

February 5, 2014
Has Dirty Data Met Its Match?
One of the dirty little secrets about big data is the amount of manual effort it takes to clean the data before it can be analyzed. You may have the best and brightest data scientists on your team, but unless you liberate them from the drudgeries of digital janitorial work, you aren’t getting their best work. Today, the data cleansing startup Trifacta launched its first product aimed at alleviating data professionals from the burden posed by traditional data cleansing processes.
![]() The ability to capture and store big, fast moving data is creating new business opportunities in every industry. Organizations that once discarded things like clickstream data, log files, and machine-generated data can now divert that data from the electronic waste bin into Hadoop, and then use MapReduce and other Hadoop engines to mine that data for little nuggets of potentially useful knowledge and insight.
The ability to capture and store big, fast moving data is creating new business opportunities in every industry. Organizations that once discarded things like clickstream data, log files, and machine-generated data can now divert that data from the electronic waste bin into Hadoop, and then use MapReduce and other Hadoop engines to mine that data for little nuggets of potentially useful knowledge and insight.
While it’s relatively easy to get data into HDFS, making sense of the mix of structured, semi-structured, and unstructured data is a huge challenge in its own right. Professionals who work with big data sets often spend up to 80 percent of their time preparing the data for analysis. The typical workflow involves loading the data into Excel or Access, visually inspecting it, identifying the pertinent parts, fixing or discarding the bad pieces of data, and then writing scripts in various language, such as Python or even SAS, to automate the transformation process.
The folks at Trifacta think they have a better way. Today, the San Francisco startup unveiled a product called the Data Transformation Platform that it says will simplify the data cleansing process and get data scientists, analysts, and other users out of the business of hand coding data transformations and into a world of driving transformations visually.
In a nutshell, here’s how Trifacta’s product works:
First, the user downloads a sample of the dataset from HDFS into Trifacta, and opens the data (ASCI or text) in Trifacta’s Web-based interface. The user then begins to work with the data in Trifacta’s interface, including executing transformations on individual fields. The work is very visual, and little histograms above columns provide useful clues about data anomalies further down. As the user works, machine learning algorithms essentially “learn” what the user is doing, and the software uses these to make suggestions. When a user is happy with the transformations in the sample, the software applies the same transformations to the entire data set by generating Pig code that is translated into MapReduce jobs for running on Hadoop.
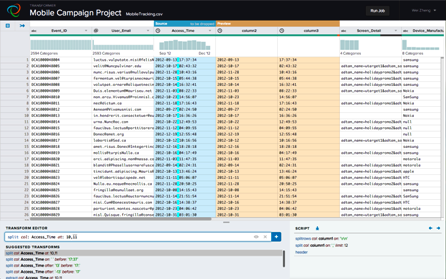 |
|
| Histograms provide clues about the consistency of data in Trifacta’s newly announced tool. | |
The secret sauce is how Trifacta translates underlying data differences into visual clues–what it calls its “predictive interaction” technology–and the overall lightweight nature of the tool. This is especially important when working with data of mixed heritage and lineage, in particular the semi-structured and unstructured data that so many organizations are relying on Hadoop to store and process.
“We do not require you to load data that has a pre-defined schema,” says Wei Zheng, Trifacta’s vice president of products. “We do not require you to have a Hive store or have already HBase or a schema defined. You can define a schema while you work with the data.”
The Trifacta software can essentially “tease out” structure from less structured data, says co-founder and CEO Joe Hellerstein. “People who are dealing with new data sources, such as log files, machine-generated data, and data that comes back from software interfaces–those will have relatively lightweight structure,” he says. “But there’s often a structure embedded in there that we can tease out. So one of the tasks that we help with is structuring data that’s unstructured.”
Beta testers are saying good things about Trifacta and its approach. “Work that would have taken six weeks, now can take as little as a day,” Ravi Hubbly, senior principal architect at Lockheed Martin, said in a statement. “My team has been able to both shorten the data lifecycle and get a better view of the data.”
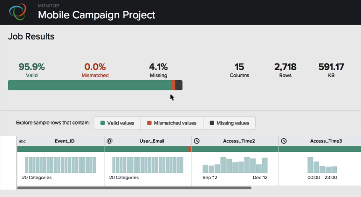 |
|
| Users can see the results of MapReduce-based data transformation jobs generated by Trifacta | |
“With Trifacta, the time needed to be able to wrap your mind around the data is surprisingly low,” an Accretive Health representative said in a statement. “The platform proactively notifies me that there is value in my data set that I might not have seen. The result is a very smooth workflow.”
The idea is to elevate data scientists and analysts out of the drudge work of manually cleaning data. “It gets people out of the bits and bytes of writing code at the low-level and raises them up into a visual domain where they’re looking at previews of the data, and then highlighting things by example in a visualization and the actual content of the data,” Hellerstein says.
Trifacta was founded by Hellerstein, a computer science professor at the University of California Berkeley, along with Jeffrey Heer, a comp-sci professor at the University of Washington, and Stanford University Ph.D. Sean Kandel. The company has collected $16.3 million in Series A and Series B funding.
For a new startup, Trifacta is already well-established in the big data analytics space, and has partnerships with key vendors. It has ties with Hadoop distributor Cloudera and its co-founder, Mike Olson, whom Hellerstein went to graduate school with. Cloudera’s chief scientist Jeff Hammerbacher says that Trifacta’s software “makes data transformation more visual, interactive, and efficient.”
The company has hooks with Tableau Software, whose powerful VizQL technology came out of the same Stanford data visualization program that Kandel was a part of. Trifacta is giving users the option of outputting data directly into a format that Tableau’s tool can use. This is a company worth keeping an eye on.
Related Items:
Automating the Pain Out of Big Data Transformation
Trifacta Gets $12M to Refine Raw Data
Reaping the Fruits of Hadoop Labor in 2014
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States