

April 29, 2015
Microsoft Scales Data Lake into Exabyte Territory
Microsoft today announced its Azure Data Lake, an HDFS-compatible data repository designed to store vast amounts of structured and unstructured data for customers who want to analyze or explore it later with their choice of tools. The company also announced a cloud-based data warehouse and a new graph API for MS Office.
Azure Data Lake service is “a nearly infinite data repository that supports petabyte-size files and all types of data,” says Scott Guthrie, Microsoft’s executive vice president of the Cloud and Enterprise group, in a blog post.
Guthrie continues: “Machine learning and big data services from Microsoft, and partners like Cloudera and Hortonworks, are integrated into Data Lake to give developers high-performance ways to store, process, and reason over exabytes of structured and unstructured data to quickly deliver insights to power more intelligent apps.”
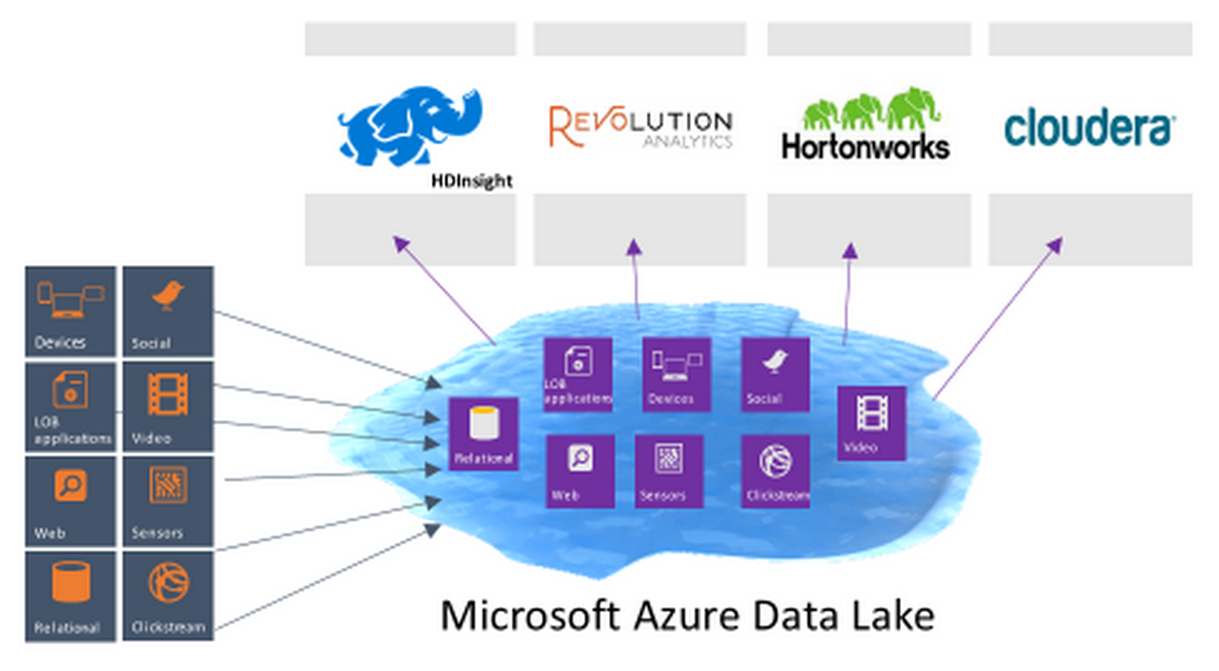
In addition to big files, the Azure Data Lake will allow customers to read and write data with low latency and high throughput, Microsoft says. That will make the solution, which is not yet available, suitable for scenarios like high resolution videos, scientific and medical data, event streams, massive backups, and Web logs and IoT scenarios, the company says on its Azure website.
The launch of Azure Data Lake comes nearly a year after the company launched Azure Machine Learning–which aimed to bring the power of predictive analytics to business analysts and developers who lack the advanced statistical training of data scientists—and less than a month after closing the acquisition of Revolution Analytics, which develops software that parallelizes R routines for execution on Hadoop.
Machine learning is one application that can tap into Azure Data Lake, but it’s not the only one. Since Microsoft is exposing its storage repository with an HDFS-compatible interface, customers will also be able to use it with any Hadoop applications, including related projects like Spark, Storm, Flume, Sqoop, and Kafka, the company says. Revolution R Enterprise, which it obtained with Revolution Analytics, will also be brought to bear against the Azure Data Lake, as will NoSQL, column oriented, and key-value store databases, the software giant says.
Microsoft unveiled its Azure Data Lake service today at its Build 2015 developer conference. It also announced Azure SQL Data Warehouse, a data warehouse service that will be available as a public preview in June. The software will be able to pull data from the Azure Data Lake, and will also integrate with its HDInisight Hadoop distribution, as well as Azure Machine Learning, the Revolution R Enterprise runtime, and Power BI, its big data visualization tool, according to a blog post by T.K. Ranga Rengarajan, who leads leads engineering for Microsoft’s database and big data businesses.
Finally, the company also announced its Office Graph API. According to the company, this API will expose connections and data from the Office Graph, which it describes as “an intelligent fabric that applies machine learning to map the connections between people, content, and interactions across Office.”
Related Items:
Big Data So Easy a Caveman Could Do It?
Microsoft Readies Major Push Into Big Data
Microsoft Spins Up a Machine Learning Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States