

May 7, 2015
What Police Can Learn from Deep Learning

Police departments are increasingly turning to predictive analytics to help them fight crime, and the early returns are positive, with double-digit drops in crime rates reported in many cities. So what’s next? According to big data analytics experts, police departments could spend their time and money more effectively by giving deep learning algorithms a role in the dispatch room.
There are many factors that go into crime and crime rates. Despite what you may hear on the TV news, crime rates are down substantially from their peak in the early 1990s, a trend that’s been attributed to everything from President Clinton’s 1994 Violent Crime Control Act and the prison-building boom to a ban on lead-based paint and even Roe V. Wade.
While crime rates are down, there is still more crime in the U.S. than other industrialized countries. And we continue to spend large sums to maintain law and order. Consider that, in 2007, taxpayers in 50 states spent nearly $100 billion to staff 18,000 local and state law enforcement agencies, and spent another $100 billion-plus on courts and prisons, according to the Justice Policy Institute.
In this era of budget cuts and bankrupt municipalities, there are clearly improvements that can be made in how police do their jobs. One way to boost the effectiveness of police departments is to optimize how they respond to crimes. This is the approach that big data analytics firm H2O is hoping to take.
Recently, H2O data geek and community hacker Alex Tellez shared with Datanami how a type of machine learning technology dubbed deep learning can be brought to bear on community policing. To demonstrate the approach, Tellez built a deep learning model that aimed to predict which crimes would most likely lead to an arrest.
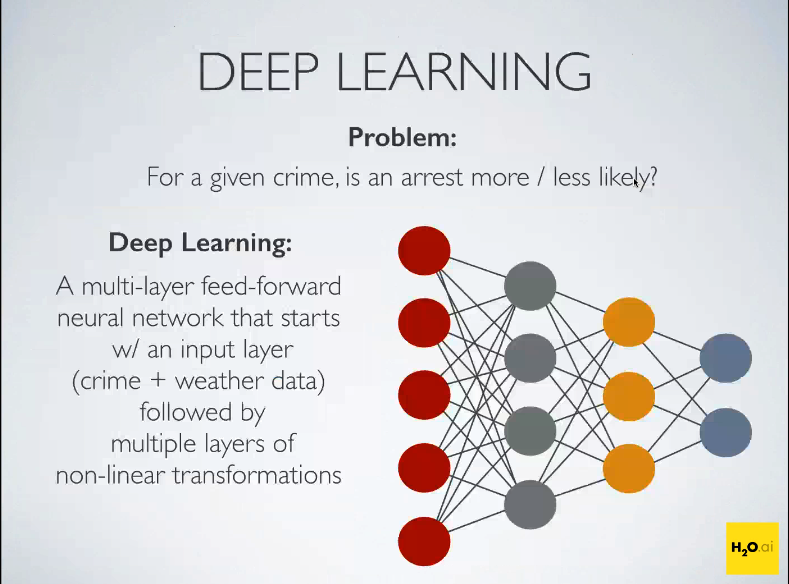
Deep learning aims to find the non-linear connections between a given input and output
Tellez started his quest for arrest optimization by amassing a historical database of crimes that took place in two cities with “open data” policies, Chicago and San Francisco. Those crime databases included the time and place of the crime, the type of crime, and whether an arrest was made. He then munged those data sets with two additional data sets that are known to have an impact on crimes–the weather and socioeconomic status.
After extracting certain features from the data and then using Spark SQL to create a big joined table, Tellez applied H2O’s deep learning algorithm to it, with the hopes that it could tease out some non-linear patterns hidden within the data.
Tellez trained his algorithm against 80 percent of the data–which in the case of Chicago corresponded to 3.5 million crimes going back to 2001–and then used the remaining 20 percent to validate the model. He tested the accuracy of the model using an area under the curve (AUC) chart, and found that his Chicago model was 91 percent accurate. In San Francisco–which had crime data going back to 2003 but no socioeconomic data—the accuracy rate was 95 percent.
“What this essentially means is we’re able to predict whether a given crime will lead to an arrest or not with a really high degree of accuracy,” Tellez says. “If I’m the city of Chicago and you’re telling me I can bag the bad guy with a high degree of confidence, then maybe I would consider sending two policemen out there instead of just one.”
The Chicago Police Department, of course, is already on the cutting edge of big data crime fighting. The city has been widely criticized for how it uses graph theory and predictive techniques to create a so-called “heat list” of 400 citizens who are most likely to commit crimes. The CPD initiated an outreach program to warn the people on the list of the ramifications of committing crimes, which some civil rights groups say is going to too far.
H2O is not interested in going down the “Minority Report” rabbit hole of having government engaging in crime prevention on an individualized level. Instead, it’s hoping to help police optimize how they respond to crime after it’s already happened. As Tellez sees it, this type of deep learning can help police departments get the most crime-fighting bang for their buck.

The 2002 movie “Minority Report” serves as a warning of the danger of the government’s use of prescriptive analytics
“If I’m a dispatcher and somebody explains the crime and I know what the weather is that day and I know what the socioeconomic factors are for that particular region, then I can generate a prediction very quickly that says ‘This crime is going to lead to an arrest with a likelihood of better than 80 percent,'” he says. “You can set up rules to where, if it’s a high percentage, then let’s throw police at it. But if it’s at the low end, 50 percent to 70 percent, then let’s not divert people to it. This is a really great way of resource management, because we clearly don’t have enough police to go around for every single crime.”
Algorithms, obviously, cannot replace the hard-won knowledge that experienced dispatchers, lieutenants, and patrolmen bring to their profession. But there is a growing realization among police departments that data analytics can be a force multiplier and save money at the same time.
H2O’s software hasn’t been adopted by any police departments at this time. In the meantime, Tellez is working to expand his model by applying it against crime statistics for other cities, like Dallas, Boston, Phoenix, and Austin. The idea is to create an ensemble model that averages out the arrest patterns across half a dozen major U.S. cities.
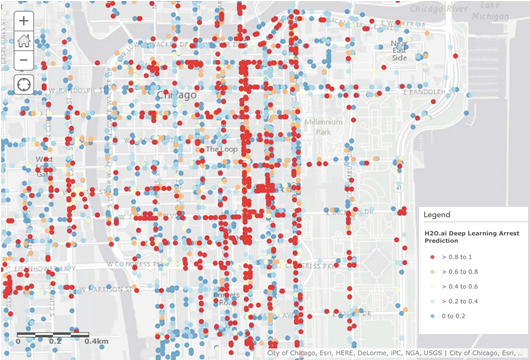
Crimes in Chicago have a geographic element to them that can be serve as an input for deep learning algorithms
He’s also looking to expand beyond those three data points and incorporate other factors that play into the crime equation, such as the existence of sporting events or concerts in cities. Data from Twitter or other social media outlets could help the algorithms sense the general sentiment of a given city at a given point in time.
“For this problem, it turns out that deep neural networks work really well. This is just a good way for us to apply-non linearity to a problem,” Tellez says. “The beauty of deep learning is it’s able to figure out what those unique patterns are, and most certainly we can bring in other data sources.”
Related Items:
Outsmarting Wine Snobs with Machine Learning
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States