

September 27, 2017
Cloudera Eyes Uniform Data Experience for All

In an ideal world, your compute shifts seamlessly among on-premise, cloud, and hybrid deployment models, and your BI apps have access to the same data as your machine learning and streaming apps. In the real world, however, there are practical roadblocks to achieving those goal. Cloudera inched closer to overcoming those roadblocks with a pair of announcements at Strata Data Conference this week.
The first piece of news out of Cloudera this week is the launch of Altus Data Engineering for the Microsoft Azure cloud platform. The new Altus offering, which officially becomes available next month, lets engineers spin up Cloudera clusters running in the Azure cloud without worrying about the nitty gritty details of managing compute resources in that public cloud environment. Altus is basically an abstraction layer that sits atop the public cloud.
This managed platform as a service (PaaS) offering is basically identical to what Cloudera launched in June, when it debuted Altus for Amazon Web Services. The difference is that this offering targets Azure instead of AWS, says Charles Zedlewski, SVP of Product for Cloudera.
“We’ve had joint customers with Microsoft already, where they take the Cloudera platform and run it on Azure,” Zedlewski tells Datanami. “What we really want to do is have a managed platform as a service on Azure.”
The service provides a uniform experience for Cloudera’s Hadoop customers who have some applications running on premise and some applications running in the public clouds from Microsoft and Amazon (Google Cloud Compute will be the next target for Altus). Nearly 20% of all Cloudera customers run some workload in the cloud, according to Cloudera. Out of all its public cloud customers, half of them run in a hybrid manner, with some clusters on-premise and others in the cloud. And some customers are exploring multi-cloud strategies, too.
“The key thing to note is whether you’re in Amazon or Azure or on bare metal on premise or in a private cloud, in all these scenarios, you’re always, under the covers, fundamentally using the same platform,” Zedlewski says. “It’s the exact same version of Impala, the exact same version of Spark, the exact same version of you name it. All that stuff stays identical. The maintenance window stays identical. Everting else stays the same.”
Once the workload management experience is ironed out, the biggest challenge to supporting these hybrid environments becomes the data movement itself. “Everything else is fairly straightforward,” Zedlewski says. “Practically speaking, the real effort is more about managing the logistics of the data movement. We’re actually doing more work there, but that’s a work in progress.”
The company currently provides functionality to help customers keep data synced between on premise clusters and PaaS clusters in the Amazon cloud, Zedlewski says, and now it’s working on delivering that for Azure too. It will also be working on multi-cloud setups, where data is replicated from one AWS Availability Zone to another, or from AWS to Azure (or to or from GCP in the future).
“The next piece we need to do,” he says, “is we need to do ever better job of helping customers to replicate the data from their analytic applications among these different clouds. So that’s really the only other piece that’s left to do to make this experience as seamless possible for customers.”
The new Shared Data Experience (SDX), Cloudera’s second announcement at Strata Data Conference, will have a role in delivering that.
SDX, Cloudera says, is a suite of tools for building and running multiple analytics applications on-premises and in cloud environments. A key component of that shared experience is unifying the governance and security models associated with the data that these applications are accessing.
“One of the central objectives that most of our customers have had is, whenever you have more than one analytic application, they want the application to share the same data whenever possible,” Zedlewski says. “
Most high-value analytics problems involve different types of processing, and are multi-disciplinary in nature, the Cloudera SVP says. “So a lot of problem are not just BI [business intelligence] problems — they’re BI problems and machine learning problems. Or they’re not just ML problems, but they’re ML problems and real-time serving problems.”
Over the years, Cloudera has built up a framework that makes it possible for multiple applications to operate on the same data, even if the applications reside in different categories. “We’ve basically built out an ability for all these different applications to share not just the same raw data, the same storage, but also share the same schema and also to share the same security,” Zedlewski says. ” So I can secure a column once, and then I have three more applications after that data, and the security doesn’t have to get changed. It gets enforced throughout.”
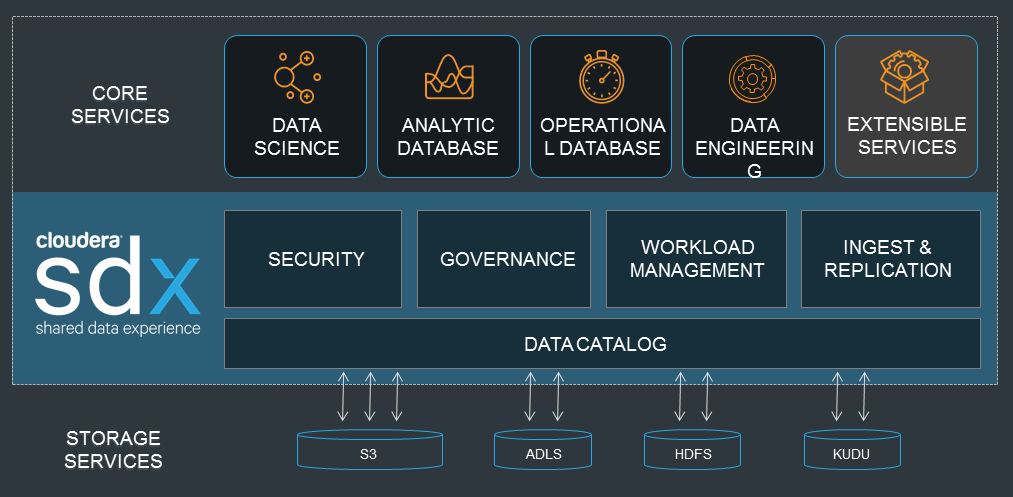
Cloudera’s new SDX unites many aspects of data management on cloud, on premise, and in hybrid environments
That same concept has been extended to other aspects of data, including governance, replication, and management model. “And all that stuff is essentially our shared data experience,” he says. “That’s what makes it possible for our customers to bring multiple applications to the same data, as opposed to have to shuffle data around to different specialty tools.”
The tough part for Cloudera has been delivering that shared data experience when the data is residing in different clouds, or lives across clouds and on-premise enviroments. While an on-prem CDH implementation may use HDFS, an Altus PaaS environment on AWS may use S3 as the data store, while Altus on Azure uses ALDS (Azure Data Lake Store), Microsoft’s object storage format.
“So what we’ve done with SDX is we’ve taken this this framework to allow different applications to share the same data, and we’ve generalized it so multiple Cloudera customers can use the same setup,” Zedlewski says.
By further baking security and governance into the software, it helps close the gap that exists between end-users who demand self-service flexibility and the IT folks who want to lock down data so it doesn’t leak out of the enterprise. SDX helps with two contradictory demands placed on data.
“These two demands have been at odds with each other,” Zedlewski says. “With these changes to the shared data experience, we’re now starting to untangle this so we can give the end user the freedom and flexibility they want, and given the data management team the coherence and control that they want.”![]()
Cloudera has had to stitch together the SDX with its core management tools, including Cloudera Navigator, Cloudera Manager, and Sentry for on-premise and Altus for the cloud. Customers can now spin up all the jobs they want using a combination of on-prem and cloud resources, and rest easy knowing that Cloudera’s software is keeping track of the data permissions behind the scenes.
“We felt that was a necessary step because we want to give user more freedom and flexibility in terms of how they configure different environments in the cloud, and not have to run all the same install of the software,” Zedlewski says. “I can generate more and more workloads with different people doing different things, and they’re all separately logical closers that Altus is handling for you, and in the background, Navigator is watching you and re-assembling the data governance picture for the data steward or compliance team.”
This is a slightly different vision of Cloudera’s original thesis, which perhaps relied on a vision centralized around one giant lake. In reality, life is much more complicated, as customers are spawning multiple data lakes but want thetm to look like one.
“It’s all the things you need to do to make it possible to keep bringing different apps to the same data, as opposed to having to move data to the applications,” Zedlewski says, “but doing it in a loosely coupled, multi-cluster cloud landscape, which was the agile way to go, if you will.”
Related Items:
Cloudera Unveils Altus to Simplify Hadoop in the Cloud
Cloudera IPO Lauded by Big Data Community
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States