

October 25, 2012
Cloudera Runs Real-Time with Impala
It’s been an exciting week for the Hadoop community with new developments and tweaks galore, both on the open source and proprietary fronts.
![]() Today the most established of the three major Hadoop distro vendors, Cloudera, upped the ante by throwing a scalable, distributed real-time query engine into the elephant’s sphere.
Today the most established of the three major Hadoop distro vendors, Cloudera, upped the ante by throwing a scalable, distributed real-time query engine into the elephant’s sphere.
The effort, called Cloudera Impala, takes the platform past its batch roots, via an Apache-licensed engine that turns around HDFS and HBase data in ways that few thought Hadoop was capable of.
Impala was the brainchild of Marcel Kornacker, who previously co-architected the query engine for the F1 project at Google. Cloudera stated this week that it is architected around a flexible data model so it can work over more complex data than a data warehouse and is efficient, with interactive queries expressed in industry-standard SQL.
“We believe that the addition of Impala opens up a bunch of new valuable workloads that were previously off limits. It allows our customers to offload their big data warehouse so they can optimize how they invest in data,” said Mike Olson, CEO of Cloudera during our chat with him this week in New York City during Strata Hadoop World.
During our conversation, Olson detailed Impala’s core value for users and the open source ecosystem in general, noting three key factors, including openness, performance and capability for a potentially larger set of coming Hadoop use cases. While Hadoop has always been a strong player in the web and media communities it was designed to serve, he said financial services and increasingly healthcare are the hot areas for the platform. While Impala isn’t a big enough boost to thrust Hadoop into the world of high-frequency trading, he thinks it’s enough of a boost to bolster the high-end risk analysis and management analytics—not to mention a range of new opportunities that will drive everything from next-gen advertising to personalized medicine.
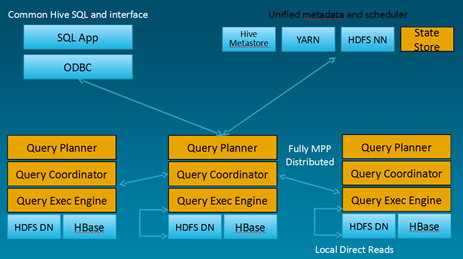
“For the last four years you could run SQL queries on Hadoop via Hive. It would take your query, bust it into MapReduce jobs, farm it out the cluster. You’d hit send and then wait…and wait.” While he says that since much of this work had been impossible before, users were willing to wait that fifteen minutes—two hours—whatever it took. However, to open Hadoop to a whole new, valuable branch of higher performance workloads, they needed to built this new engine or execution layer, Impala, while leaving functionality and expected features in place. “We haven’t removed MapReduce,” said Olson. “We still let you run on the same data (no need to move HDFS or HBase data out), run queries on the same data, including the results, and we leave an in for users to tap the desired tools for the workload.”
Impala has been in development for over two years before it was turned around as a private beta to a few select large-scale customers, including Expedia. If you’ll recall, we recently had a sit-down with the online travel booking giant at the SAS event two weeks ago where we talked about how they’re managing vast, diverse volumes of data on their mid-sized Hadoop cluster. Of course, all of this was before they were able to talk about the Impala angle, but for a company that sends nearly all of its data directly through Hadoop, this has to be a noteworthy addition to their big data arsenal.
According to Expedia’s Director of Global BI and Data Warehousing Platforms, Jeff Prather, the addition of Impala meant his team was “able to work on one single platform for big data rather than many disparate systems for archiving, ETL and analytics.” Prather said that this “evolution of Hadoop has enabled us to reduce our latency by 50% and produce a new real business insight service not previously viable.”
While the company could have easily created this as a proprietary addition to their enterprise-grade services, it is open source, just like the rest of their distro—the proprietary key being their management suite. Olson stressed the importance of open source to their business model, noting that if they went the proprietary route they would face an uphill climb with CIOs who want a pure open system they can move in and out of (and tweak) at will. Besides, as Olson noted, “If you put a petabyte into any system at all, you’re locked into that system. The data has so much inertia that it’s painful to move.”
The CEO said his company puts about half of its engineering dollars behind boosting open source Hadoop, which he said is good for the platform, its users, and even the company’s competitors. “Open source development does another good thing for us,” he said. “It lets us share the cost of the work; I had 50 engineers writing software that we gave away last year but in the community the total population working on Hadoop was well over 500—that’s a 10x addition to your ranks.”
Even though Cloudera preaches the open source, zero lock-in philosophy, this doesn’t mean that they’re taking anti-proprietary approach to their viability as a long-standing company. “We are building towards becoming a software company, not a services and support company” Olson said, noting that hitting the IPO tipping point requires something other than the Red Hat model. The services and support angle provided a useful springboard four years ago to help the company generate awareness, development efforts and new users in the beginning, but that accounts for just under one-third of the company’s revenue now.
The future of the company’s business (and attractiveness for future investment) lies in their subscription-based model, which leverages the company’s Cloudera Manager offering to manage and monitor deployments, in addition to the guidance they offer enterprise customers. The open source implementations the company offers for free are perfectly well-suited to a certain class of users, said Olson, but “when it comes down to truly enterprise-level stuff like setting and hitting SLAs, provisioning new users, setting security policies, handling capacity planning and so forth, then it’s fair game for us to put that in the management suite and fair game to get paid for it.”
When it comes to pitting the other distro vendors against what Cloudera has with Impala and its open source approach, Olson said they have a leg up on the competition. Not only are they the only ones with a real-time query engine, companies like MapR, which has he said “took a chainsaw to Hadoop, cut away the open source storage layer and swapped in their own proprietary file system” are going into this with a flawed business model. Whereas Cloudera is looking to become a software company versus a services and support enterprise, he doesn’t think that MapR’s approach is going to be sustainable for long-term investments. The lock-in issue is a big deal to CIOs, he told us, and despite his stated high regard for MapR’s leadership and engineering team, which he genuinely praised, customers will want assurances that their data isn’t going to be tied up in a bulky proprietary file system when the other distro vendors are producing more stable, reliable and higher performing platforms.
We chatted briefly about the other elephant in the room, Hortonworks, which he stated equal respect for on the engineering and leadership fronts, but dissed them for being too slow to innovate. Olson claims that their current model is equivalent to CDH3, which doesn’t haven’t the robust fault tolerance and stability that the others have managed to add in the meantime.
In the end, says Olson, it’s the difference between UNIX and LINUX. It’s all about openness and that robust community behind an open source effort, which would cost smaller companies a fortune in talent. By giving back, he said, Cloudera receives more than its share in dividends by bolstering the platform, adding functionality, and getting a ready and willing “workforce” to extend Hadoop far past its batch beginnings.
Related Articles
Six Super-Scale Hadoop Deployments
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States