

September 27, 2017
Iguazio, the Anti-Hadoop, Goes GA

Iguazio’s crusade against the Hadoop ecosystem’s complexity and sluggish performance reached a milestone today when it announced the general availability of its unified data platform. The vendor also revealed that Grab, a Singaporean ride-hailing firm, replaced its AWS-based real-time decision-making engine with Iguazio.
Lots of people complain that the Hadoop ecosystem of tools is too big, complex, and slow to meet their needs. You may have met a few people in your big data adventures who are genuinely confused about where to go next and what to do. But Asaf Somekh, founder and CEO of iguazio, is unlike most technologists in this field, in that he’s actually doing something about it.
“I believe what we’re doing is quite different than the others,” Somekh tells Datanami. “Many other [vendors] are focusing on just the extraction layers and the ability to harden [Hadoop distributions]… But they’ve been doing that for many years and the complexity didn’t go away. When you have so many repositories, no matter how you harden it, no matter how you package it, and especially in these environments where the data keeps growing, something eventually breaks.”
Iguazio has taken a fundamentally different tact with flagship product, dubbed the Unified Data Platform, which runs atop commodity Intel servers. The offering sports NoSQL, stream processing, object, and file-based APIs to allow customers to process their data using an array of open source technologies, such as Spark, H2O, Tensorflow, R, and Presto. This allows customers to take advantage of advances in big data processing without requiring them to move their data to different repositories.
And by extending its in-memory data model out to NVMe disk drives, the company is able to leverage in-memory data processing speeds while still persisting the data. “It’s like one continuous memory that is running across all these boxes with NVMe devices,” Somekh says. “We’re getting the in-memory speed but the data is persisted. This is a big difference from the in-memory database guys.”
The company, which was founded by former Mellanox and ExtremeIO engineers and which recently raised $33 million in venture capital, is starting to turn some heads in the user and analyst community. Gartner declared it a “Cool Vendor” earlier this year, while 451 Research’s Matt Aslett said: “We have yet to see anything that compares directly to iguazio’s combination of data analytics and cloud architecture.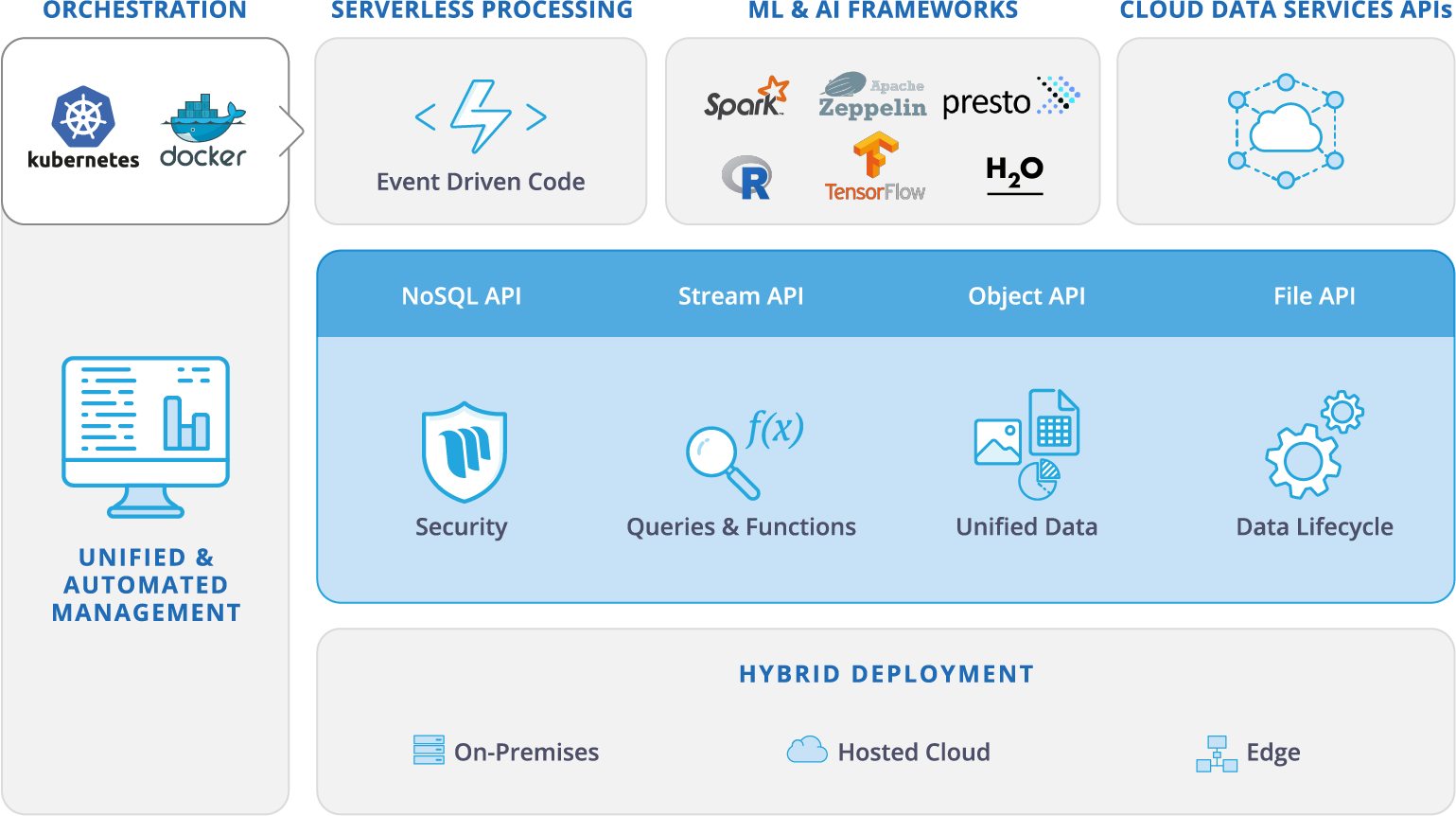
Many of the firms that invested in iguazio’s recent round, including Verizon, Bosch, and the Chicago Mercantile Exchange, are also early adopters of the technology. “This is a great validation of our story,” Somekh says. “These are the people who actually need our platform.”
Another early beta tester that iguazio is turning into a paying customer is Grab, the fast-growing ride-hailing firm based in Singapore. Its mobile app has been downloaded more than 45 million ties, and its network includes more than 1 million drivers across several Southeast Asian countries, making it bigger than Uber there.
That growth has stressed the company’s reliance on several Amazon Web Services, including Kinesis, DynamoDB, Redshift, and Elastic MapReduce (EMR), which is essentially a Hadoop- and Spark-based service that backs its S3 data repository.
While AWS served grab well during the early phases of its growth, the cloud service was hindering Grab’s capability to keep up with the data as it rapidly expanded, Somekh says. As a result, the company migrated several AWS-based applications to iguazio’s data platform, where it got a boost in the speed of real-time decision-making, he says.
Grab now uses iguazio to power several critical systems, including the driver incentive program, the load balancing of drivers and riders in a given area, and surge pricing optimization.
Running the driver incentive program in real time, as opposed to processing the data in batch, allows Grab to give valuable feedback to the drivers and the riders, Somekh says. “They realized that doing it in earl time was more profitable, for drivers and for Grab,” the iguazio CEO says. “It will be beneficial to everybody, the drivers, the company and the riders too.”
The load balancing applications leverages iguazio’s capability to use predictive analatyics to forecast where rider demand will be highest for Grab, and where it needs to position drivers for optimal revenue. “End of workday is the classic case where all taxi drivers are heading to the usual suspect areas where there is lots of demand,” Somekh says. “But at the end of the day, there’s a lot of supply there so even the drivers are waiting for half an hour to get a ride.”
Finally, the surge pricing application is programmed to avoid unfortunate situations where ride-hailing firms enact surge pricing when it should’t, such as during extreme weather events or even terrorist attacks. “So what we’re doing with Grab is basically allowing them to ingest in real time news feeds, weather feeds, and social feds into the platform, into the decision-making algorithm whether to actually do the surge pricing,” Somekh says. “This is another way for them to create a better service for their customer.”
Iguazio replaced several AWS components for Grab, but the ride-sharing company continues to use other AWS services, so iguazio actually co-exists with AWS. Grab stores hundreds of terabytes in its iguazio implementation, which occupies just three X86 servers that are connected to the AWS across high-speed links in a colocation fashion in an Equinix data center, Somekh says.
“In this particular case, were replacing Redshift, we’re replacing DynamoDB, and we’re replacing the Kinesis service for all these use cases,” Somekh says. “The data is actually streamed directly into our platform. Instead of having the data sit in those three different repositories, it’s all running in a single iguazio repository.”
Grab gets better performance with iguazio with less code and complexity, Somekh sys. “When you work against a single repository, the complexity of the query goes dramatically down,” he says. Instead of “pages and pages of code, with iguazio it all boils down to just a short amount of code, because of the fact there is so much less data movement and so much less correlation and querying of separate repositories.”
It’s true that Grab could probably have built its own system using open source tools, and found a way to get the performance that it needed, either on-premise or in a cloud. That’s essentially what Uber has done here in the United States with tools like Hadoop, Spark, and Kafka.
But not every company has the resources to hire the sorts of data scientists and data engineers that are required to build their own data pipelines. That’s the essential message of iguazio: we’ve done the hard work for you.
“We’re working with customers who have not dreamt that they’ll be able to work with AI and machine learning,” Somekh says. “If you’re Google or Ebay or Facebook or Uber, yes you can do it. But if you’re smaller player or a mainstream enterprise, you have no chance today. This is what we’re trying to do: to reduce the complexity and make it consumable for mainstream enterprises. All these manufacturers who are dying to build an IoT platform and they couldn’t do it. With us, we see people who couldn’t spell Spark before, using it.”
Related Items:
Iguazio Re-Architects the Stack for Continuous Analytics
How Uber Uses Spark and Hadoop to Optimize Customer Experience
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States