

December 8, 2015
MapR Introduces Streams to Compete with Kafka

MapR Technologies today unveiled MapR Streams, a new component of its integrated platform designed to move large amounts of data. MapR Streams uses the same publish-and-subscribe technique that underlies Apache Kafka, and is fully compatible with real-time streaming analytics applications such as Apache Storm and Spark Streaming.
MapR built streaming data capabilities into its core MapR platform in response to its customers growing needs for real-time analytic functionality. “Companies are no longer satisfied with reporting functions that tell them what happened,” says MapR’s Chief Marketing Officer, Jack Norris. “Increasingly it’s how do I integrate data analytics into the production data flows so that I can adjust the business while it’s happening. That’s why customers are so excited by this move and why the data proof points we have are so strong.”
MapR Streams is entirely focused with the movement of data, and making that data movement reliable, repeatable, and extensible. Developers work with MapR Streams using the same OJAI API that MapR adopted when it delivered JSON support in a document-based database earlier this year. It doesn’t provide any analytics, which is left up to downstream products like Storm, Spark Streaming, Flink, or DataTorrent (Apache Apex)
“The processing layer is distinct from the data layer, and it’s in the data layer where a lot of inefficiencies lie,” Norris says. “Solving that data layer and providing this converged data platform keeps all the processing above it much simpler and more robust, and can transform in turn the applications that leverage those.”
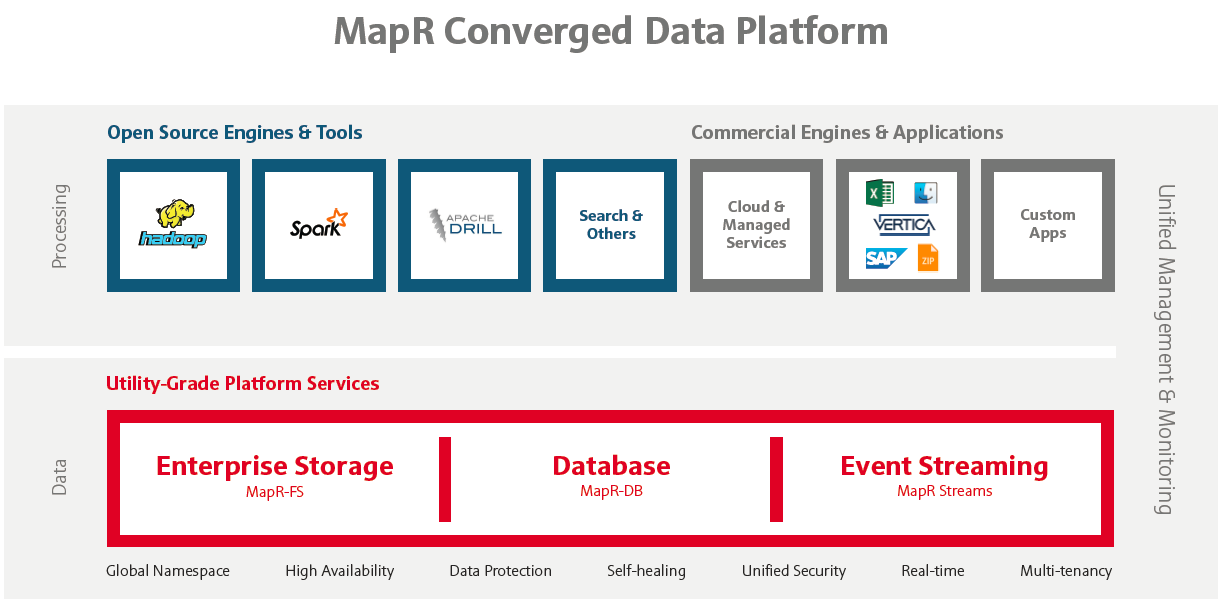
The MapR Converged Data Platform
MapR Streams takes aim squarely at Apache Kafka, the publish-subscribe data streaming software that was developed by Jay Kreps and his team at LinkedIn to handle the huge data flows at that social media site. (Kreps company, Confluent, today unveiled a new release of its commercial Kafka product.) Kafka has grown rapidly over the past two years as big data streaming analytics gained steam.
However, while some Hadoop distributors include Kafka with their distributions and there are some points of integration between Kafka and Hadoop (including at YARN), Kafka itself isn’t a “native” Hadoop application, and Kafka clusters are typically separate from Hadoop clusters. MapR hopes to exploit that separation by delivering MapR Streams as part of a “converged” data platform that combines Hadoop, a NoSQL database, and now real-time streaming.
“When we’re talking about convergence, it’s taking data in motion and data at rest and challenging the assumption of everyone else in the industry that it has to be separated,” Norris says. “We’ve converged that into a single platform. You don’t need to have a separate cluster dedicated for data at rest and a separate cluster dedicated for data in motion.”
MapR hasn’t been shy about seeing Hadoop as a starting point for its distribution, but not an end. The company eschews the Hadoop Distributed File System–which has weaknesses in write-intensive operations and those involving lots of small files–in favor of its own MapR file system, which can handle large numbers of writes and small files. Its NoSQL database layer, MapR-DB, combines key-value store, wide-column, and document store capabilities.
Putting a streaming data component next to these file system and NoSQL database access methods will give MapR customers powerful new capabilities, says Will Ochandarena, the company’s director of product management. “It’s more about putting all the systems into the box. It’s about having a single source of truth and well integrated components with each other,” Ochandarena tells Datanami.
Having a separate data streaming cluster, as Kafka typically is, adds complexity and more potential points of failure, he says. “The data comes in via streaming, but it’s really a matter of how fast can you shovel it out to some other system that can serve as your system of record,” Ochandarena says. “You always have to worry about, is my shovel up, is my shovel reliable.”
In many ways, this is a continuation of the Hadoop message, which has always been about filling massive lakes with data, and then bringing different compute engines to work on that lake. If Hadoop, indeed, is the ultimate data repository, then it may make sense to have the big data streaming system integrated with Hadoop.
Having it all integrated is necessary for some of the things that customer want to do, Norris says. “If you look at what organizations are trying to do, it’s not possible or it’s very complicated to do it with separate silos of information,” he says. “If you’re getting sensor data form all this industrial equipment and if you’re looking for a certain signal that indicates a potential part failure, then understanding that this part may fail in the next week and doing real-time database transactions such as when was last maintenance record, where is the latest part in the system, how soon can we schedule that etc.–Having all of that in one system collapses that response.”
Trying to pass data among separate systems could be a “nightmare,” Ochandarena says. “So this end to end application has a streaming component, has a database component, and it has an analytics component,” he says. “It would be a nightmare to tie through three systems, work out how to secure each one individually with its own security model, move data back and forth, versus have a single platform that supports all of those in a cohesive well-integrated manner.”
“I don’t think it’s an exaggeration to say this is the most significant announcement to hit data in decades,” Norris says.
MapR Streams will be available in early 2016 to all users, including MapR Community Edition, which is free, and the MapR Enterprise Edition, which adds multi-data center replication and high availability capabilities.
Related Items:
MapR’s Top Execs Sound Off on Hadoop, IoT, and Big Data Use Cases
MapR Gives Hadoop Distro More NoSQL Smarts
MapR Targets Hadoop’s Batch Constraints with 5.0
(feature art courtesy Anteromite/Shutterstock.com)
Vendors:
MapR
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States