

May 6, 2015
Wanted: A Plug-In Architecture for Hadoop Development
Hadoop is hard. There’s just no way around that. Setting up and running a cluster is hard, and so is developing applications that make sense of, and create value from, big data. What Hadoop really needs now, says former Facebook engineer Jonathan Gray, is a plug-in architecture that hides technical complexity from developers.
Silicon Valley is full of big data veterans like Gray who know their way around Hadoop and the myriad of projects and engines that make up the Hadoop stack today. The Valley is home to Internet giants like Facebook, Google, Twitter, and Yahoo, which makes it a great place to be if your business needs that kind of talent and experience. It’s no wonder that so many data analytic and SaaS startups are in the area bounded by Berkeley, San Francisco, and San Jose–big data’s “golden triangle.”
But not every company lives by The Bay, and not everybody is an expert in HDFS, MapReduce, YARN, HBase, and Hive. While the Hadoop stack and adjoining projects like Spark, Storm, Kafka, Mesos, Flink, and Cassandra continue to evolve at breakneck speed, it’s becoming increasingly harder to find the people who have the development skills needed to stitch a big data app together.
“It’s hard to find Hadoop experts, and when you can, they’re very expensive,” says Gray, who used HBase to help develop the Facebook Insights program while employed by the social media giant. “What used to be just Hadoop is now more than 20 different projects. Hadoop means a lot of different things, and as the use cases for Hadoop evolve and the number of projects explodes, the onus put developers and on enterprises keeps going up and up.”
Keeping Up with the Hadoops
While Hadoop distributors like MapR and Cloudera do a good job of packaging together the various Hadoop components and certifying that they work together, it’s still the developer’s job to actually build something useful with that technology.
“I have to actually understand these individual systems,” Gray says. “I have know what each one does. I have to write against the APIs of each one, and then build integration logic to help them work together. Developers are being asked to do a lot, even with simple tasks.”
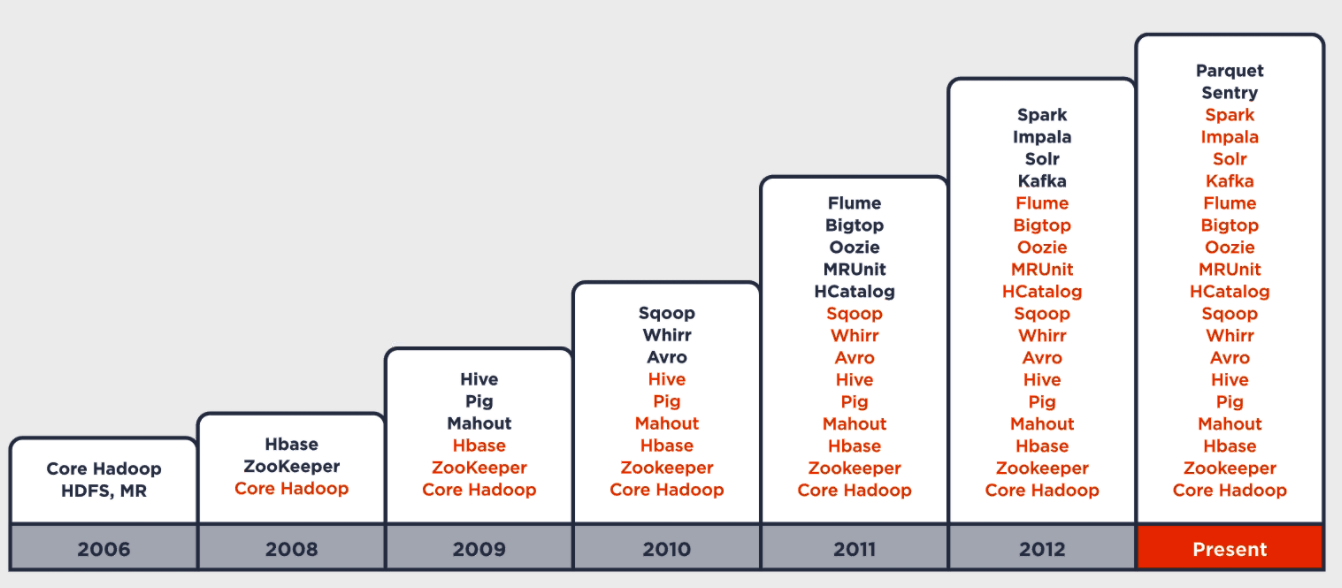
Hadoop today encompasses about 20 separate projects
Gray founded his company, Cask (originally Continuuity), to address this big data development challenge. Cask’s flagship offering is a software product called Cask Data Application Platform (CDAP) that aims to simplify life for developers by eliminating the need to use the individual APIs for all of those Hadoop projects and systems. Instead of learning how each API works, Java developers (and soon possibly Python developers) can leave the low-level API plumbing to the CDAP software, and concentrate on higher-level constructs.
The company has taken that concept to the next level with CDAP 3.0, which it formally launched yesterday. With this release, Cask has introduced the notion of application templates that can jumpstart a big data app development effort.
The first application template included in CDAP 3.0—which is free and open source, by the way–is an ETL pipeline. Building a big data pipeline in Hadoop may sound simple, Gray says, but it actually touches a lot of different engines in Hadoop and may be beyond the capabilities of your average Java programmer.
“Scheduling ETL workloads and pipelines is actually very complicated because you have to use Oozie and Chron you have to write own MapReduce jobs and it becomes a very manual, low-level effort,” Gray says. “So the choice is, do I futz around with a lot of manual work or do I go and buy something like Informatica and put it on top of my Hadoop cluster? Developers don’t want Informatica on top of their Hadoop clusters, so they’re manually doing a bunch of stuff that’s just wasting time.”
Hadoop Skills Shortage
Hadoop may have grabbed the attention of CIOs and CEOs in every industry as an efficient way to crunch big and unstructured data. But many Hadoop projects languish at the starting line for lack of people with the “golden triangle” combination of technical and domain expertise, Gray says.
“A lot of what happens in Hadoop is the time between initial adoption and production can be over a year because people spend a ton of time with basic data enablement tasks,” he says. “So we really want to accelerate that part of Hadoop adoption so people can get to writing apps and innovating on their data more quickly.”
CDAP 3.0 also introduces multi-tenancy capabilities through its namespaces feature. Namespaces are common in the Hadoop world, but it’s the little differences between those namespace implementations that make life so difficult for your Average Java Joe.
“It gets to what’s hard about Hadoop and why CDAP is important,” Gray says. “If you look at namespaces in Hadoop: HDFS supports namespaces, YARN supports namespaces, HBase supports namespaces, ZooKeeper supports namespaces, and Hive support namespaces. But they all have their own way of doing namespaces. There’s no such thing as global namespacing in Hadoop.”
 Obviously, the Hadoop ecosystem cannot continue in this manner. Customers will eventually throw their hands up in frustration and move on to something else. There are lots of standards in the Hadoop world, but that’s sort of the problem: there are too many moving parts, too many low-level APIs, too many standards to learn. That’s one of the reasons that Hortonworks and friends founded the Open Data Platform: to slow down the pace of Hadoop development at the Apache Software Foundation just enough to settle on a (fewer) number of Hadoop family standards that have proven cross-vendor interoperability.
Obviously, the Hadoop ecosystem cannot continue in this manner. Customers will eventually throw their hands up in frustration and move on to something else. There are lots of standards in the Hadoop world, but that’s sort of the problem: there are too many moving parts, too many low-level APIs, too many standards to learn. That’s one of the reasons that Hortonworks and friends founded the Open Data Platform: to slow down the pace of Hadoop development at the Apache Software Foundation just enough to settle on a (fewer) number of Hadoop family standards that have proven cross-vendor interoperability.
Gray isn’t a big believer in the ODP (the Hadoop distributors seem to be doing a decent job of certifying their own releases, he says). But he is a believer in standards, and he believes that, through products like CDAP, the Hadoop world will eventually progress to the point where it can standardize on an extensible plug-in architecture, just as the Enterprise Java world did more than a decade ago.
“What we’re doing is analogous to J2EE,” Gray says. When the Web application server world first started to build in the late 1990s, there were several players, like BEA’s WebLogic and IBM’s WebSphere, building incompatible systems for serving Java-based Web apps. “But eventually a standard emerged called J2EE that each application server implemented.”
Whether CDAP becomes that thing that enables Hadoop to adopt a plug-in architecture–like J2EE did for Web application servers–isn’t known. Since becoming open source last fall, downloads of CDAP have gone up by a factor of 10, Gray says, and Cloudera has taken a stake in the company.
In the end, it’s all about—to quote sL.A. Clippers owner Steve Ballmer—”developers, developers, developers.” Most companies that are playing with Hadoop have developers, Gray says. “But they’re line of business developers, their application or Java developers. They’re more vertical experts, not horizontal distributed system experts,” he says.
We’re at the beginning of a big data application gold rush, Gray says, but the biggest value will be providing picks and shovels to the miners (i.e. developers). “Our team spent the last seven to eight years haggling with Hadoop,” he says. “We worked at these Internet companies and built very powerful applications through a lot of blood, sweat, and tears.
“But our vision is this next wave needs to be better,” he continues. “Companies are not going to have the same time and expertise that these Internet companies had. So if we can accelerate how these applications can actually come to market, we can accelerate big data and accelerate the Hadoop space.”
Related Items:
Hadoop Data Virtualization from Cask Now Open Source
How Facebook Fed Big Data Continuuity
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States