


July 28, 2014
How Spark Helps ClearStory Achieve Data Harmony

When the folks at ClearStory Data set out to build a big data harmonization tool that could automatically converge diverse data streams into a single coherent view for analysis, they figured they’d have to develop much of the underlying technology themselves. Then they heard of the Apache Spark project at Cal Berkeley’s AMPlab, and the rest, as they say, is history.
ClearStory Data was founded several years ago by two high-tech veterans, Sharmila Mulligan and Vaibhav Nivargi, with the idea of building a solution that could give customers a leg up on their data disparity problems. Valuable insights lay hidden in the combination of data from sources like point of sale (POS) systems, social media streams, mobile devices, Dun & Bradstreet, Nielsen, the National Weather Service, the U.S. Census, the Federal Reserve, medical records, and so on.
But the actual practice of blending the data and correctly preparing it for analysis is quite difficult in time-constrained, real-world settings. And when you consider that those insights lose their value when they’re 90 to 120 days old, you begin to recognize the formidable challenge it presents to business professionals and technologists alike.
“We had a lot of experience in MapReduce, which was the best way, or the only way, that existed to process large volumes of data,” says CEO Mulligan, who worked with her co-founder Nivargi at Aster Data, now a part of Teradata. “But it’s very slow and batch based, and it’s just not a viable solution when you’re doing fast-cycle analysis and iterative discovery.”
What the company needed was an in-memory engine that could interface with the Hadoop Distributed File System (HDFS) to process large amounts ![]() of data in timeframes approaching real time. The company was going to build something like that when one of its early investors, Google Ventures, suggested they take a look at a new project called Spark.
of data in timeframes approaching real time. The company was going to build something like that when one of its early investors, Google Ventures, suggested they take a look at a new project called Spark.
“That’s when we started digging deeper into the AMPlab,” Mulligan tells Datanami. “We started looking at it, and got involved early, and that’s when we started putting it under the hood for data harmonization.”
For ClearStory, data harmonization is the process of preparing diverse data types so it can be used for diagnostic and discovery analysis. Before the data can be combined, it needs to be normalized across multiple dimensions. Universal dimensions, such as time, location, and currency, can be handled automatically by the software, while custom dimensions, such as product hierarchies and SKU numbers, are trained using machine learning models.
The idea is that, instead of paying a group of data scientists six-figure salaries to munge and blend data, ClearStory does the hard piece for you. And instead of visualizing the data using a tool like Tableau or QlikTech, ClearStory has that piece, too, providing a fully integrated, soup-to-nuts big data analytics application.
“Instead of wrangling with all that and the granularities yourself, we automate that,” Mulligan says. “The platform does the underlying work of how to blend all the sources in an automated fashion, so you don’t need people in the loop. And the front-end app is really designed for anyone and doesn’t require any technical skill sets.”
Without Spark, the company would have spent millions writing that critical data harmonization layer from scratch. “Spark is pretty critical to how data harmonization functions at this point,” says Nivargi, an expert in high performance data processing. “We needed something that was beyond an SQL execution engine. It was something that was much more iterative and refined than what MapReduce can give us. So we were on our way to building something like this… when we got into this research group at Berkeley, which was doing some really fascinating work….with the capabilities of bringing in lots of data in memory, the expressive power of Scala, the ability to bring in machine learning operations, and data mining. And it was clearly a very natural fit. The open source direction, the roadmap–all of those were perfectly aligned with how we had evolved in this project.”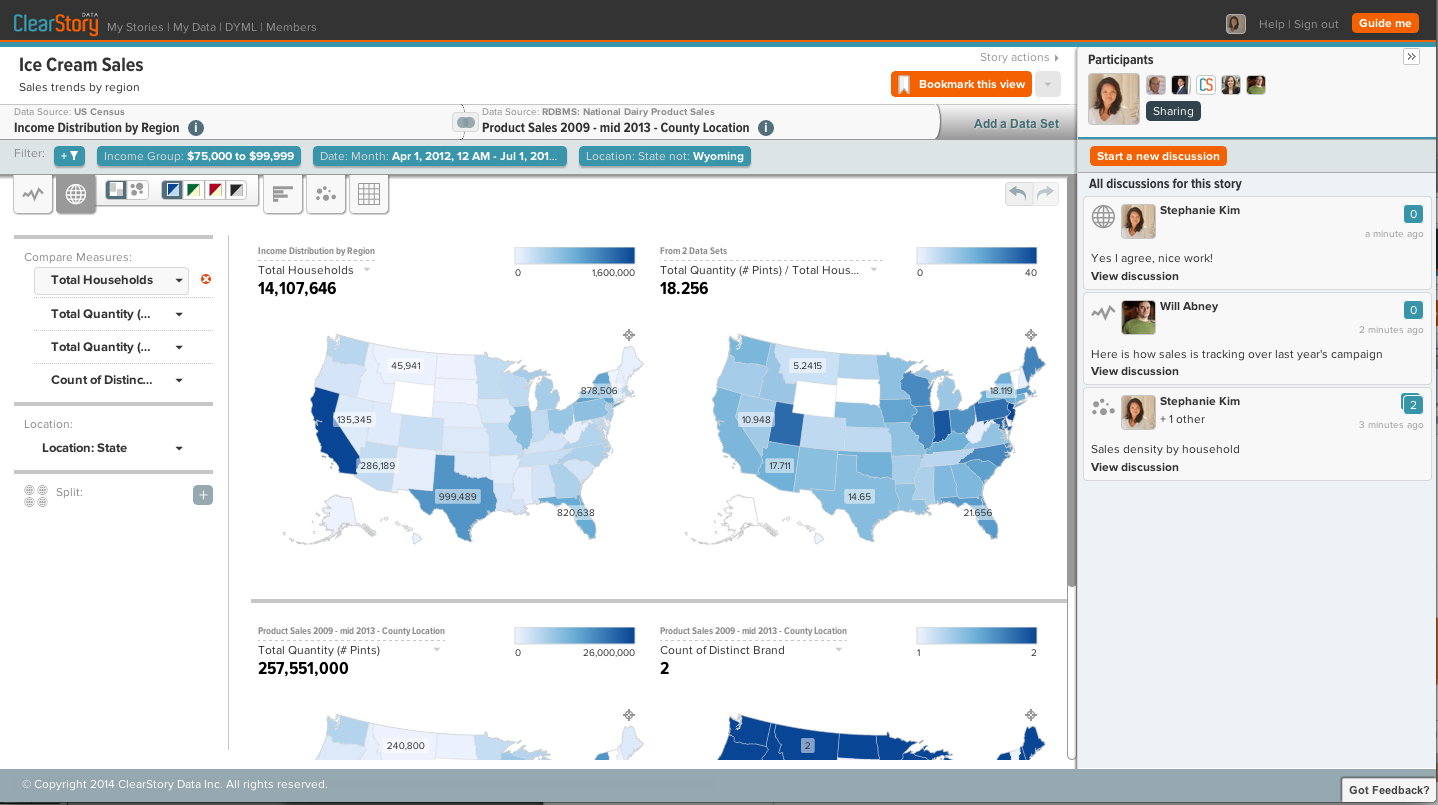
Today, ClearStory is one of the most visible success stories for Apache Spark, which is fast supplanting MapReduce at the core of the Hadoop stack. The Menlo Park, California company has dozens of customers in the consumer processed goods, big box retail, healthcare, media and entertainment, and pharmaceutical industries. To date it has collected $31.5 million in venture funding from the likes of Google Ventures, Andreessen Horowitz, and Kleiner Perkins Caufield & Byers.
Competitive forces are leading ClearStory’s customers to seek insight from any available data. The more sources of data customers add into the cloud-based ClearStory system, the heavier the computational requirements on the Spark layer.
When Mulligan and Nivargi started ClearStory, they thought customers would be happy converging three to five data sources. “What we’re finding is most companies are trying to converge six, nine, 12, 14 sources,” Mulligan says. “Almost every customer we have is up at that level, to the point where our data harmonization product can now blend up to 24 data sources.”
ClearStory is predominantly used by larger companies that often have no control over how their products are consumed. They lean on the availability of big data feeds and ClearStory to give it a clearer story of what’s happening at the point of purchase in the grocery store, the drug store, or the movie theater.
“Before the consumer aspect wasn’t as competitive as things are now,” Mulligan says. “Now these companies at the back of the supply chain are trying to getting a better sense of what’s going on at the end point, and to have enough visibility and data points of validation to go effect intermediaries and the endpoint.”
As data sources are getting bigger and more diverse, the time requirements are shrinking and getting harder to meet. Mulligan sees two factors driving the need for speed in the automation of data harmonization. The first is the cost and tediousness of doing it manually with people. The second is the competitive pressure coming from business itself.
“Because of how competitive it’s become, [companies] can’t really afford to be seeing these insights 60 or 90 days into it. They want to be able to see the insights within the week,” Mulligan says. “We have one company right now that wants to see it within three days, another that wants to see it daily. They’ve never done daily. The whole business is run on 30, 60, 90 cycles….Small swings in market share are very material to their top line and their earnings, so they want to be able to see this quicker cycle so they can take action within the quarter so that it doesn’t’ negatively effect their results.”
Related Items:
Where Does Spark Go From Here?
Apache Spark: 3 Real-World Use Cases
Spark Graduates Apache Incubator
Vendors:
ClearStory Data
Leading Solution Providers
















