

March 1, 2016
Hortonworks Splits ‘Core’ Hadoop from Extended Services
Hortonworks today announced a major change to the way it distributes its Hadoop software. Going forward, Hortonworks plans to update “core Hadoop” components like HDFS, MapReduce, and YARN just once a year in accordance with guidance from the Open Data Platform initiative (ODPi), while “extended services” like Spark, Hive, and HBase get updated continually throughout the year.
Hortonworks‘ adoption of two separate release schedules for its flagship Hadoop distribution, called the Hortonworks Data Platform (HDP), was made in response to increasingly dense test and release cycles. With more than 20 different Apache Software Foundation (ASF) projects going into HDP, it was becoming difficult for the vendor to ensure that each of the components was fully tested against all the others. And it was also causing concern among the customer base.
Ensuring compatibility among an escalating number of Hadoop components was one of the main reasons that Hortonworks co-founded the ODPi a year ago. The Santa Clara, California company, along with Pivotal Software and IBM, are the main backers of the ODPi, while Hadoop competitors’ Cloudera and MapR have questioned the need for its existence.
Hortonworks’ new release cycle begins with today’s launch of HDP 2.4. The company says it plans to hook the release of the three core Hadoop components (HDFS, MapReduce, and YARN) to the ODPi’s once-a-year release cadence. Apache Zookeeper, while not a “core” Hadoop component, will also be updated once a year, per the ODPi.
Everything else that gets included with HDP—Spark, Hive, HBase, Ambari, Tez, Solr, Pig, Slider, HCatalog, Oozie, Sqoop, Mahout, Flume, Phoenix, Accumulo, Storm, Falcon, Kafka, Cloudbreak, Knox, and Ranger–will get updated on a continual basis.
Tim Hall, Hortonworks’ vice president of product management, elaborated on the change in an interview with Datanami
“It’s of a refinement on our release strategy,” he said. “A couple of years ago [the ASF projects] were all introducing a vast amount of innovation every three to six months, so our release cadence was essentially about that. We’d release HDP two times per year, and that allowed us…to bring in all the latest innovation form all these projects.
“What’s happening now that we’re getting to a level of maturity with Hadoop core, which is YARN and HDFS, that customer are running more mission critical workloads on top of that layer and they don’t want to take that upgrade churn. They want to make sure they’re running their business and have stability at that level. At the same time they’re asking for the latest greatest innovations for the extended services that sit on top of that layer.”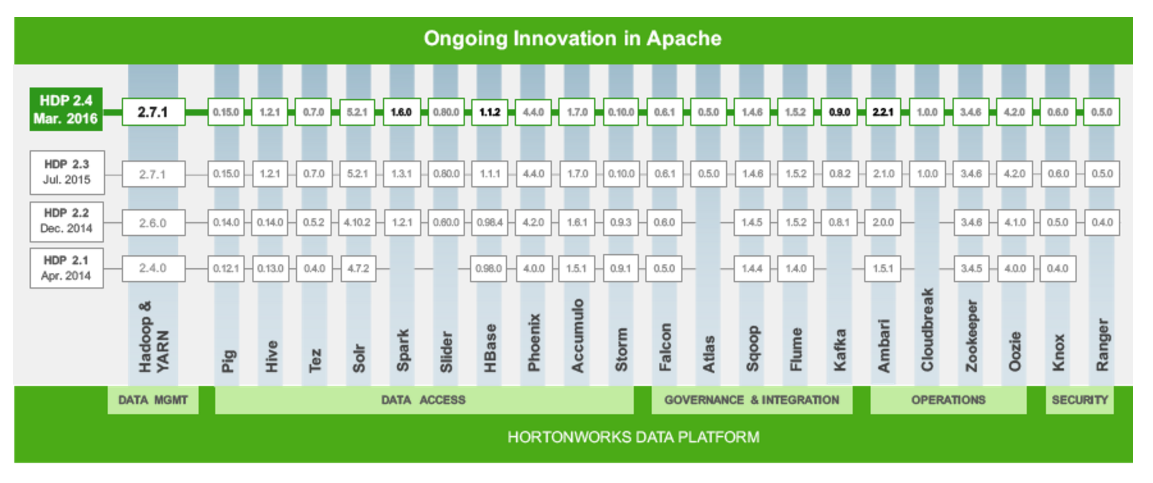
Hortonworks plans to release updates to Hadoop core once per year, and those release will get a new version number. So HDP version 3 will ship in 2017, and HDP 4 will ship in 2018. Customers who value stability over innovation will do well to stick with those releases, while customers who want additional innovation can adopt the dot releases, Hall says.
This strategy will also clear up confusion. “Last year Hortonworks ended up shipping four different release of Spark on top of two different HDP lines and that created some confusion for customers,” Hall says. “They were like, ‘Hey I got a maintenance release, but it seems to have a new release of Spark in it. Do I have to take that new release of Spark?'”
Hortonworks says customers are suffering from the same forces in the Hadoop community that led to the creation of the ODPi. “Their requirement turned out to be exactly what we’re hearing from the partners community, which became the fundamental reason for establishing the ODPi–reduce the churn at the core, provide a common cadence and consistency for those core elements, and then allow for variability on the top. That’s essentially what we’re doing.”
The adoption of two-part cadence strategy signals changes to the famous Hortonworks “asparagus chart.” The chart, which was a diagram depicting which iterations of various Hadoop components made it into the company’s latest distribution, well live on, albeit in a slightly reduced form.
In other news, Hortonworks today announced that that the next release of its other main product, Hortonworks Data Flow, HDF version 1.2, will ship by the end of the month. The software, which is based on the streaming analytics technology that it acquired with its acquisition last year of Onyara, also now ships with Apache Kafka and Apache Storm. The company also announced a partnership with Impetus Technologies, the Silicon Valley firm behind StreamAnalytics, that will see some product integration.
Lastly Hortonworks unveiled a new partnership with Hewlett-Packard Enterprise. HPE, as the company is now called, discovered a way to increase Apache Spark workloads that involve shuffling by a factor of 15 by making some changes to memory processing. Hortonworks will help shepherd the changes through the ASF.
Related Items:
Hadoop’s Next Big Battle: Apache Versus ODP
Making Sense of the ODP—Where Does Hadoop Go From Here?
Hortonworks Boosts Streaming Analytics, IoT Plays with NiFi Deal
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States