

October 17, 2019
TimescaleDB Delivers Another Option for Time-Series Analytics

(agsandrew/Shutterstock)
Companies that want to run analytics atop time-series data have a few options available to them. One of the newest is TimescaleDB, an extension of PostgreSQL that was released as open source by the company Timescale about a year ago. Datanami recently caught up with Timescale co-founder and CEO Ajay Kulkarni at the Strata Data Conference in New York.
Kulkarni and his Timescale co-founder, CTO Michael Freedman, didn’t set out initially to build a time-series database back in 2015. In fact, their plan was to build an Internet of Things (IoT) platform that could store and process data arriving from hundreds of thousands of devices.
“We said ‘Oh, hey, time-series data, time-series databases. That’s a new category. There’s probably some companies that do this well. Let’s use some of their products,'” Kulkarni said.
The technologists adopted one of the time-series databases on the market at that time, but they ran into some issues pretty quickly. For starters, the time-series database they adopted was a NoSQL database, which forced Kulkarni and Freedman to take additional steps to normalize the data before querying it. It also didn’t support SQL, and was not overly reliable.

Ajay Kulkarni, CEO and co-founder of Timescale
“We had our device metadata in Postgres and our sensor data in a time-series database, and we had to do complex joins at the application level,” to bring them together, Kulkarni said. “And anytime you wanted to look at something new, like ‘Hey can we look at device uptime by device type?’ it required an engineering sprint to get that out. We said, ‘This is just a database join! Why isn’t the device data and the data that describes the devices in the same database?'”
The pair was reluctant to embark upon extra development work if it didn’t have to, but they couldn’t find the tools they needed to complete their project. “Our philosophy is that we don’t want to embark upon science projects,” Kulkarni said. “Why reinvent the world if you don’t have to?”
That led them to look at Postgres, the 30-year year old relational database. While Postgres was time-tested and battle-hardened, it wasn’t really developed for time-series data specifically, and so Kulkarni and Freedman modified it to store and query time-series data more efficiently.
The Postgres extension that Kulkarni and Freedman developed essentially is an abstraction that allows many individual database tables to be viewed as a single table, what they called a “hypertable.” This hypertable view is made up of many chunks that are created by partitioning the data either according to a time interval or by a “partition key,” such as device ID, location, or user ID.
The database extension gave Kulkarni the performance they needed to efficiently store and query hundreds of millions of rows of time-series data, but without modifying the underlying Postgres database to the extent that future Postgres fixes would not function without extra development work. In other words, they didn’t fork Postgres.
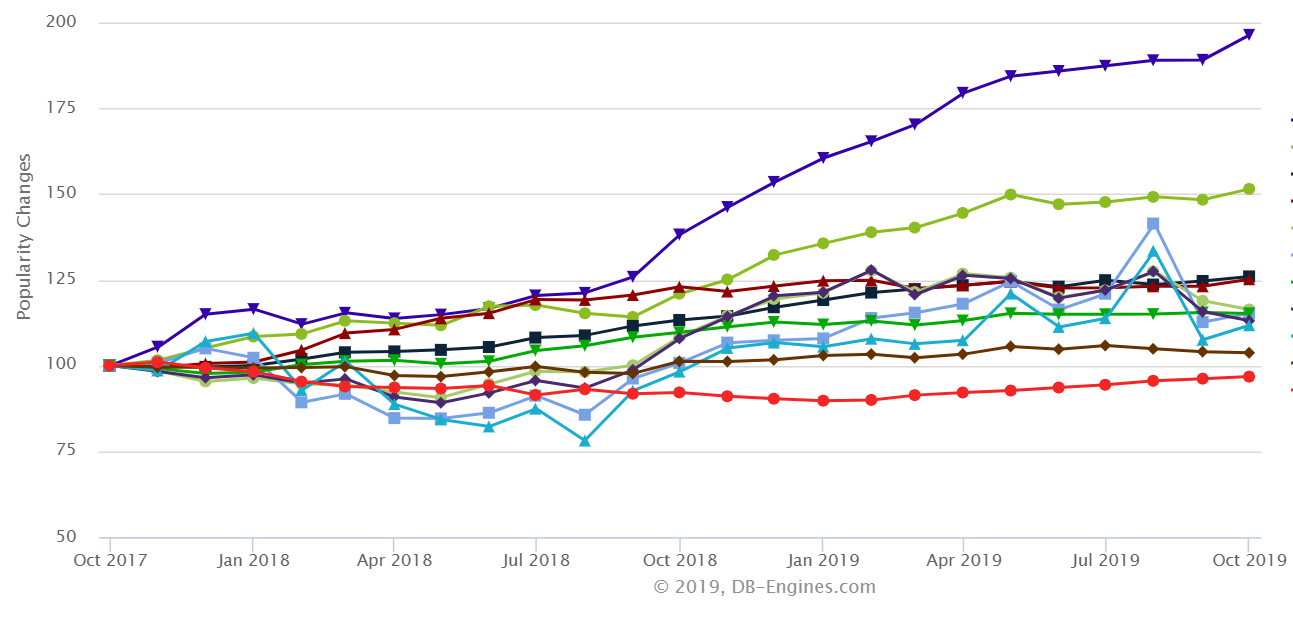
Interest in time-scale databases (purple line) has grown faster than any other database category over the past two years, according to DB-Engines.com
“People thought we were crazy when we first did this,” Kulkarni said. “We said, you could actually build this on Postgres, and there’s a lot of benefits if you do that. Number one, Postgres is open, it’s rock solid, it’s reliable. Number two, there’s already a Postgres community. And three, there’s a broad ecosystem of tools that’s larger than any time-series database. And you get full SQL out of the box.”
Kulkarni and Freedman put this Postgres extension at the heart of their IoT platform, and prepared to sell and support that offering. But the surprises were not over for the two. “Long story short,” Kulkarni said, “they were more interested in the database than they were in the IoT stuff, so we rebranded with the Timescale launch two-and-a-half years ago.”
Since officially launching at the Strata + Hadoop World conference in San Jose in April 2017, Timescale has attracted quite a bit of interest, from both customers and investors. Since then, interest in time-series databases in grown faster than any other database category, according to data collected from DB-Engines.com.
“The key reason why you’d want a time-series database is performance, ease of use and cost,” Kulkarni said. “The fundamental idea is if you build something that’s optimized for a workload, then you can much better performance and put out a much better user experience than you could otherwise, which is why we see 1,000 times faster queries than Postgres, Cassandra, and MongoDB for time-series data.”
On the customer front, the company counts names like ADP, Bloomberg, Comcast, and Schneider Electric as enterprise customers. The company has attracted one of the world’s largest gaming companies, as well as marketing analytics firms. There’s also a cryptocurrency firm using TimescaleDB, Kulkarni said.![]()
When Timescale was founded, Kulkarni figured the database would mostly be used for storing and analyzing IoT and IT monitoring data. But in fact, the use cases have been much broader, he said. That’s because time-series data has suddenly become ubiquitous, Kulkarni said.
“Organizations want to make better data-driven decisions faster. What does that mean?” he asked. “Better data-driven decisions means you want to store data in the highest fidelity that you can, and time-series is actually the highest fidelity that you can capture, because every data in its raw form has a timestamp.”
On the investor front, the New York company has raised more than $31 million from some of the biggest Silicon Valley venture capital firms, including Icon Ventures, New Enterprise Associates, and Benchmark. The open source version of TimescaleDB has been downloaded millions of times, and the project will soon have more GitHub stars than Druid, Kulkarni said.
“We’ve had massive growth because people had the same pain point we had, which was time-series databases before TimeScale didn’t support a relational model, and they didn’t support full SQL,” he said.
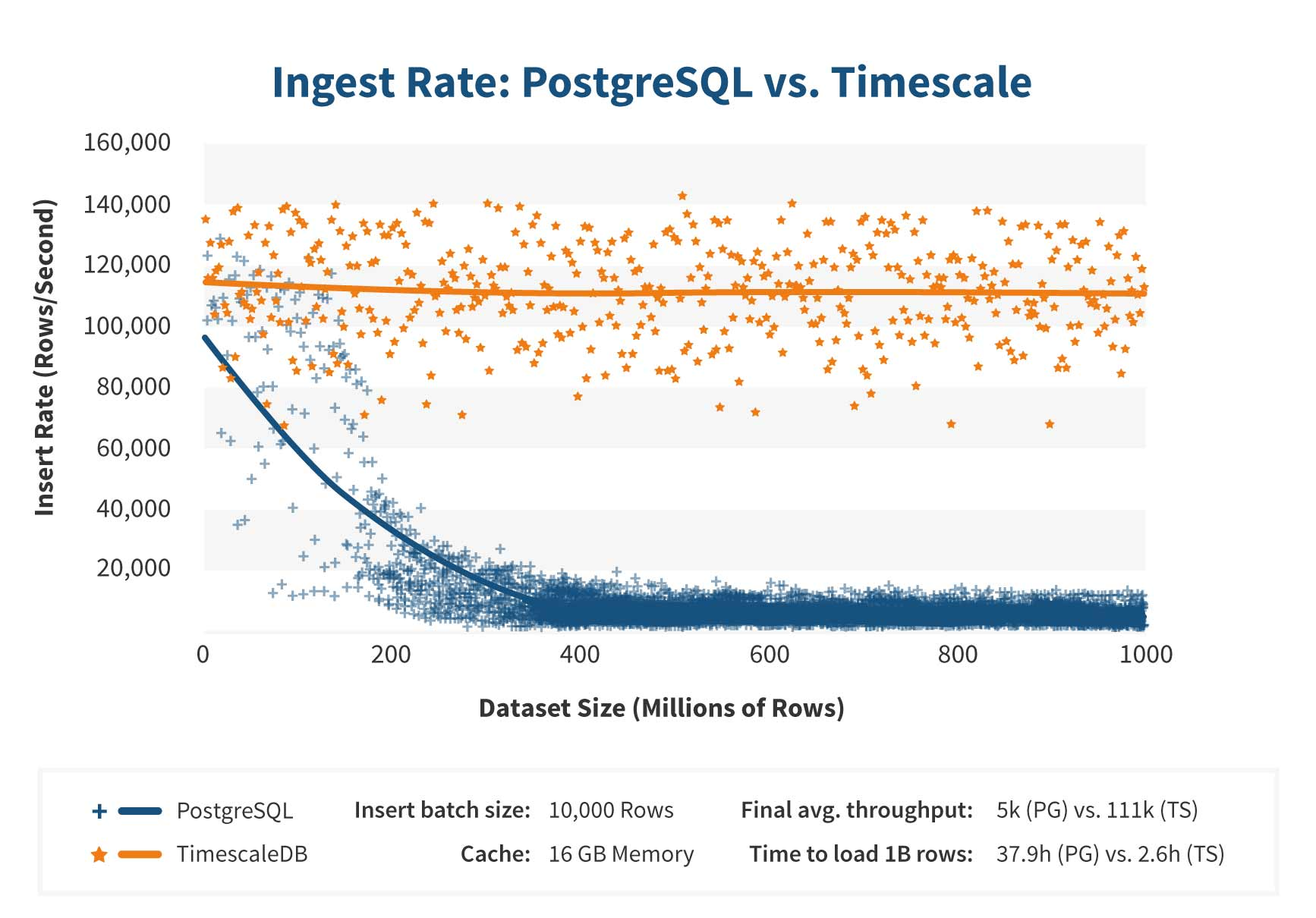
TimescaleDB can maintain a data ingestion rate at higher scale than plain vanilla Postgres, according to Timescale
Timescale 1.0 shipped about a year ago, around the same time that AWS launched its own time-series database, called TimeSteram. Up to this point, the database has been deployed on single-node systems, which requires customers to get bigger machines if they want to scale up. In August, the company announced the first distributed version of TimescaleDB, which is currently in beta and expected to become generally available before the end of the year.
The new distributed version of TimescaleDB will use “chunking” instead of “sharding.” It will let users scale the database to handle petabytes of time-series data and to be able to calculate more than 10 million metrics per second, Kulkarni said. The company is also working on a new compression algorithm that will boost data storage capacities by 20x to 40x, he said.
The company also recently launched a cloud version of the database, called Timescale Cloud. The on-demand time-series service is available on all three major public clouds.
Related Items:
AWS Launches Time-Series Database
Time-Series Leader InfluxData Raises More Cash
Applications:
Data Mining
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States