

December 12, 2017
Why Deep Learning May Not Be So ‘Deep’ After All

(Jirsak/Shutterstock)
Deep learning has given us tremendous new powers to spot patterns hidden in great globs of data. For some challenges, neural networks can even outperform top human experts. However, despite all the progress the new approach represents and the hope that it will lead us to actual artificial intelligence, there are big limits on the practical application of deep learning.
Deep learning has emerged as the latest “easy button” for big data analytics. The thinking seems to go like this: Got a lot of data to analyze? Don’t worry – just fire up a neural network using TensorFlow, Keras, or some other deep learning library, and presto! You’ll have the right answer in no time.
While deep learning has excited the data science and computer science communities with its capabilities, the reality is that it’s neither as automatic nor as powerful as many people think. And in many cases, experts say data scientists are often better off using well-established machine learning techniques than working with the latest deep learning library.
One of the biggest misconceptions about deep learning approaches is that it eliminates the need for a practitioner to do a lot of manual feature selection and tuning. That’s only partially true, says Michael Xiao, who’s a Fellow of the Society of Actuaries and a veteran of Kaggle data science competitions.
“A lot of people think if you start using neural networks, you really don’t need to do anything. That’s absolutely not true,” he says. “You still need to do a lot of pre-processing.”
Flipping the DL Script
Xiao, whose day job is leading a data science team for a Blue Cross Blue Shield health insurance group, was recently involved in a Kaggle competition that sought to find better ways of classifying images of cervixes for the purpose of improving automated detection of cervical cancer. He discovered several tricks that helped boost the accuracy of his convolutional neural network (CNN).
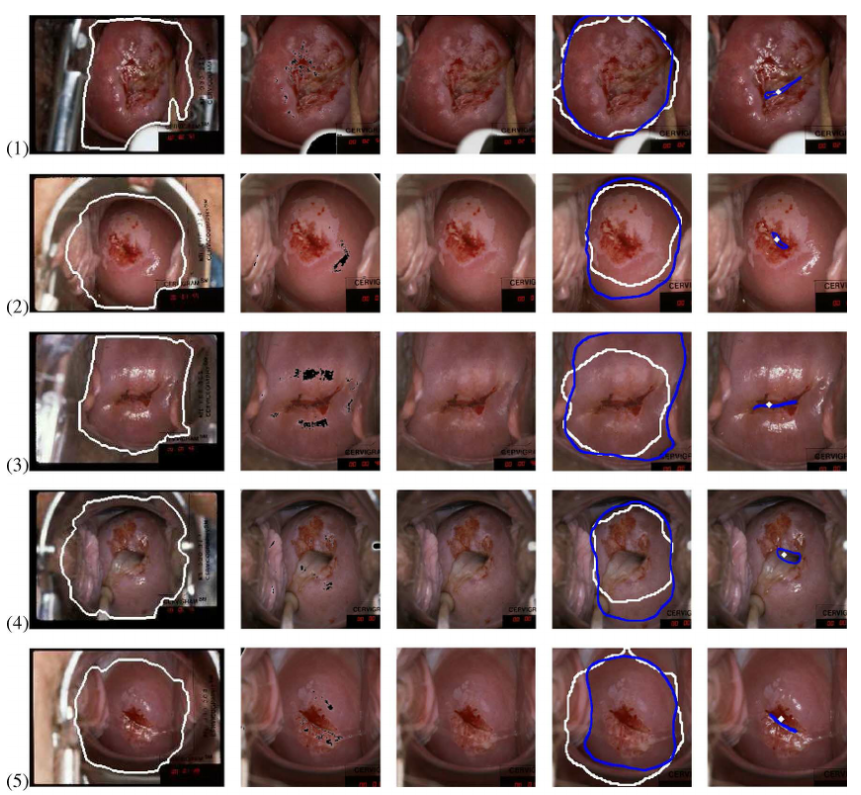
Flipping images of cervixes can boost the classification accuracy of convolutional neural networks (Courtesy National Cancer Institute)
For example, Xiao found that flipping the images of the cervixes provided more sample pictures that his CNN could train on, which led to a 1% improvement in accuracy. The flipped image is just another example of what a cervix can look like, even though it wouldn’t fool a human into believing that it’s a second cervix, he says.
“If I’m just flipping the image, it’s probably the same as the other image,” he says. “But the model doesn’t actually generalize to that extent without you giving it that data. Neural networks aren’t to the point where they can inherently understand.”
He also found that using other machine learning methods to detect which part of the picture contained the cervix also helped. So did scaling down the resolution of the large image files into something more manageable for his computer. These are “common sense” techniques that data scientists can use to improve the effectiveness of their neural network.
So while it’s true that neural networks handle the feature selection component of deep learning automatically, there is still plenty of work in deep learning to keep a data scientist busy. It’s far from “set it and forget it,” Xiao says. “Even though you don’t have to do feature selection, you still have to process the images,” he says.
DL Not a Silver Bullet
There’s no denying that there’s a lot hype surrounding deep learning. In 2017, progress in applications of neural networks has fueled a widespread belief that AI breakthroughs are just around the corner.
While deep learning approaches have given us better results in some applications, the technology is not being used outside of two primary use cases: image recognition (i.e. computer vision) and text recognition (such as natural language processing). For most data science use cases that don’t involve manipulating images or text, traditional machine learning models are hard to beat.
“I would say right now there’s actually no proof that [neural networks] can perform better,” Xiao says. “If you have data sets that are tens of thousands or hundreds of thousands in number and you have a traditional regression problem and you’re trying to predict the probability that someone is going to click on an ad, for example, neural networks — at least the existing structures — just don’t perform as well as other methods.”
That probably comes as a surprise to many in the industry who figured deep learning was going to drive data science into the AI future. “I don’t think that’s the answer that most people want to hear,” Xiao says “People like to throw around the term AI, but we’re not quite to that level yet.”
That line of thinking is backed up by some of the most prominent names in the machine learning community. Francois Chollet, an AI researcher at Google and the inventor of Keras, says that while deep learning was supposed to emulate the human brain, it’s really just a more powerful form of statistical inference.
Deep neural networks do not actually replicate the functioning of the human brain (Life science of anatomy/Shutterstock)
“The most important problem for A.I today is abstraction and reasoning,” Chollet said at the recent AI By the Bay conference, according to a March blog post by TopBots CTO Mariya Yao. “Current supervised perception and reinforcement learning algorithms require lots of data, are terrible at planning, and are only doing straightforward pattern recognition.”
That view is also backed by Geoffrey Hinton, the Canadian computer scientist and Google researcher who’s been called the “father of deep learning.” While neural networks are decades old, it was Hinton who advocated for back propagation of data in a multi-layered approach to better simulate the complexity of information processing in the human brain.
Now Hinton is exploring a new computational theory that utilizes column-like collections of data, or “capsules,” to go along with the horizontal layers in a neural network. Such a construct could help alleviate some of deep learning’s current limitations, and provide another “bridge between computer science and biology,” he says in the MIT Technology Review.
Hinton was even more adamant about the need for a new approach in a discussion with Axios this fall — particularly when it came to supervised learning and the back-propagation approach that he’s famous for. “My view is throw it all away and start again,” he told Axios. “I don’t think it’s how the brain works,” he said. “We clearly don’t need all the labeled data.”
Getting a better model of how the brain actually works would be a good place to start when it comes to building true AI. That’s the path that neuroscientist and Starmind founder Pascal Kaufmann is following, but as of yet, there haven’t been any breakthroughs that would lead us past the “brute force statistics” approach that is embodied in deep learning.
“We are lagging in basic understanding of how the brain works,” Kaufmann told Datanami earlier this year. “If we crack the brain code, I think we can build an artificial brain.”
Xiao and other data scientists are waiting for that inspiration to lead to better models of human intelligence that could eventually lead us to real AI. Because deep learning certainly isn’t going to lead us there.
“Jeff Hinton, who’s pretty famous and well known in the industry, basically said we’ve kind of hit a roadblock where back propagation doesn’t really simulate the human brain,” Xiao says. “We need someone to make a breakthrough and actually come up with a computational method that’s more similar to how the brain operates.”
Related Items:
Why Cracking the ‘Brain Code’ Is Our Best Chance for True AI
Machine Learning, Deep Learning, and AI: What’s the Difference?
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States