

July 11, 2014
Where Does Spark Go From Here?

The excitement behind Apache Spark reached an apex last week during the 2014 Spark Summit put on by Databricks, the company behind the in-memory analytics phenomenon. With a large community of users and growing support from software vendors, the future for Spark certainly appears bright. But there’s a large amount of work ahead to fulfill the promise of Spark, including hardening various components.
Providing an easier-to-use alternative to MapReduce is the first use case for Spark, which is said to run up to 100 times faster than MapReduce. Because developers can program Spark jobs in languages besides Java, like Scala and Python, it will have a wider pool of potential users.
Spark as general-purpose MapReduce replacement is fairly well-established and ready for production, albeit with some caveats. It’s an in-memory technology, after all, so Spark will be able to work on data in the hundreds of gigabytes to the low terabyte range–far below the petabyte-scale batch processing that MapReduce can do.
But the potential for Spark is much bigger than replacing MapReduce, and much of the excitement surrounding Spark comes from its other tricks, including the MLLib machine learning library, the GraphX graph database, Spark Streaming, the Shark SQL interface, and the new SparkR environment, for running R on Spark. Spark aims to provide data scientists with many of the analytic tools they need to build analytic models and explore their data within a single framework, thereby eliminating the need to cobble together multiple tools.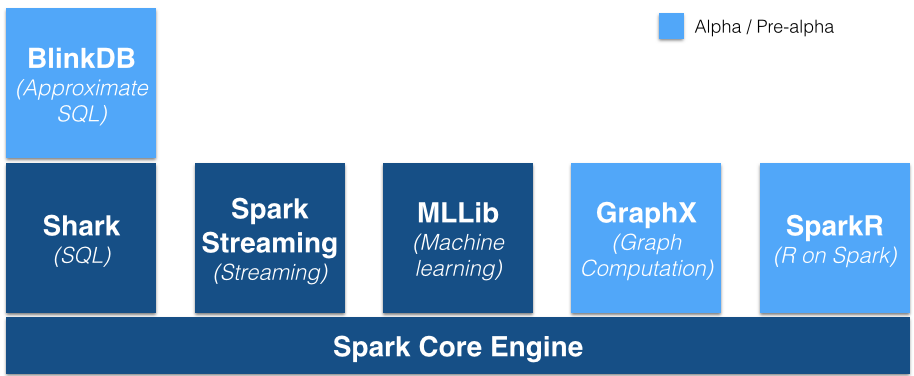
But some of the Spark components–particularly the Spark Streaming, GraphX and new SparkR capabilities–are still too green for enterprise deployments, and will require some hardening before they’re acceptable for the enterprise.
“DataStax isn’t supporting some of the newer Spark capabilities, such as Spark Streaming and Graphx yet,” says Robin Schumacher, vice president of products for DataStax, which is the only NoSQL database vendor distributing Spark in its product. “Instead, it’s encouraging customers to confine their Spark usage primarily to general Spark functionality, Shark SQL, and the MLlib machine learning libraries to a lesser extent. We do have a formal partnership with Databricks, and we will be working with them to roll out additional Spark functionality in an upcoming release.”
It’s worth keeping in mind that Spark 1.0, which was the first GA version of the technology sine the public beta ended, has been out only since May. With all the excitement around Spark, it’s easy to forget how young this technology is. Spark has been in development since 2009. Hadoop, which has been around for barely a decade years, looks like an elder statesman by comparison.
Shaun Connolly, vice president of corporate strategy for Hortonworks, sees parallels between where Spark is now and where Hadoop came from. “It’s not dissimilar to Hadoop in its early days,” Connolly tells Datanami. “MapReduce was the engine, and then you saw things like Apache Hive arrive to give you a scripting language, and Cascading to have a Java developer pipelining framework. We expect to see the same thing happen above Spark. It’s just a matter of what level of maturity and enterprise richness [it develops].”
Hortonworks, which expects to formally support Spark in its distribution later this year, has taken a slower, more cautious approach toward Spark than its competitors. It recently announced that Spark (which is in pre-release on the Hortonworks Data Platform) was certified on YARN, even though Spark has been running on YARN on other Hadoop distros.
That approach differs markedly from Cloudera, which was the first Hadoop company to include Spark in its distribution, a move that was quickly followed by Pivotal, MapR, IBM, and Hortonworks.
![]() Cloudera’s inclination to stake an early bet on Spark shows its willingness to listen to customers, says Denny Lee, who manages the Hadoop cluster at Concur, the travel and expense report management company that we profiled earlier this week. “It’s not like they decided to do the Gazzang acquisition or be earlier supporter of Spark in a vacuum. They’re listening to their customers,” Lee tells Datanami. “They’ve got that really awesome balance between being there for the enterprise, but also being bleeding edge in other aspects.”
Cloudera’s inclination to stake an early bet on Spark shows its willingness to listen to customers, says Denny Lee, who manages the Hadoop cluster at Concur, the travel and expense report management company that we profiled earlier this week. “It’s not like they decided to do the Gazzang acquisition or be earlier supporter of Spark in a vacuum. They’re listening to their customers,” Lee tells Datanami. “They’ve got that really awesome balance between being there for the enterprise, but also being bleeding edge in other aspects.”
The truth is that, while Spark has captured the attention of many big data practitioners, it is still a bit on the bleeding edge. But with a small army of community developers behind it–Spark has more followers than MapReduce, Girpah, Storm, and Tez–it won’t stay that way for long.
The big data software space doesn’t stand still for long, and neither does Databricks, which last week launched Databricks Cloud, a hosted environment that allows developers to get started building analytic pipelines with Spark, without involving Hadoop clusters. The Databricks Cloud is currently in beta, with a GA announcement later this year.
“We are hiring developers as fast as we can–only the highest quality,” Databricks CEO Ion Stoica tells Datanami. “We want to scale up very fast.”
Those developers will be involved with several Hadoop integration projects in the coming months. At the Spark Summit, Databricks announced that it’s working with Hadoop distributors Cloudera, MapR, IBM, and Intel to “standardize” Spark and to establish a way to bring Hadoop engines that previously ran with a MapReduce backend–like Hive, Pig, and Sqoop–to use Spark instead.
The first order of business will be to develop a version of the Hive SQL interface that uses Spark, which the vendors say will significantly improve Hive performance. However it’s not expected that Hive-on-Spark will replace Cloudera’s Impala or other similar efforts to improve SQL access on Hadoop.
Related Items:
How Hadoop is Remaking Travel and Expense Reporting at Concur
Databricks Takes Apache Spark to the Cloud, Nabs $33M
Apache Spark: 3 Real-World Use Cases
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States