

July 19, 2017
Dremio Emerges from Stealth with Multi-Threat Middleware
If your business analysts are struggling to connect, prepare, and query data from multiple sources in a timely and cost effective manner, you might be interested in learning about Dremio, a new open source software company that officially emerged from stealth today.
Dremio is aiming high by taking on several related data analysis issues that plague modern organizations. This includes the complexity of sourcing data from disparate sources like relational databases, NoSQL databases, cloud-based stores, and files systems like Hadoop. It includes the need to endlessly copy and transform data from its raw state into something usable, which often gets loaded into a data warehouse. It involves the need to build indexes, tables, and aggregates that speed up queries from BI tools. It’s about the reliance on IT to build systems, and the months-long waits to get answers to questions.
“Nobody likes this. In fact, everybody hates this, but it’s viewed as really the only alternative,” says Dremio’s CMO Kelly Stirman. “All that stuff in the middle is a necessary evil that everybody would be very happy to no longer have to deal with.”
Dremio is taking a crack at wiping away a large chunk of the existing middleware stack and thereby simplifying the modern analytics infrastructure with its open source software. The company is doing this by creating a new type of middleware that essentially replicates a lot of the functionality that is spread across other product categories, including self-service data preparation tools, ETL tools, OLAP engines, and data catalogs.
“It’s a new kind of technology that runs between all the places where you’re creating data and all those tools that consumers of data use to drive the business,” Stirman says. “At a super high level, Dremio is trying to put the consumer of data in control of data itself, in the same way that Amazon has put infrastructure in control of developers.”
Data Fabric Architecture

Dremio streamlines analytical access to data stored across disparate systems
It’s hard to categorize a brand new tool that does so many things. But if there’s one category that fits well for Dremio, it’s supplying the data fabric that connects disparate elements together into something resembling a seamless whole. Data fabrics are emerging as a new category of tool for simplifying data management and analytic tasks.
Dremio aims to be the “missing link” in the data value chain through four main components.
The first is Apache Arrow, the in-memory data layer that forms the digital glue to connect disparate big data engines, such as Spark, Cassandra, Pandas, Python, and Drill. Arrow, which was developed by Dremio founder and CTO Jacques Nadeau, was introduced to the public last year and scales to thousands of Hadoop nodes via native deployments on YARN.
Dremio’s second component is support for native query push-downs into a range of popular data stores, including Hadoop, MongoDB, ElasticSearch, and Amazon S3. The third component are dubbed “Dremio Reflections,” which are data caches that have been compresses, columnized, and otherwise optimized to speed up queries (i.e. the replacement for OLAP). The fourth component is a query planner dubbed the Universal Relational Algebra, which Dremio says is necessary to enable the product to work with a broad range of queries.
“When you put these four things together, it drives performance improvements for consumers of data that are one or more orders of magnitude of best-in-class capabilities in the market today,” Stirman says. “It completely changes how people think about what they can do with data.”
Data Analysts, Self-Served
Dremio has both middleware components as well as a GUI targeted at data analysts. The middleware components gets distributed on all the servers and clusters that make up your analytics infrastructure (i.e. Hadoop, MongoDB, and Oracle servers or clusters), while the Web-based GUI provides a place for analysts to work directly with data, and to collaborate with each other, too.
“All those dozens of different technologies that you’ve had to deploy in the past and kind of stitch together to make it work – there’s a much better way to do it with a single technology in the middle, which is Dremio,” the company’s founder and CEO, Tomer Shiran, tells Datanami. “And by providing a UI that actually targets the end user, the end user now has the ability to interact with this layer in the middle. We can now allow them to do these things on their own.”
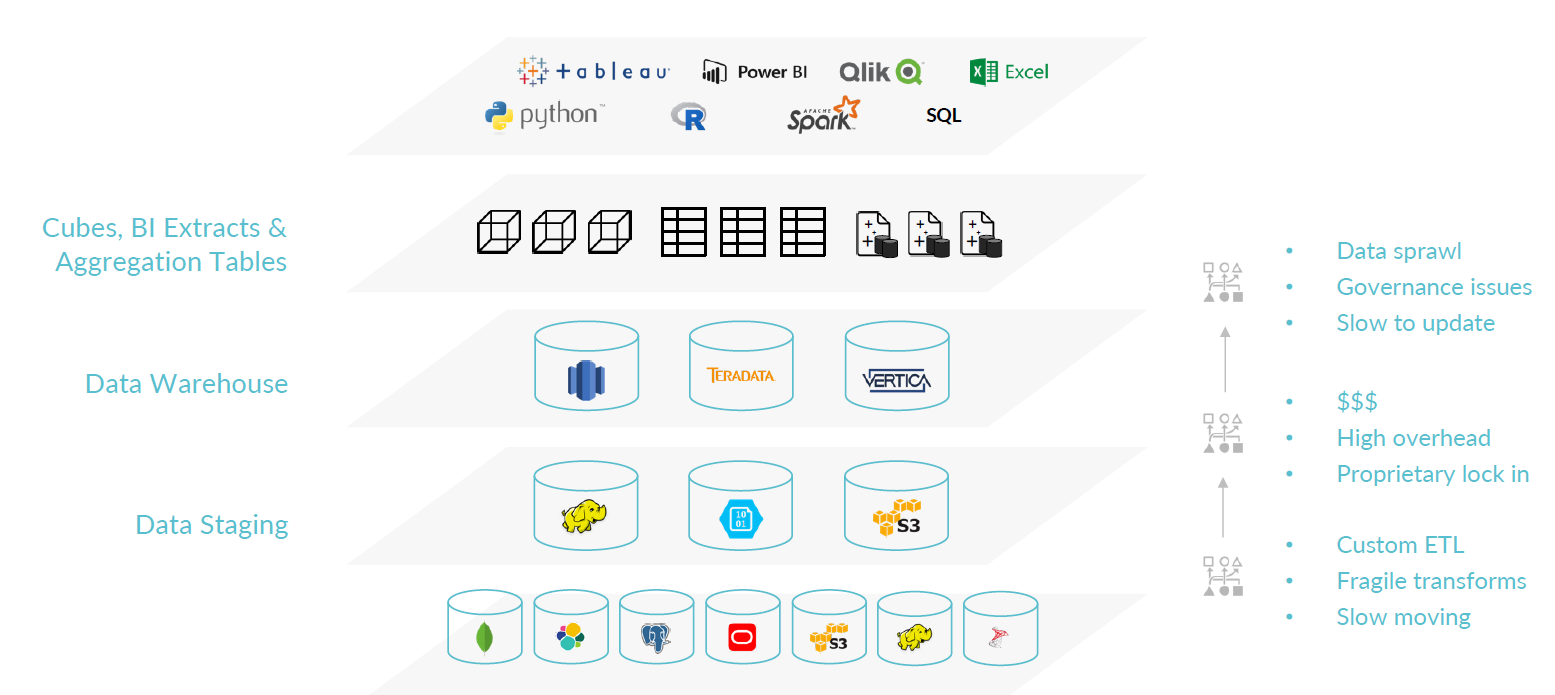
Dremio aims to replace a big chunk of the big data stack, including data warehouses, ETL tools, and OLAP cubes
Shiran compares the Dremio GUI to how users interact with Google Docs. “If you think about how you interact with Google Docs, where you create new document and share them with your colleagues and can build on top of each other — we do the same thing with data sets.”
The one area where Dremio is not trying to impact change is the BI tool. “Tableau and PowerBI are providing the last mile of connectivity,” Shiran says. “Those are awesome tools for visualization. We don’t really talk to people who don’t like those tools. You don’t hear a lot of complaints about them the way you hear about data warehouse and ETL vendor.”
In fact, Dremio complements those tools, he says. “Dremio enable these Tableau and PowerBI user to have a place where they can go and create new data sets that are derived from existing data sets,” he says. “In our system, when you do a transformation, it’s all logical, and you save it as a virtual data set…..In Dremio the BI tools connect to us, and all these virtual data sets are exposed directly through the BI tools without having to materialize the data” in a data warehouse.
Stirman, who cut his teeth on BI as an Oracle DBA in the 1990s, holds a certain amount of disdain for the status quo. “We think the world will be a much better place without ETL, data warehouses, or [OLAP] cubes.”
The Mountain View, California company has $15 million in venture funds, a roster of executives hailing from MapR, MongoDB, MarkLogic, Microsoft, Mesosphere, and Hortonworks, about 40 employees, a free community and an enterprise version of its product, and a ready pipeline of prospects.
All that’s left now is to radically alter the face of analytics as we know it. It’s a tall order, to be sure, but a worthy one to follow.
Related Items:
Arrow Aims to Defrag Big In-Memory Analytics
Striking a Balance: Big Data Debt and Big Data Value
Big Data Fabrics Emerge to Ease Hadoop Pain
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States