

June 5, 2017
Getting Hyped for Deep Learning Configs

As deep learning goes mainstream, early practitioners are finding creative new ways to harness huge collections of unstructured data. But they’re also realizing how critical it is to tune one’s model for optimal performance. As the challenge of tuning what’s essentially a black box becomes more evident, vendors like SigOpt, IBM, and others are stepping up with new solutions to help.
In deep learning, much of the focus around tuning revolves around optimizing the hyperparameters that define how a deep neural network runs. For any given deep learning model, the developer will typically need to set dozens of hyperparameters — such as the number of layers in the network, the number of nodes per layer, the activation function, the training rate, and any feature extraction or pre-processing functions – before they can train the model on the data.
If the training session performed poorly, the developer will tweak some of the settings, and give it another go. This trial-and-error approach can work but is extremely time consuming and offers no guarantees of good results. Considering how common it is to hear about deep learning models running for days or weeks on end, it’s clear that there’s room for improvement on the brute-force approach.
There are several methods data scientists have used that improve this approach to hyperparameter optimizations. The first is a grid search method, which involves going through each variable and trying them one by one in an exhaustive fashion. The random search method brings a little bit more rigor to the practice by sampling hyperparameter settings, while the Bayesian optimization method takes it a step further by using a statistical model to measure the relative success of the model, and to hopefully locate the optimum after a number of runs.
However, these methods still require the developer or data scientist to pay careful attention to all the details, which can be extremely difficult to do, particularly as the size and complexity of the deep learning model increases. With dozens or even hundreds of parameters that must be set, and the potential for parameter settings to impact other parameters, it quickly scales beyond what a single human brain – even one attached to an accomplished data scientist — can manually track.
Enter SigOpt
This is exactly the problem that SigOpt aims to solve with its software-as-a-service tuning service. The San Francisco company, which took third place in the March 2016 Strata Startup Showcase, claims its hyperparameter configuration service can goose the speed of its clients’ neural networks by hundreds of times, while delivering greater accuracy to boot.![]()
SigOpt CEO and co-founder Scott Clark recently briefed Datanami on the company’s API-based service, which is being used to optimize deep learning models in production in financial services, retail, and other industries.
As Clark explains, the idea was to transform academic research on optimal learning that Clark conducted as part of his PhD thesis on applied mathematics at Cornell University into a commercially viable product.
“We’re taking what was very powerful research, but pretty locked up in academia, and democratizing it by bringing it to people behind a very simple API so they can focus on the data, focus on the output, use tools like TensorFlow or MXnet,” Clark says.
After graduating, Clark joined the data engineering team at Yelp, where he helped optimize the advertising system for the publicly traded company. That’s where he got the first taste of the massive scale of modern machine learning systems, as well as the massive complexity involved. He saw the potential for productizing the academic research behind hyperparameter tuning, and SigOpt was born.
“At the high level, it’s called black box optimization,” Clark says. “It’s very agnostic to what’s actually being tuned. All it observes is the inputs and the outputs of some system. You define some configuration that you want to be able to tune, then we start suggesting different configurations to evaluate. You report back how well they do. We learn from that, suggest the next configuration, and repeat.”

SigOpt’s API supports Python, Java, R, and other languages working with TensorFlow, MXnet, and other frameworks
Clark recently worked with Amazon Web Services to showcase the potential savings that hyperparameter optimization can bring to deep learning workloads running on the MXnet framework. According to the May 1 AWS blog post on the topic, SigOpt’s was able to speed up a convolutional neural network (CNN) for a natural language processing (NLP) task by a factor of 100 compared to grid search and 10x faster than the random search method.
Those results were apples-to-apples comparisons for CNN training on a regular CPU. But when you add an NVidia GPU into the mix, the speed advantage shot up to 400x.
So far, the former Y Combinator project has attracted $8.7 million in investments since being founded in November 2014. It’s also being used to optimize production machine learning workloads for real-world companies, including Prudential, Huawei, MillerCoors, and Hotwire.
“We’re seeing the most rapid uptake in the deep learning space because the number of these configuration parameters grows as these methods get more sophisticated,” Clark says. “It also gets more time consuming and expensive as you feed larger and larger data sets into these systems.”
IBM DL Insight
SigOpt hopes to remain in the driver’s seat for hyperparameter optimization, but it will have competition. Google, for instance, is working to automate the tuning of TensorFlow-based worfkflows running on its cloud. The market has also attracted the attention of IBM, which recently unveiled and is currently beta testing a hyperparameter configuration optimization solution as part of its PowerAI platform.![]()
The new DL Insight component of PowerAI can detect hyperparameter configurations for deep neural network models build using TensorFlow, Caffe, and other frameworks, says Sumit Gupta, IBM’s vice president of analytics, AI and machine learning.
“The whole point of deep learning is you don’t need to do the feature extraction. That used to be the problem in machine learning,” he says. “The reason deep learning is becoming popular is the neural network is sort of a black box, and it automatically, if you give it enough data, starts figuring out what the most important features are.
“The hard part of deep learning was you actually have to build a neural network model,” Gupta continues. “So what most people do is use an existing population model, such as Alexnet or Inception v3….So people use an existing model to start, but then you have to tune the weights, the hyperparameters in a model, based on your input data sets.”
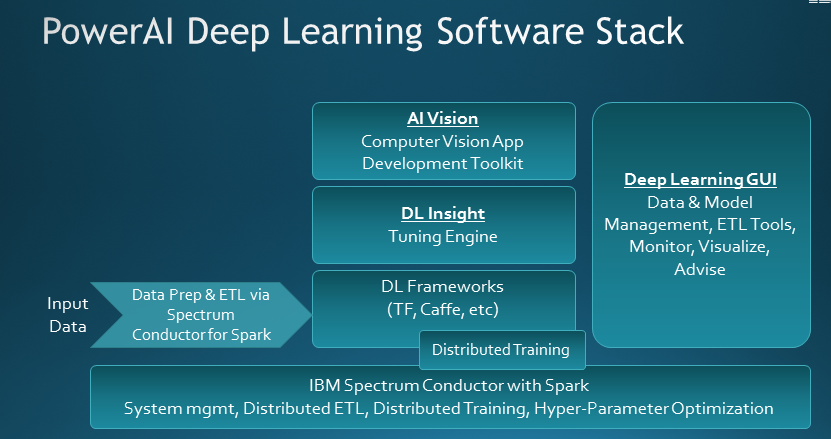
IBM’s hyperparameter configuration tuning software, DL Insight, is currently in beta
IBM’s new DL Insight offering also uses Bayesian search methods to detect optimal hyperparameter settings, Gupta says. “We’re dramatically reducing the training time,” he tells Datanami. “We believe that we can take [training time from] weeks down to hours by using large HPC clusters… We believe this will make deep learning accessible to many more data scientists and make it easier to use.”
As deep learning becomes more mainstream, it will increase the need for related services. Hyperparameter configuration services, it appears, will be one of those tools that data scientists will rely on to avoid falling victim to big data drudgery.
Related Items:
Automation of Automation: IBM PowerAI Tools Aim to Ease Deep Learning Data Prep, Shorten Training
Scrutinizing the Inscrutability of Deep Learning
How Spark Illuminates Deep Learning
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States