

February 17, 2016
Arrow Aims to Defrag Big In-Memory Analytics
via Shutterstock
You probably haven’t heard of Apache Arrow yet. But judging by the people behind this in-memory columnar technology and the speed at which it just became a top-level project at the Apache Software Foundation, you’re gonig to be hearing a lot more about it in the future.
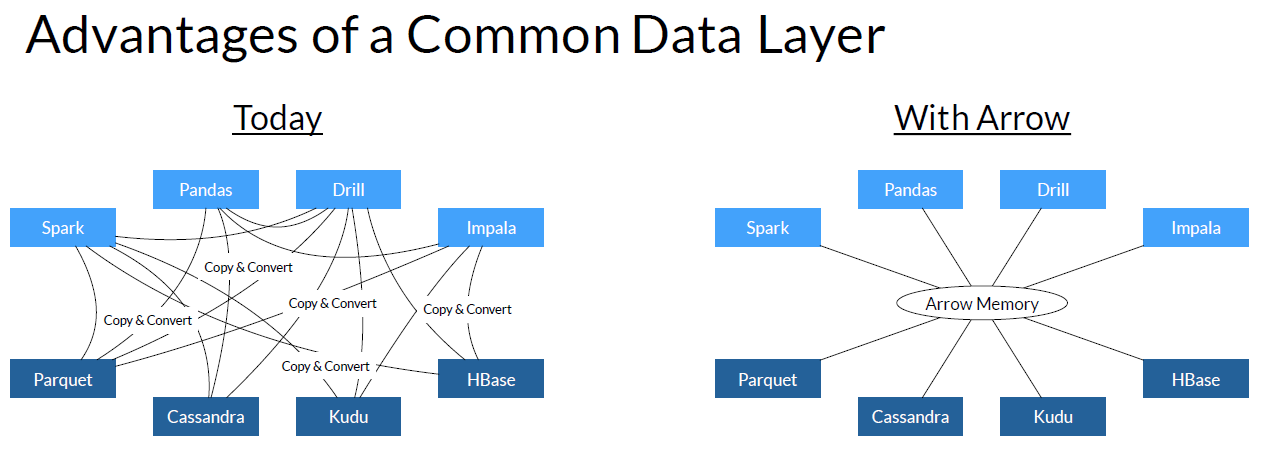
Apache Arrow is a set of technologies that its backers say will not only accelerate analytical workloads on big data systems by a factor of 10x to 100x, but also provide a de facto standard that allows multiple analytic engines—Drill, Impala, and Spark for starters–to access that data without reformatting.
“You can think of it a high-performance accelerator, or kernel, in each of these systems,” explains Jacques Nadeau, the Dremio CTO who spearheaded the development of Apache Drill while at MapR Technologies and is the VP of Arrow. “Arrow is not something that’s replacing these systems. Rather it’s working to accelerate these systems.”
The problem that Arrow ostensibly solves is one that’s bedeviled big data developers for some time: excessive CPU cycles spent reading data from disk into memory and then formatting it for analysis. Current systems waste upwards of 80 percent of available CPU power serializing and de-deserializing data into the proper in-memory format, according to Nadeau.
Arrow is slated to reclaim up to 80 percent of CPU power wasted to formatting overhead
Developers for many big data projects have spent a lot of time trying to speed up this particular function, but it’s difficult and even the smartest big data architectures have solved just portions of the problem. “We started talking to different people in different open source big data projects, and recognized there was a common need,” Nadeau tells Datanami. “The common need was each system, independent of everything else, needs to go faster. So the core strength of Arrow is performance and efficiency of the CPU use.”
By defining a single way that in-memory columnar analytical workload should be processed, and by taking advantage of the single instruction, multiple data (SIMD) instruction sets of modern CPUs, Arrow is able to dramatically speed up in-memory columnar processing by 10x to 100x, even upon complex canonical data structures, such as JSON, says Julien Le Dem, Dremio architect and the creator and vice president of Apache Parquet.
Arrow leverages the SIMD data parallelism in Intel processors
“Because we have a columnar representation and we put all those values together, it becomes possible to do extremely fast processing,” Le Dem says. “The key importance here is to all agree on how we want to do it so we can define it to be highly performant and columnar and be interoperable.”
Arrow is all about performance, Nadeau says, both inside of singular big data systems, but also among multiple engines trying to access the same data. That’s how the typical Hadoop cluster is used—or at least should be used if we’re to follow the dream of pooling all our data in lakes and then accessing them with the engines of our choice.
“Once Drill adopts Arrow as an in-memory representation, then Kudu and Drill can share that data without any serialization or de-serialization costs,” he says. “And one additional thing that’s very exciting about this,” he adds,” is not only can you avoid serialization and de-serialization, if you’re co-located on the same node, you can actually use shared memory and not copy the data at all. That means that you not only reduce your cost to zero, but it also means that you reduce the memory footprint of your workload because you don’t have to hold data in two places at the same time.”
Big data projects currently committed to implementing Arrow as a common in-memory columnar data layer
Apache Arrow is not something that individual users or developers will go out and download or buy. Rather, it’s something that the developers of other big data projects will implement into their code when it comes to processing in-memory columnar workloads. In this manner, Arrow will trickle down into the hands of big data users. That’s why it’s so important to get buy-in from the leaders of other big data projects, and that’s just what Arrow has.
Arrow currently has the backing of 17 PMC members, what Nadeau calls a “who’s who” of big data projects at the Apache Software Foundation. The list includes Cloudera‘s Todd Lipcon, the inventor of Kudu; Cloudera’s Marcel Kornacker, the inventor of Impala; Cloudera’s Michael Stack, the founding VP of HBase, Ted Dunning, the VP of Apache Incubator and the chief application architect at MapR; P. Taylor Goetz, a Hortonworks engineer and the VP of Apache Storm; and Reynold Xin, a Databricks co-founder and a driving force behind Apache Spark.
“You have a number of people who are very involved in these things, and that’s really why it’s becoming a top-level Apache project directly,” Nadeau says. “It’s an exciting group of people getting together.”
Apache Arrow is coming out of stealth mode today with commitments from the leaders of Drill, Ibis, Impala, Kudu, Parquet, and Spark to implement Arrow into those projects by the end of the year. Once word gets out about Arrow, Nadeau expects it to be embedded into other engines and storage repositories, such as Apache Hive and Avro. Work is currently underway to support Arrow with C, C++, Java, and Python, with extensions for R and JavaSript also expected by the end of the year.
The way Nadeau sees it, Apache Arrow solves a big problem preventing big data users from getting full use of their data. And by making it open source, it will help a lot of people. “There’s been fragmentation in the big data ecosystem,” he says. “What’s exciting here is we’re able to bring these people together to focus on a shared goal so we can reduce fragmentation.”
Related Items:
Hadoop’s Second Decade: Where Do We Go From Here?
Distributed Computing Tops List of Hottest Job Skills
Picking the Right SQL-on-Hadoop Tool for the Job
Applications:
Predictive Analytics
Sectors:
Other
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States