

September 17, 2014
Self-Provision Hadoop in Five Clicks, BlueData Says

Forget the data science–in some organizations, just getting access to a Hadoop cluster is a major obstacle. With today’s launch of EPIC, the software virtualization company BlueData says analysts and data scientists can self-provision a virtual Hadoop cluster in a matter of seconds, enabling them to iterate in a faster and more agile fashion.
If things go as planned, BlueData‘s new EPIC product will usher in a new level of failure for Hadoop users around the world. “If you want to succeed in big data, you need to fail fast and run experiments very fast,” says BlueData CEO Kumar Sreekanti.
The idea is that, by allowing users to spin up a Hadoop cluster in a matter of seconds, try out a model, and discard it just as quickly, BlueData’s EPIC will accelerate the pace of innovation and enable customers to discover how to use big data effectively.
EPIC bundles an open source KVM hypervisor, RHEL operating system from Red Hat, and a cloud management layer from OpenStack. It’s essentially a next-generation VMware layer for big data, an apt comparison, considering Kumar and his BlueData co-founder, Tom Phelan, were both senior people in VMware’s R&D department.
BlueData’s primary goal with EPIC is to provide a cloud-like Hadoop deployment experience for non-technical people. It’s easy to get going with A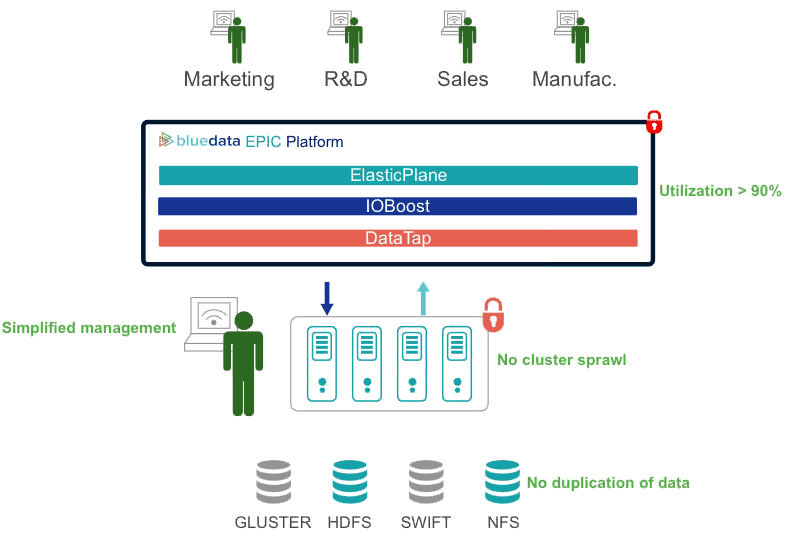 mazon’s Elastic MapReduce (EMR), but many customers are still hesitant to put their data in the cloud. A secondary goal is eliminating cluster sprawl and boosting the CPU utilization of existing Hadoop clusters, which typically hover south of 30 percent.
mazon’s Elastic MapReduce (EMR), but many customers are still hesitant to put their data in the cloud. A secondary goal is eliminating cluster sprawl and boosting the CPU utilization of existing Hadoop clusters, which typically hover south of 30 percent.
“We’re trying to democratize the creation and provisioning of clusters for users. That’s quite hard for you to do in Cloudera Manager,” says Anant Chintamaneni, vice president of products for BlueData. “It’s very rare you would give access to a data analyst or to a business analyst for them to go and provision their own cluster. That’s a very elaborate process. You’ve got to be extremely careful about what you’re doing there because it has all the bells and whistles and knobs and so on. That’s really more for Hadoop administrators.”
BlueData cuts out the Hadoop administrators by effectively automating much of the drudgery that would normally be done to get Hadoop running on bare metal. BlueData has taken a conservative approach to setting the configurations in the Hadoop images that it controls, leaving room for administrators to do their own tweaks to boost production deployments later.
EPIC is all about lowering the barriers to Hadoop adoption and allowing users to self-provision their very own virtual Hadoop clusters, primarily for lower-scale, often exploratory or experimental workloads. It’s about making Hadoop available for everybody, all the time, and maximizing the Hadoop investment in the process.
“A customer came to me and said, ‘Kumar we have a little Hadoop cluster, and it’s almost like a bathroom key in the gas station. I have this guy who wants to run something, but I have to wait for him to come back and give me the key,'” Sreekanti says. “With EPIC, you can create a cluster in a matter of five mouse clicks. You go from the 50,000 mouse clicks it might take you t o build a cluster in three months, to five mouse clicks.”
o build a cluster in three months, to five mouse clicks.”
EPIC is currently certified with the Hadoop distribution from Hortonworks and Apache Spark. While it’s not certified with Cloudera, it’s partnered with the company, and several versions of Cloudera Distribution for Hadoop (CDH) are featured in BlueData’s demo. No modifications are required to be made to Hadoop or to the MapReduce, Pig, or Hive jobs that are running under Hadoop. But due to the way EPIC is automating the deployment process, close collaboration was required with these vendors (and will be required with NoSQL and other big data vendors that EPIC supports in the future).
EPIC has three core components, including ElasticPlane, DataTap, and IOBoost. Analysts and other users will provision their clusters through the ElasticPlane interface, while IOBoost provides application-aware caching and tiering.
It appears that much work went into the DataTap component, which enables users’ virtual Hadoop clusters to access data from remote sources, including HDFS, NFS, Gluster, or Swift file systems. This allows EPIC users to tap into existing Hadoop or Spark setups (and potentially NoSQL databases and other sources in the future) without first moving all the data to the new cluster.
“This gives you faster time to result,” Chintamaneni says. “You don’t have to move terabytes of data into your local HDFS and physical environment. And it gives you better data governance capabilities because your enterprise storage has enterprise-grade capabilities that you don’t have in HDFS.”
There is a small performance penalty to running EPIC, but only for CPU-intensive workloads. For Hadoop workloads that are CPU-bound, there will be a 5 to 6 percent hit due to the extra virtualization layer that EPIC brings. The majority of jobs are not CPU bound, however, so there should be no performance penalty paid with the majority of EPIC customers.
EPIC gives administrators control over what resources users can access, and what resources they’re blocked from using. The software allows admins to create multiple tenants in the Hadoop cluster, and organize them by line of business, departments, or groups of users. Administrators can see exactly what users are running and the resources they’re consuming; they can even start an SSH session to remotely access clusters to start or stop individual jobs. The cluster even retains an individual IP address.
“Even though this is a cluster running in virtualized environment, as far as the outside world is concerned, it looks and feels exactly like a physical cluster,” Chintamaneni says. “We have all the monitoring you’d expect from a physical machine, all exposed through Rest APIs.”
BlueData has already racked up big accolades from early adopters and industry leaders. One of the early EPIC adopters is Orange Silicon Valley, the wholly-owned US subsidiary of telecommunications operator Orange. “Now our data scientists can spin up their own environments within the on-premise Orange Silicon Valley datacenter in a matter of minutes,” Xavier Quintuna, principal big data architect for the company, says in BlueData’s announcement.
Doug Fisher, vice president and general manager of Intel software and services group, says there’s a big gap between the value that organizations believe big data can bring, and the percentage of customers actually deploing big data platforms. “We believe that BlueData offers a big data infrastructure platform with differentiating data virtualization capability to bridge that gap and help proliferate big data adoption within enterprises,” he says in BlueData’s announcement.
BlueData also has the backing of Ion Stoica, the co-founder and CEO of Databricks, the company behind Apache Spark. Stoica joined the company recently as a technical adviser.
EPIC One is available now. It’s a full-featured version of EPIC that’s limited to running on a single node. The enterprise version of EPIC is still in beta and is expected to become available in the fourth quarter, BlueData says.
Related Items:
BlueData Eyes Market for Hadoop VMs
Enforcing Hadoop SLAs in a Big YARN World
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States