

February 10, 2020
Real-Time Data Streaming, Kafka, and Analytics Part One: Data Streaming 101

(spainter_vfx/Shutterstock)
The terms “real-time data” and “streaming data” are the latest catch phrases being bandied about by almost every data vendor and company. Everyone wants the world to know that they have access to and are using the latest, greatest data for making business decisions. But using the term is not enough. Do your business executives and users know what data streaming is, where the information comes from and why it is important?
In today’s business world, due to the rate of change in data, the way in which it is processed and reviewed must be updated. The older, traditional methods of scheduling daily updates is outdated. Real-time is the requirement whether it is making business decisions, processing online orders, reading through social media feeds, or analyzing data quickly. Individuals working with data must know that they are analyzing the most recent information. When a company embraces real-time data transaction streaming, it enables real-time analytics processing, which reduces the impact of data transformation on the IT system, allows for faster work speeds, and enables the freshest data to be shared among multiple teams.
In this first installment of a three-part series on data streaming, Apache Kafka, and data analytics, we will dive into fully explaining data transaction streaming and the technologies that make it happen. Later, we will look deeper into Apache Kafka, its role in streaming, and why it is needed for real-time analytics. Lastly, we will provide a crash course in better understanding real-time data streaming to help obtain the full knowledge of what is happening at your firm.
What is Transaction Streaming?
Let’s start at the beginning by defining a data stream or transaction, its characteristics, and how data can be considered streaming.
(agsandrew/Shutterstock)
Data transactions are the moments when changes happen to the database data or metadata. Those changes or transactions that need to be streamed may include record insertions, updates or deletions, as well as changes to a database’s structure or metadata. And those data streams may have one or any combination of three characteristics:
- Unbounded: There is no defined beginning or end to the dataset
- Sporadic arrival: Information is sent in sub-milliseconds or over hours, days, weeks, etc.
- Different sizes: The data sets can range in size from KBs to GBs
While real-time data is often associated with newer sources like IoT sets, the beauty is that anything including database transactions can be turned into a stream. The big difference to remember with batch vs. streaming data processing is that stream data isn’t captured into a unit to be processed at a later date.
Technology Behind Real-Time Streaming Data
At every company, there is a source data set. It’s where all the information lives in a centralized location. As individuals’ access and use this information, they create data sets that source their data from this location, whether it is an on-premise data warehouse or cloud-based data lake or warehouse. This source data is updated continually, and any referring data sets must also be updated. Data transaction updates allow for automation, meaning all changes made in the data are accounted for. Traditional batch processes operate on fixed schedules where large chunks of both new and historical data are replicated all at once. These batch processes tax system resources, repeatedly copying unchanged data sets, and result in an outdated view of the business.
Companies are turning to change data capture (CDC), a newer technology where the most current or real-time changes are collected from the source database as they occur, and then sent to be replicated to the other datasets. Simply put, CDC creates a stream. The data stream is collected and delivered through various platforms, the most common being Apache Kafka (see illustration).
Batch Processing vs. Data Streaming
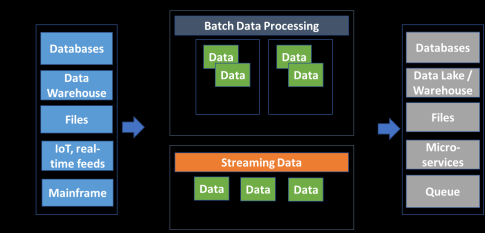
When creating a streaming solution and infrastructure, you must understand that traditional technology solutions will not work. A modern data architecture is required to bring in support for real-time ingestion, unbounded data, multiple velocities, and varying data sizes. It is these many differences that makes traditional solutions not work and require CDC, modern data catalogs, and other requirements for processing streaming data.
The emerging discipline of DataOps, which applies principles of lean manufacturing, DevOps, and agile software development to data management, greatly benefits from real-time streaming. Apache Kafka and other real-time streaming platforms are important to the technology infrastructure as they collect the multiple CDC data streams and move the data to one or more targets. And as infrastructures and data grows, the need for a modern data infrastructure that can scale, support real-time data, and be run in production without impacting the system is critical. Together CDC and Apache Kafka can scale and handle multiple transaction data streams in a modern architecture.
What’s Next?
In our next article, we will build upon our discussion of transaction data and streaming data to look at how companies can integrate and stream data efficiently in Apache Kafka and prepare for greater data analytics processes.

Thornton Craig
If you are interested in more details on transaction data streaming, there is a free Dummies book, Apache Kafka Transaction Data Streaming for Dummies, that provides greater detail.
About the authors: Thornton Craig, a senior technical manager with Amazon Web Services, has spent more than 20 years in the industry, and previously served as research director at Gartner. Dan Potter, the vice president of product marketing at Qlik (formerly Attunity), also has 30 years experience in the field, and is currently responsible for product marketing and go-to-market strategies related to modern data architectures, data integration, and DataOps. Tim Berglund, the senior director of developer experience at Confluent, is a teacher, author, and technology leader.
Related Items:
Confluent Reveals ksqlDB, a Streaming Database Built on Kafka
When Not to Use a Database, As Told by Jun Rao
The Real-Time Future of Data According to Jay Kreps
Applications:
Complex Event Processing
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States