

May 19, 2015
Apache Drill Poised to Crack Tough Data Challenges

It’s been three years in the making, and today the Apache Drill project announced that version 1 of the eponymous tool is ready for business. MapR Technologies, which develops Hadoop and NoSQL database software, wasted no time adding it to its software stack, and declaring war on fixed schemas everywhere.
Apache Drill is revolutionary in the way it allows users to explore, visualize, and query large and diverse data sets, particularly semi-structured data generated on the Web and via machines. Instead of hammering a given piece of data into a fixed schema using ETL or MapReduce routines and then querying it with a SQL engine like Hive, as first-gen big data practitioners were apt to do, Drill’s capability to discover schema on the fly empowers users go right to querying the data, through standard SQL no less, without first taking its shape or schema into account.
The folks behind the Apache Drill project designed the tool, which is modeled after Google‘s Dremel, to address the rapid proliferation of data stored in JSON-style documents.
“Drill introduces the JSON document model to the world of SQL-based analytics and BI,” Apache Drill vice president Jacques Nadeau says in the Drill 1.0 announcement. “The architecture of relational query engines and databases is built on the assumption that all data has a simple and static structure that’s known in advance, and this 40-year-old assumption is simply no longer valid. We designed Drill from the ground up to address the new reality.”
MapR is presenting Drill as a flexible big data power tool that can replace other products, including ETL software for adding schema to less-structured data, and Hive or Impala for running SQL (or SQL-like) queries against that refined data. Drill’s optimizers essentially are continually scanning data and identifying the data structures on the fly, which is something that traditional ETL and SQL engines can’t do.
“The important thing is it’s schema-less, in that it doesn’t require schema to be defined. It discovers schema on the fly,” says Jack Norris, the chief marketing officer at MapR Technologies. “You look at JSON records. They’ve got the schema contained within in the document, so it’s basically deriving that on the fly and organizing it so that you can query it successfully.”
Drill enables a very different data exploration and query process than what has taken place up to this point, where large and diverse data sets are sampled and normalized until existing SQL tools can work on them. “It’s very different than other approaches where you kind of sample the data and flatten it out and then say, ‘This what I’m assuming is in the file, and if there’s any nested structure, I just kind of ignore it,'” Norris tells Datanami.
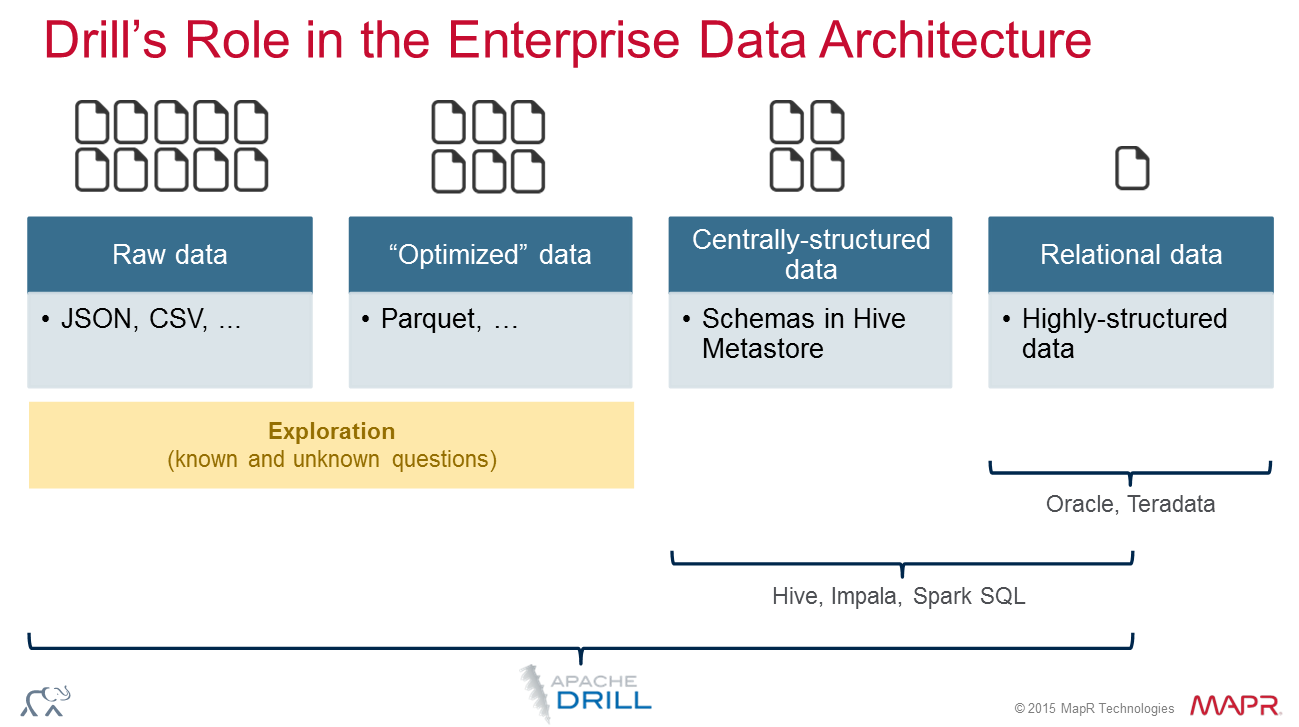
Apache Drill lets users explore and query complex, schema-less data using standard SQL
By comparison, Drill can handle the nested structures contained in JSON documents. In fact, it was designed to handle them. “It is the only columnar execution engine that supports complex and schema-free data, and the only execution engine that performs data-driven query compilation (and re-compilation, also known as schema discovery) during query execution,” Apache Drill’s Nadeau says. “These unique capabilities enable Drill to achieve record-breaking performance with the flexibility offered by the JSON document model.”
Norris sees Drill helping MapR customers–particularly large organizations in the financial services, healthcare, security, and government fields–to solve what’s known as the “Day Zero” problem.
“What they’re interested in is not the speed of the query on data that’s a day or two old. They want to have queries on data as it’s arriving,” Norris says. “That’s really what Drill helps address, that day zero issue, because you don’t have the extraction and transformation and load process that’s determining the correct schema and context of the data so end users can query it successfully. You can query that data, and explore it as it arrives.”
Because Drill uses ANSI SQL, analysts can become productive with it quickly. The open source software includes the Drill Explorer interface, which will be helpful for visually exploring the data in an interactive manner. Users requiring more advanced BI capabilities will be happy to know that, thanks to its support for plain vanilla SQL, it’s a fairly simple matter for existing business intelligence tools from Tableau, Qliktech, SAS, Microstrategy, and TIBCO to tap into Drill and begin exploring large vats of JSON and other semi-structured data sources.
Tableau and Qlik are among those champing at the bit. “Apache Drill closes a gap around self-service SQL queries in Hadoop, especially on complex, dynamic NoSQL data types,” says Mike Foster, strategic alliances technology officer at Qlik. “Drill’s performance advantages for Hadoop data access, combined with the Qlik associative experience, enables our customers to continue discovering business value from a wide range of data.”
“Apache Drill empowers people to access data that is traditionally difficult to work with,” says Jeff Feng, product manager for Tableau. “Direct access within a centralized data repository and without pre-generating metadata definitions encourages data democracy which is essential for data-driven organizations. Additionally, Drill’s instant and secure access to complex data formats, such as JSON, opens up extended analytical opportunities.”
Drill includes its own parallel execution engine that makes it a natural fit for Hadoop clusters, where large and diverse data sets like JSON files are often housed. But it’s worth keeping in mind that there is no dependency on Hadoop, and Drill can run elsewhere, including NoSQL databases. This will increase the analytic repertoires for the document-based NoSQL database stores, such as those from Couchbase, MarkLogic, and MongoDB. MongoDB, in particular, already stores data in BSON, a close relative of JSON, so it seems certain you’ll be hearing more about Drill integration with MongoDB in the near future.
The enterprise use cases for Drill are starting to trickle in. Cardlytics, a provider of consumer purchase data for online and mobile banking, has been using Apache Drill for the past six months, with good returns so far, according to CTO Andrew Hamilton. “Its ease of deployment and use along with its ability to quickly process trillions of records has made it an invaluable tool inside Cardlytics,” Hamilton says. “Queries that were previously insurmountable are now common occurrence. Congratulations to the Drill community on this momentous occasion.”
At the end of the day, Drill appears poised to fill a gap in the emerging big data stack, and enable organizations to continue adapting to the data being generated today. “This announcement is opening up this data exploration that’s not really being met at all today,” MapR’s Norris says. “It’s not necessarily dictating that they throw out exiting process. It’s more about making sure they have the tools to get the job done.”
Related Items:
How Advances in SQL on Hadoop Are Democratizing Big Data
MapR Puts Apache Drill into Hadoop Distro
Dremel Builder Gets $7M for SQL-Based Supertool
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States