


November 29, 2018
AWS Launches Time-Series Database

AWS threw its hat into the nascent ring for time-series databases yesterday with the launch of AWS TimeStream, a managed time-series database that AWS says can handle trillions of events per day.
Time-series databases have emerged as a best-in-class approach for storing and analyzing huge amounts of data generated by users and IoT devices. While relational and NoSQL databases are sometimes used for time-stamped and time-series data – such as clickstream data from Web and mobile devices, log data from IT gear, and data generated by industrial machinery — today’s massive data volumes from the IoT have outstripped the capability of those databases to keep up.
As the high-end time-series use cases piled up, AWS decided it was time to take action and make its entry into the still-specialized field, much as it did with last year’s launch of Neptune, a graph database, which is another specialized database field that’s emerging.
AWS CEO Andy Jassy outlined the market dynamics of time-series databases and the need for new time-series databases architectures as part of his three-hour keynote address at the AWS re:Invent conference yesterday in Las Vegas, Nevada.
“The problem is, more and more companies have this need and desire to collect and analyze time-series data, and there aren’t good solutions for them for how to use it in a database,” he says. “If you try to do it in a relational database, it’s quite difficult. It means you have to build these indexes which are large and clunky and slow to query.”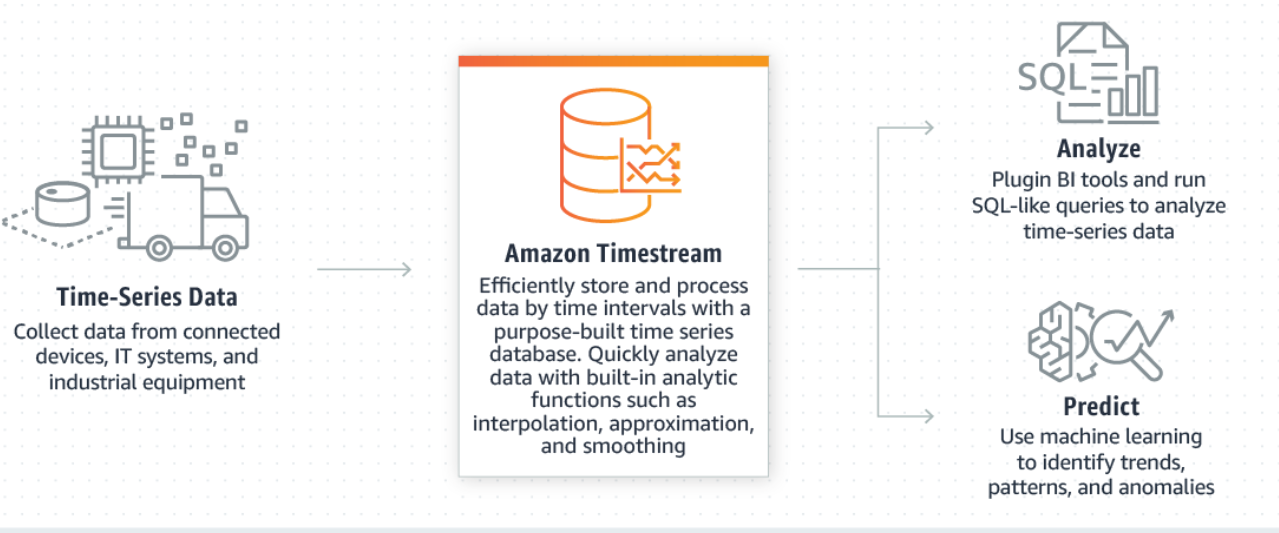
The schemas in relational databases are rigid and can’t be adapted quickly enough to changing real-world in the IoT, such as the addition of sensors. “Also relational databases don’t have the analytics pieces that you want in time series, like smoothing and interpolation and approximation,” Jassy says. “These are things you don’t have.”
AWS says its new Timestream database organizes data by time intervals, which reduces the amount of data that needs to be scanned to answer a query. It minimizes storage needs and costs by automatically applying rollups, retention, tiering, and compression of data. AWS is delivering the services (it’s still in a technical preview) as a serverless product, which means there’s no underlying server on AWS to manage.
Timestream features what AWS calls an “adaptive query processing engine,” which it says can adapt to different time scales, like milliseconds, microseconds, and nanoseconds. All told, AWS claims Timestream can deliver 1,000 faster query performance at one-tenth the cost of a relational database.
“Timestream is going to change the performance of your time-series database by several orders of magnitude,” Jassy says. “It’s a very different equation. The reason is, we built it from the ground up to be a time-series database.”
The Timestream announcement caught the eye of the folks at InfluxData, which is currently the leader in time-series databases, according to DB-Engines.com.
InfluxData company says the Timestream announcement validates the interest in time-series databases that it’s seeing, and that it welcomes new players in the market. But it differentiated itself from the cloud giant by highlighting its open source approach to development, as opposed to Amazon’s closed approach with Timestream.
“Innovation is born from collaboration and, unlike Amazon, this is the focus of our approach,” the company said in a statement sent to Datanami. “Over the last several years we’ve led the way with purpose-built tools and open source technologies as the best solutions to optimize the developer experience and deliver business value for DevOps and IoT applications. Open source is in our DNA and we remain steadfast in our commitment to the community.”
You can sign up for the technical preview of AWS Timestream at aws.amazon.com/timestream.
Related Items:
AWS To Build You a Data Lake in ‘A Few Clicks’
AWS Bolsters Machine Learning Services at Re:Invent
Applications:
Enterprise Analytics
Leading Solution Providers
















