


April 18, 2017
Iguazio Re-Architects the Stack for Continuous Analytics

When it comes to modern big data architectures, you will typically find lots of different components, engines, and moving parts, each of which tackles part of the problem. One vendor with bold vision of re-architecting the stack with a more streamlined approach is Iguazio, which is building a singular product based on Flash that delivers continues analytics on big and fast data.
Iguazio was founded in 2014 by a pair of technology veterans from Mellanox and ExtremeIO (since acquired by EMC) who were intrigued by the prospect of merging big data processing techniques with emerging storage and containerization technologies. While status quo technologies, such as those in the Apache Hadoop ecosystem, were designed to make the most of spinning disk, then Iguazio would build something from the ground up to work on Flash.
We saw the fruits of this Flash-first approach last year, when Iguazio unveiled its cloud-based offering. Iguazio took a bigger step last month when it unveiled its first on-premise platform at the Strata + Hadoop World conference in San Jose, California. Currently in beta, the on-premise solution is designed to provide customers with a single place to land, query, and serve data using multiple processing engines – all in continuous fashion with lightning-quick speed.
According to Iguazio co-founder and CTO Yaron Haviv, the platform can deliver 2 million transactions per second, with an average of 100 microsecond latency on 99% of transactions. Building the system from the ground with its own entire Flash memory subsystem and scheduler allows Iguazio to offer this sort of performance without adding too much complexity, he said.
“We’re faster than an in-memory database, but we’re using Flash,” Haviv told Datanami at last month’s show. “There’s a trick in how do you make Flash perform like memory and that’s one of the things we’re working on, because if you use the traditional page cache memory, if you treat Flash like a disk, you cannot achieve what we do.”
Iguazio can scale up into the petabyte range by using a Flash twist on the just-a-bunch-of-disk (JBOD) approach
The company says it can store practically any type of data, including objects, files, streams, documents, and tables, in a normalized yet flexible schema. A data-tiering layer keeps relevant data local on the Flash drives, while shuffling seldom used data off to mechanical disks or cloud-based object stores, like Amazon S3 or Microsoft Azure. Iguazio can even break up the individual fields in a database table up, such as a blob file that’s an image, and store them in the most optimal way.
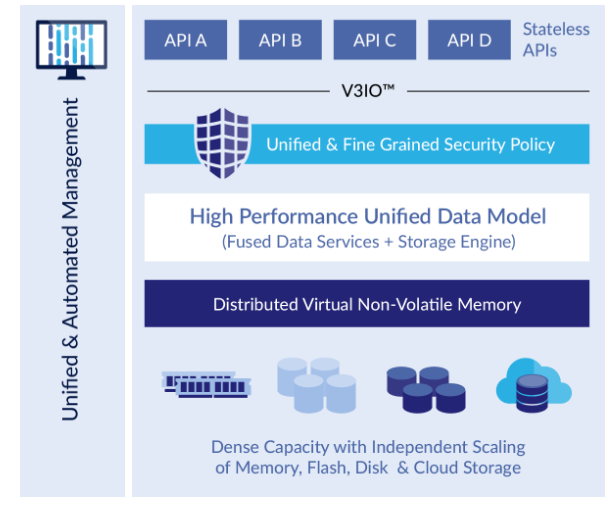
While Iguazio handles the data management, it exposes a variety of stateless APIs to the user to do interesting things with the data. It supports Apache Spark’s DataFrame, Amazon Dynamo, and Presto APIs for data science and operational analytic workloads, while it exposes Apache Kafka and Amazon Kinesis APIs to incorporate streaming data. A Java library lets you connect HDFS into Iguazio, while extensions for Scala and Python open the platform up to a growing population of data scientists and data engineers who prefer to work in those environments.
Iguazio sports multiple data indexers, which enables the data to be optimized for reads or writes, or for random or sequential access. In that respect, Iguazio can function like a key-value database for one type of data, while working as a standard relational database or even an object store for the next. Additionally, the system takes pains to add security, metadata management, and an AngularJS-based visualization component into the mix, thereby eliminating the need for users to “go off the rez” to get these functions.
The heart of Iguazio’s architecture is its V3IO messaging layer, which connects the various other components and lets the whole thing operate like a distributed, fault-tolerant, in-memory database with ACID transactional support. V3IO can run on either 50Gb or 100Gb Ethernet or high performance RDMA networks, and enables the platform to deliver asynchronous and lock-free communication among the various layers in the same node, or even across different nodes, according to the company.
Without V3IO helping to minimize the “inter-layer chatter” of the various pieces on the cluster, the latency of operations would increase substantially, while the throughput would decrease by orders of magnitude. As such, V3IO is key to enabling the system to perform “like one huge and linearly scaling machine,” the company said on its website.
Because it’s so new, Iguazio doesn’t have many success stories yet. But it has several customers who are looking to use it to deliver real-time analytics in a way that Hadoop-based systems were never designed to.
One of Iguazio’s early adopters is a ride sharing company that competes with Uber. According to Haviv, a former Mellanox executive, the company wanted to use Iguazio to do real-time pricing of rides and also to analyze offers.
The traditional approach to solve this problem was to build Parquet files in S3 and analyze them in Redshift, but that approach wouldn’t fly. “It takes them about two hours for them to have the insight from the moment they ingested the data [into Redshift],” Haviv said. “In our platform it takes three seconds. And it performs about 100x faster.”
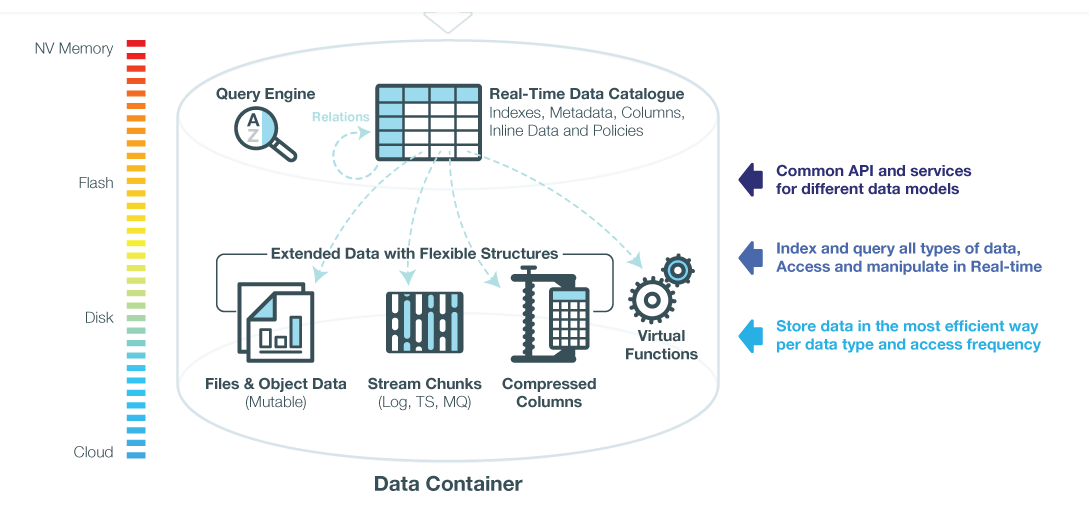
Iguazio stores data in different ways, depending on how it will be used
Iguazio is also being tested by stock exchanges, who are looking to use the system to reconcile trades and to spot fraud. Haviv said one of the IT professionals at a stock exchange said it would take a group of 50 people about two to three years to build what Iguazio did. “Or I can do what you guys did and I can just plug it in and it works,” he said.
Not everybody needs the speed and latency that Iguazio claims to be able to offer. But for a certain class of customer, that performance is the difference between success and failure. While putting the whole operations in the cloud can give you scale, the cloud doesn’t necessarily offer the latencies that many operations demand. Iguazio is finding a receptive audience among “Amazon refugees” who just can’t get the performance they need in the cloud.
Iguazio can help CEO and co-founder Asaf Somekh said that the platform can help enterprises stay competitive by taking a constant flow of fresh data from streaming sources, blending it with previous insights and historical data from multiple repositories, and generating fresh insights viewed from interactive dashboard.
“It’s a complete re-thinking of the traditional data pipeline, where data has been collected into static files and logs and processed later in a multi-stage approach,” he said in a press release.
Related Items:
Meet Ray, the Real-Time Machine-Learning Replacement for Spark
Should Your Analytics Be ‘Real-Time’?
The Real-Time Future of Data According to Jay Kreps
Technologies:
Frameworks
Leading Solution Providers
















