementally, in near real-time or in batches. The benefits for using Kafka Connect are easily moving data into and out of Kafka, and building high-performance data integration pipelines. The challenge to this structure is that it requires the creation of connectors to external sources and targets. These connectors may involve development time initially, or services from a third-party vendor.
- CDC: This method allows for the tracking, capturing and delivering of changes for source data sets by replicating changes with little to no impact on the source. CDC is fast becoming the most widely used method of publishing database records to Apache Kafka. This is due to its ability to support multiple architectural patterns or data sources for integration. Companies are using CDC and Kafka to enable data lake integration, microservices, NoSQL database connections and streaming-first architectures.
Marrying CDC Processes with Apache Kafka
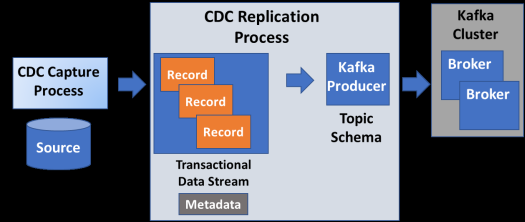
Data optimization throughput and consistency are the two main goals of a streaming platform in modern data architectures. And since CDC is the more commonly used method for data ingestion and integration with Kafka, let’s look further at how it works and the main functions that happen in this process: capturing and replicating changed data.
Companies can select from a number of CDC technologies and vendors to create their data transaction stream. These solutions will replicate the data between the CDC system and Kafka producers. Solutions that automate this replication will create greater efficiencies and simplify overall data management. One key to creating effective transaction pipelines is ensuring source metadata can be injected into Kafka streams.
When the CDC data schemas and metadata are aligned, there is greater throughput and low latency. Additionally, companies can elect to use optimized schema serializers such as Apache Avro or schema registries to increase consistency in the streaming pipeline and record control. The best practice is to have the CDC solution publish database changes as a Kafka stream to replicate records to analytics and microservices platforms.
What’s Next?
In our final article, we will examine how to best plan for the implementation of CDC technology alongside Apache Kafka for ideal real-time data transaction streaming. It will bring the conclusion to the series by also outlining the benefits companies will receive from these modern data architectures and help to drive greater data literacy internally.
If you are interested in more details on transaction data streaming along with suggestions on how to best implement Apache Kafka, and create organized data streams with CDC, there is a free Dummies book, Apache Kafka Transaction Data Streaming for Dummies, that provides greater detail.

Dan Potter
About the authors: Thornton Craig, a senior technical manager with Amazon Web Services, has spent more than 20 years in the industry, and previously served as research director at Gartner. Dan Potter, the vice president of product marketing at Qlik (formerly Attunity), also has 30 years experience in the field, and is currently responsible for product marketing and go-to-market strategies related to modern data architectures, data integration, and DataOps. Tim Berglund, the senior director of developer experience at Confluent, is a teacher, author, and technology leader.
Related Items:
Real-Time Data Streaming, Kafka, and Analytics Part One: Data Streaming 101
When Not to Use a Database, As Told by Jun Rao
The Real-Time Future of Data According to Jay Kreps
Sectors:
Financial Services
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States