

November 28, 2018
Dremio Donates Fast Analytics Compiler to Apache Foundation

Dremio has donated the Gandiva Initiative — a LLVM-based execution kernel designed to speed up analytical workloads – to the Apache Software Foundation, where it will become available to anybody who wants it as part of the Apache Arrow project.
Dremio spent considerable resources developing Gandiva Initiative for Apache Arrow, which it originally released last month as part of Dremio 3.0. Dremio is a data-as-a-service offering that uses the in-memory columnar Apache Arrow data format to speed up and simplify how data analysts and data scientists access a wide range of data sources.
According to Dremio, some queries and operations, when run through the Gandiva compiler, can execute 100 times faster. The software has already been incorporated into several data science tools, including Pandas, which is popular with Python developers, as well as Apache Spark. Nvidia is also using it in its recently announced RAPIDS initiative to accelerate machine learning adoption.
Jacque Nadeau, the co-founder and CTO of Dremio, recently briefed Datanami on the announcement, and explained the significance of Gandiva and how it could improve the sophistication of work accomplished by citizen data scientists.
“Gandiva is basically an execution kernel that uses LLVM to do very efficient vectorized processing of data in the Arrow representation,” Nadeau says. “We found it to be very useful in our product and we thought the best place for it would actually be in Apache Arrow, so we donated it to the Apache Software Foundation and they very kindly accepted.”
Nadeau and his Dremio colleagues spearheaded the development of the Gandiva Initiative to address what they perceived as a proliferation of busy-work among data developers. They observed that many machine learning algorithms were being implemented in a variety of different ways with a variety of libraries on a variety of different hardware. Quite often, these implementations were sub-standard, to a certain degree, and offered non-optimal performance.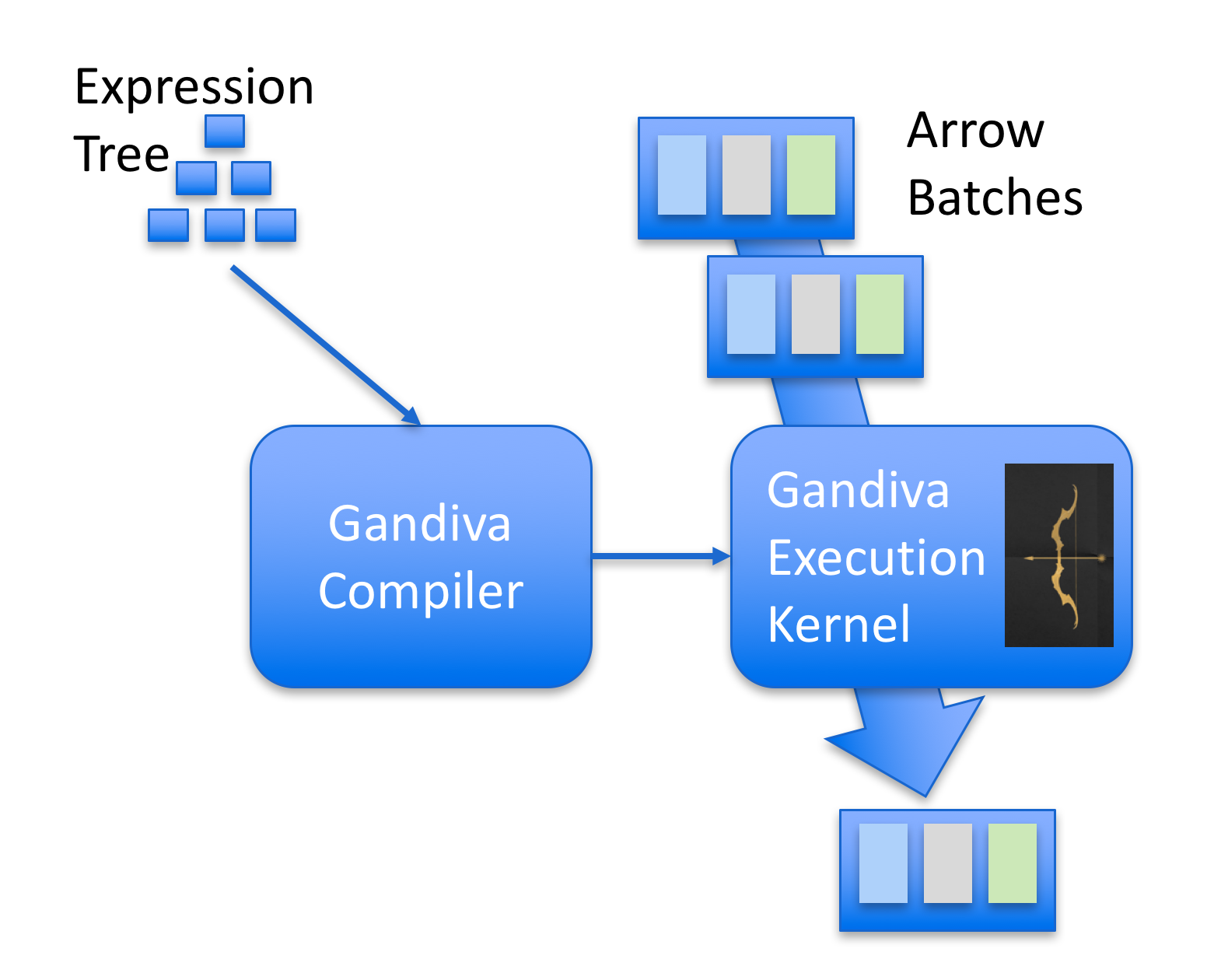
“We saw this as an opportunity,” Nadeau says. “If we can work together as a community on this rather than everybody having to reinvent the wheel, not only do we benefit a bunch of different projects and a bunch of different communities, but we also can set a higher standard for the quality of all those algorithms.”
In some ways, Gandiva is a logical extension of the work that stated in Apache Arrow to standardize and optimize the low-level primitives that many of the data processing and data movement tasks that take place with advanced analytics and machine learning workloads. Apache Arrow itself can help speed up a few hundred different types of operations, according to Nadeau, and Gandiva bring several hundred more.
“Arrow is really focused on improving the performance of analytical and data science workloads and making those things more efficient and better able to decouple among different subcomponents, and so that’s really where Gandiva is focused as well,” he says.
“Data science and analytics are, at their core, another form of data manipulation,” Nadeau says. “And a lot of the operations in data manipulations, in either form, are basically heavy lifting, or moving data around and applying different levels of expressions. Gandiva’s core strength is being able to make those heavy lifting operations be much more efficient.”
Gandiva brings two elements to the table, according to Nadeau, including faster processing and extending what Arrow can already do. Developers can get the benefits of Gandiva by adopting Apache Arrow, which is a free and open source product that’s being downloaded about one million times per month now.![]()
“It’s not just making things faster, but also making Arrow be able to express more concepts and do more types of processing,” says Nadeau, who is the Project Management Committee (PMC) chair of Apache Arrow. “That’s the way Gandiva was designed — to be very extensible. So if a developer wants to implement a new algorithm or a new way to solve a particular technology problem, they can extend Gandiva, either in the project or in their own code, to allow Gandiva to support those scenarios.”
Gandiva is supported in Pandas dataframes, where it’s helping to empower data scientists to develop more production-ready code in Python without forcing them to resort to rewriting their models in a lower-level language like Scala to get performance, according to Kelly Stirman, the CMO and VP of strategy for Dremio.
“As Pandas becomes more standardized on Arrow and makes better use of Gandiva, the benefits accrue to the data scientists, who aren’t changing the way they build a model or do training of a particular training set,” Stirman says. “That part of their experience just gets a lot faster, and if you’re in the cloud, it’s not just speed but also cost. It gets cheaper. The cycles to perform the machine learning tasks are greatly reduced through Arrow and Gandiva.”
Wes McKinney, the creator of Python Pandas, says Gandiva will help engineers and scientists who work with multiple languages and systems ensure that data flows easily among different environments.
“Apache Arrow has made enormous progress since its inception, and Gandiva—an analytical expression compiler—is a natural next step in the growth of the ecosystem,” McKinney, who is also a member of the Apache Arrow and Apache Parquet PMCs, says in a press release. “This code donation provides huge opportunities for optimization with modern hardware platforms allowing for dramatically better performance for a wide range of workloads on Arrow data. It’s a great benefit for the Apache Arrow community.”
Related Items:
Dremio Fleshes Out Data Platform
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States