

April 4, 2017
Hortonworks Touts Hive Speedup, ACID to Prevent ‘Dirty Reads’

(CYCLONEPROJECT/Shutterstock)
If you’re considering using Hadoop for SQL-based analytics and BI, you’ll be interested in the latest news out of Hortonworks, which today unveiled a new release of its flagship data platform that boasts a fast new release of Apache Hive, as well as a new ACID merge function that can prevent “dirty reads.”
Apache Hive was the main focus of the version 2.6 release of the Hortonworks Data Platform (HDP), which the Santa Clara, California company unveiled today from its Dataworks Summit/Hadoop Summit taking place this week in Munich, Germany.
The big news for SQL devotees in HDP 2.6 is the inclusion of Hive version 2.x, which includes the new in-memory caching features developed under the Live Long and Process (LLAP) project. Hive 2 debuted as a technical preview in HDP 2.5 last year, and is now fully supporting the LLAP version of Hive as a generally available product in HDP 2.6.
Hive 2 with LLaP is a game-changer for those using their Hadoop data lake to support production-level SQL workloads and BI tools, according to Hortonworks CTO Scott Gnau.
“From a performance perspective, we’ve done a lot of work inside of Hive to really enhance overall tactical analytical query performance,” Gnau tells Datanami. “This technology really moves the bar dramatically in terms of what our customers will be able to execute inside of HDP and taking advantage of Hive.”
Specifically, the in-memory caching of LLAP will bolster Hive’s use as a repository and an engine for running tactical analytical capabilities that require sub-second response times, as well as applications that utilize repetitive, high-concurrency SQL queries, Gnau says.
“It’s a really dramatic move forward for the platform and our customer who are taking advantage of SQL on Hadoop,” he says.
Hortonworks has also done work to support ACID functionality in Hive 2 running on HDP 2.6. ACID is a database term that stands for atomicity, consistency, isolation, and durability, and is often used to denote transactional databases that have the highest level of data management capabilities required to support enterprise use.
But ACID concepts are also critically important to enterprise data warehouse (EDW) implementations, says Gnau, who spent 20 years at EDW leader Teradata and says virtually all analytical SQL
databases require ACID compliance.
Specifically, Gnau says the ACID merge function in HDP 2.6 will give Hive users the confidence to know that their data is accurate and ready to be used for high-level decision-making despite the hiccups that inevitably occur in the day-to-day of data operations.
Without the ACID merge function, HDP users would sometimes have to reload their entire EDW or data mart, or risk getting a “dirty read,” he says.
“Sometimes you’ll have post-transactional voids where you want to go update something that’s already been processed, or a sale transaction void out in a store that requires the capability to keep the data consistent without having to write specialized rules to go look for those instances,” Gnau says. “Or maybe you get a transaction more than once, whether it was a streaming transaction, or if a store sent you yesterday’s transaction file by mistake. If you apply that, you can end up double counting if you don’t have this kind of capability.
“That’s what we have done inside of Hive, so users don’t have to go build that functionality themselves,” Gnau continues. “Because it’s inside the Hive engine, not only do we make it easier to have incremental data maintenance and keep track of where everything is, but we can guarantee that it is ACID compliant so there’s never a dirty read and there’s never a point in time when a wrong result would be returned.”
HDP 2.6 also includes Apache Spark version 2.1 and the latest release of the Apache Zeppelin data science notebooks. These features bolster HDP’s position as a platform upon which to do data science work, Gnau says.
“We continue to provide those sophisticated tools as it were for data scientists and data science collaboration, as well as being able to plug into data science work benches and other partner tools that our partners look to deploy,” he says.
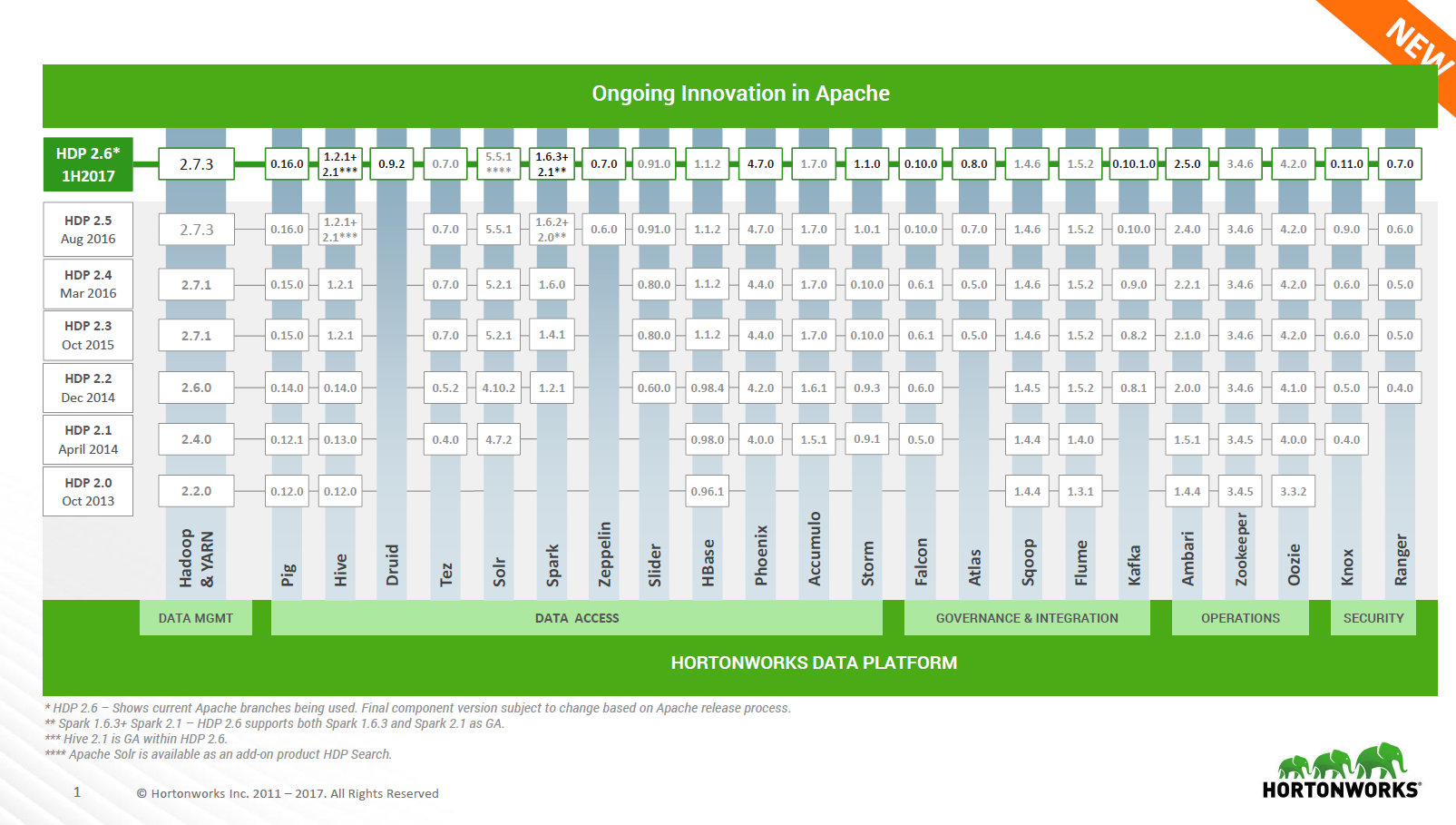
The latest Hortonworks “asparagus chart” shows all the current releases of various Apache projects shipping in HDP 2.6
Lastly, HDP 2.6 offers full support for the Power platform from IBM. While most Hadoop implementations have targeted Intel x86 environments, Hortonworks sees the capability to run on IBM Power as a competitive differentiator.
“Our goal is to give our customers flexibility and choice and support the most popular platform out there, whether it’s on premise, private cloud, or public cloud,” Gnau says. “If they’ve chosen Power as their platform, then this is just another choice for them, and hopefully a better choice.”
Gnau characterizes HDP 2.6 as a “major minor” release. It’s major in terms of the features it brings, but minor in terms of the impact to HDP as a whole and the amount of testing customers would have to endure to ensure that it doesn’t break other production apps running on HDP.
“You’d want to upgrade to 2.6 if you want to depend on Hive LLAP, full ACID merge, and the new Spark. Full stop,” he says. “If don’t want those new capabilities, then you might wait for 3.x.”
Related Items:
Hadoop at Strata: Not Exactly ‘Failure,’ But It Is Complicated
Hortonworks Shares Vision of Connected Data Planes
Hortonworks Splits ‘Core’ Hadoop from Extended Services
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States