

September 29, 2014
Hadoop Alternative Is Faster and Lighter, Proponents Say
For all its benefits, Hadoop has its drawbacks. The actual movement of data can be complex, and does not lend itself to efficient execution. Discouraged with Hadoop’s heaviness, an online advertising company developed and released as open source an alternative called Cluster Map Reduce (CMR) that it says is lighter, faster, and simpler to program.
CMR was developed by Chitika, an online advertising company based in Massachusetts. Chitika was using the Hadoop Distributed File System (HDFS) as the core of its data collection, ad serving, and real-time ad bidding infrastructure. Every day, this geographically distributed network serves 100 million ads, manages several billion real-time bidding events, and collects hundreds of millions events on the Web.
While the combination of HDFS and MapReduce jobs worked, Chitika’s IT team thought it could do better. The first order of business was adopting the Gluster file system for its analytical data warehouse. Among the reasons the company cited for adopting Gluster were greater data availability (no need to rebalance after adding a node); faster data streaming (via 40Gbps Infiniband instead of 1Gbps HTTP); POSIX compliance; and separation of storage and compute components.
The company was happy with Gluster, but it needed a way to bridge the new Gluster cluster with its existing MapReduce version 1 jobs it had running in its Hadoop cluster. So Chitika turned to glusterfs-hadoop, a shim that Red Hat contributed to open source. As the company worked with the shim, it realized that it was missing a few things (specifically around access control), so it made modifications that allowed MapReduce jobs to operate on Gluster in a multiuser environment.
The mods worked well enough, but as the Chitika developers dug into the Hadoop code, they were surprised by what they found. “In particular, the path through Hadoop that data takes is complex, going in and out of Java many times,” Chitika developers wrote on their blog. “Basically, input data is read into Java, then given to the mapper whose output is then consumed by Java, then written to disk, where Java on another node reads it back in to give it to the reducer, whose output is then consumed by Java once again before it is written back to disk.”
Instead of continuing to work around these Hadoop limitations, the Chitika development team decided to roll its own system, which, as you may have guessed, they call Cluster Map Reduce. CMR essentially provides a Hadoop-like framework for running MapReduce jobs in a distributed environment. Chitikia wrote CMR primarily in Perl, thought there are a few elements written in C “where CMR gets close to the metal,” the company says.
“The crux of CMR,” Chitika developers write, “is that it simplifies the movement of data through the analytical back end, minimizing the dependencies and potential points where the data pull process may slow or stop altogether. This, along with the more visible user accessibility advances, comprehensively improve day-to-day data analytics operations, especially within large data environments.”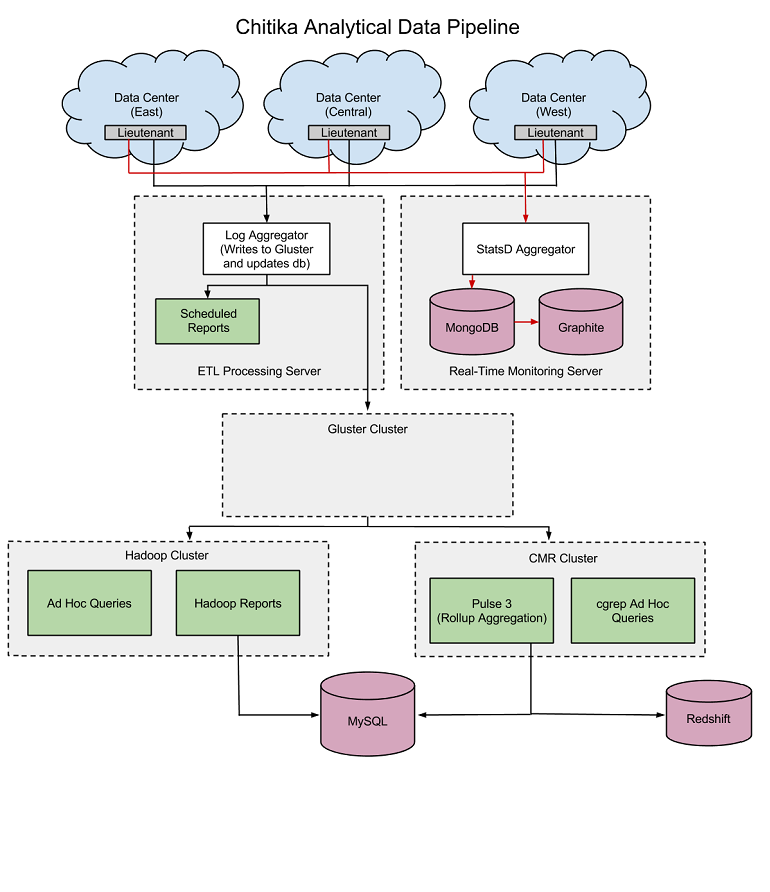
A given CMR job consists of three components, including a language-agnostic mapper; a language-agnostic reducer, and data in the form of input files. The company has created two wrappers, cget and cgrep, which it says completely eliminates the need to write mappers or reducers. The cget wrapper, in particular, provides a SQL-like interface that will be familiar to many users. While it’s not as full-featured as something like Hive, there are Chitika employees who interact with CMR almost exclusively through cget.
The company has adopted CMR for its own activities, and found that it offers five main benefits over Hadoop, including:
- Faster query execution due to complete separation of framework from data flow;
- More straightforward query construction and granularity;
- A much lighter footprint than Hadoop (Normal daemon operations each consume less than 50MB of residential memory);
- Greater ability to customize future iterations, in Python, Perl, or other langauges.
- Client-side resilience to failures in server nodes.
CMR makes much better use of the available hardware than Hadoop and HDFS, the company says. “One of our Hadoop clusters totaled 24 nodes. Replacing Hadoop with CMR allowed the same workload to be completed by only three of those nodes,” representing an 87 percent boost in efficiency, say two lead members of the CMR building team, Paul Laidler and Matt McGonigle, principal data infrastructure engineer.
“Many of the performance benefits seen in our environment are a result of CMR’s interaction with Gluster, which has been specifically designed to avoid patterns where the file system ends up being a bottleneck,” Laidler and McGonigle tell Datanami. “For Chitika specifically, CMR has substantially improved the utilization of the hardware available in our cluster, and has been significantly more stable.”
Now that CMR is an open source project at GitHub (https://github.com/chitika/cmr), the whole world can see whether CMR will provide them the same sort of benefit that it brought Chitika. Laidler and McGonigle are hopeful that other big data developers will see the benefits of CMR, and pick up the ball and run with it.
“For other organizations outside of Chitika, there are numerous benefits to having a file system like Gluster in which to store your warehouse,” they say. “In our case, it handles our replication needs and is POSIX complaint file system, which means that all of the tools that can be used on other POSIX file systems are going to work with it. Furthermore, as Gluster has recently been acquired by Red Hat, it too is under active development and hopefully will see more use as it continues to mature.”
It may take a bit of effort to port an existing MapReduce job running on Hadoop to run under CMR. CMR does not have complete feature parity with Hadoop, and some jobs may have to be redesigned or will need to be broken down into multiple jobs within CMR, Laidler and McGonigle are say. With that said, for those big data shops that are not afraid to wade away from the Hadoop shore, CMR could provide a performance boost.
Doug Cutting, the chief architect at Cloudera and the man credited with being the creator of Hadoop at Yahoo, said last year that he expected Hadoop would have competition and would not be the only game in town for running massively parallel workloads on commodity hardware. There are a few alternatives around, but not a lot. With CMR, we have one more.
Related Items:
Hadoop Alternative Hydra Re-Spawns as Open Source
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
Call & Contact Center Expo
 April 24 - April 25Las Vegas NV United States
April 24 - April 25Las Vegas NV United States -
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States
Interesting read