

September 24, 2019
Cloudera Begins New Cloud Era with CDP Launch

Eleven years after its founding, Cloudera fulfilled its name in a big way today with the launch of Cloudera Data Platform (CDP), its new flagship data platform that allows customers to securely manage and govern their data while deploying analytic and AI applications in a platform-as-a-service (PaaS) approach on the cloud.
CDP is an amalgamation of, and the direct replacement for, Cloudera’s two legacy Hadoop distributions, including the Cloudera Distribution of Hadoop (CDH) and the Hortonworks Data Platform (HDP). But CDP differs in big ways from those on-premise oriented platforms, including the elimination of YARN in favor of Kubernetes for container management, and a replacement of HDFS for public cloud object stores, including Amazon S3. Support for Microsoft Azure and Google Cloud and their object stores will come later.
Cloudera has three CDP apps currently available, in addition to two administrative tools. The PaaS apps include Cloudera Data Warehouse, which includes Hive and Impala SQL engines; Cloudera Machine Learning, which includes the company’s data science solutions for Python, R, and Spark; and Cloudera Data Hub, a YARN-managed environment where users can run traditional Hadoop workloads, like MapReduce and Spark.
Cloudera has three more apps in the works, for streaming, data engineering, and operational databases. It’s also working to deliver the preview of a on-premise version called CDP Data Center later this fall, with general availability expected next year.

Cloudera is remaking its Hadoop distribution in a flexible solution that runs in the cloud, on prem, or a combination of both.
On top of the three cloud apps, Cloudera is delivering two additional pieces. That includes the Shared Data Experience (SDX), which provides security, governance, and lineage to data stored across all Cloudera solutions, including cloud and on-prem CDH and HDP clusters, as well as hybrid deployments that combine both. The second add-on is Control Plane, which functions as a “single pane of glass” for administrators to spin up and spin down clusters in the cloud, on-prem, and hybrid scenarios.
With CDP, Cloudera is giving customers access to powerful big data management and analytic solutions, but leaving out the technological complexity that Hadoop has become known for, says Cloudera Chief Product Officer Arun Murthy.
“We’ve really made a conscious effort to tackle the complexity of the platform, if you will, by giving them these native SaaS experiences, so they don’t have to operate it or manage it,” Murthy says. “The software does it for them.”
New Simplicity
Cloudera still develops a complex Hadoop distribution, replete with 50-odd projects that deliver a rich array of services. But the writing is clearly on the wall: Customers don’t want to deal with the technical mumbo-jumbo that has marked Hadoop up to this point. They just want to analyze their data.
“The value [of CDP] for the customer, from the line of business standpoint, is they don’t need to know that there is a Hadoop cluster,” Murthy says. “They just want to run a SQL query. They just want a JDBC endpoint so they can point their BI tool to it. What happens behind the scene, they care less about.”
This is a dynamic that the big public cloud providers have been exploiting for some time, to the detriment of the Hadoop distributors — er, distributor — who have mostly focused on delivering on-prem software to the world’s largest enterprises. The irony is that, despite the proclamations that “Hadoop is dead,” Hadoop technology remains very much alive in the cloud, where it forms the basis of Amazon’s Elastic MapReduce (EMR), Microsoft’s Azure HDInsight, and Google Cloud DataProc. (For a great perspective, read Murthy’s “Hadoop Is Dead. Long Live Hadoop” story earlier this month on Medium.)
Cloudera is responding to the shift in market — perhaps later than it should, but it’s making progress, nonetheless. “Obviously we’ve been helping the largest enterprises on the planet kind of handle data,” Murthy tells Datanami. “And now it’s very clear the public cloud is very much part of their overall enterprise architecture.”
Hybrid Workloads
But the goal for Cloudera is not just to match EMR, HDInsight, or Google Cloud DataProc, Hadoop distributions all. Instead, the California firm plans to surpass those solutions by delivering multi-cloud and hybrid capabilities that allow customers to run their big data workloads where they want it. That’s something that the public clouds can’t offer.
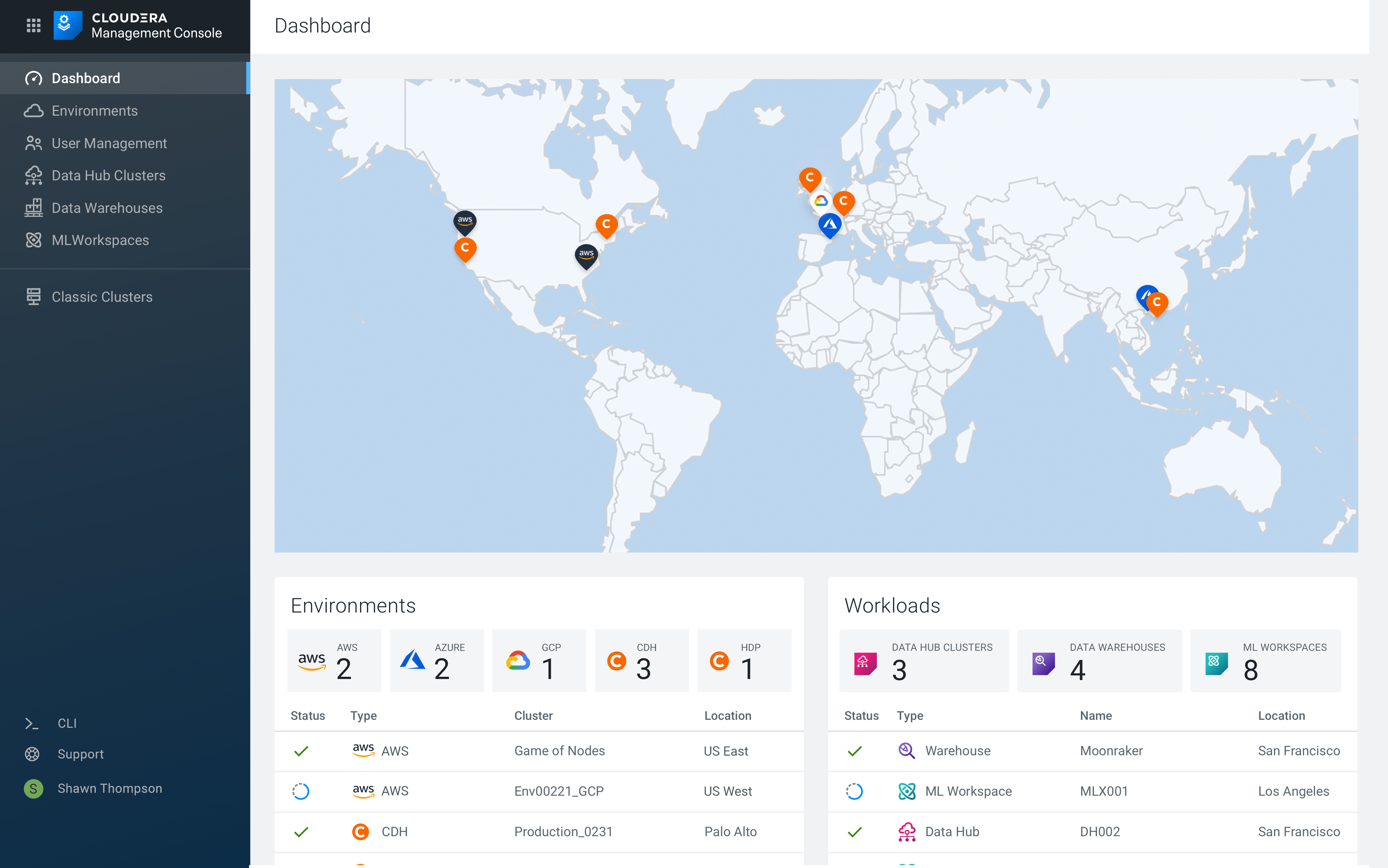
Cloudera lets admins spin cloud and on-prem instances up and down with its Control Plane
CDP customers will be able to move data and workloads from on-prem to the cloud and vice versa. They’ll also be able to move data and workloads from one cloud to another, as the CDP apps will basically be identical across AWS, Azure, and GCP.
“You’ll have an application to move data from CDH to S3. Then you’ll have an application to move that workload from CDH on prem to Amazon,” Murthy says. “At the end of the day, a SQL query is still a SQL query, a Spark application is still a Spark application. We take care of the differences under the hood between HDFS and S3, and so on.”
And because SDX uses metadata to track lineage and enforces authentication and access policies across cloud and on-prem clusters, customers will have the confidence of knowing that their security and data access policies are being applied consistently across these varied environments, Murthy says. That’s a big deal, and it’s something the cloud providers cannot do.
“When you use our application to move data from CDH running HDFS to CDP running S3, we copy the data. But we also copy the metadata and security policies and governance and lineage,” Murthy says. “So then when the data lands it’s not just some bits landing in an S3 bucket. It’s the entire data and the metadata. So instantly it’s ready to go.”
On-Prem Version Coming
Data warehousing and machine learning workloads will run identically on-prem and in the public clouds. “From the end user perspective, it’s the same workload,” he says. “The fact that it’s running on S3 and Kubernetes is hidden from the end user. And frankly, a lot is hidden from the administrator, himself or herself.”
Cloudera is working with IBM to enable the future on-prem version of CDP to run in a Kubernetes environment, specifically Red Hat’s OpenShift software. “…[T]he combination of Cloudera Data Platform and IBM Cloud Pak for Data can deliver a complete answer/solution/information architecture,” Rob Thomas, IBM’s general manager for data and AI, stated in a press release. “Nobody comes close to what the three of us can do,” he added at the Cloudera Analyst Conference here in New York City on Monday.
Cloudera is clearly responding to the momentum behind Kubernetes, which is emerging as the defacto standard workload scheduler in the cloud. It’s done the work to replace Kubernetes in its stack while finding a place for existing YARN applications. When it comes to storage, the company is involved in the Ozone project, which hopes to meld the best of HDFS with an S3-comptable layer for Hadoop.
Pricing on the cloud is designed to be competitive with other cloud offerings. The Data Warehouse solution will cost $0.72 per hour on an AWS r5d.2xlarge instance (a 4-core 8 VCPU instance with 64GB of RAM). The Machine Learning solution will cost $0.68 per hour on an AWS m5.2xlarge instance a 4-core 8 vCPU instance with 32GB of RAM. The Data Hub offering costs $0.24 per hour on an AWS m5.2xlarge instance (a 4-core 8 VCPU instance with 32GB of RAM. The user fee is $399 per month. The on-prem version will cost $10,000 per node.
Related Items:
Cloudera Commits to 100% Open Source
Cloudera Unveils CDP, Talks Up ‘Enterprise Data Cloud’
Here’s What Doug Cutting Says Is Hadoop’s Biggest Contribution
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States