

July 16, 2012
Top 5 Challenges for Hadoop MapReduce in the Enterprise
Sponsored Content
Introduction
Reporting and analysis tools help businesses make better quality decisions faster. The source of information that enables these decisions is data. There are broadly two types of data: structured and unstructured. Recently, IT has struggled to deliver timely analysis using data warehousing architectures designed for batch processing. These architectures can no longer meet demand owing to rapidly rising data volumes and new data types that beg for a continuous approach to data processing.
IT organizations need to adopt new ways to extract and analyze data. Existing data warehouses were built for structured data and ill-suited for handling unstructured data types. Firms need to evolve the data warehouse architectures of the past to new architectures able to handle vast amounts of fluid fast moving data that may be structured, unstructured or semi-structured. Pre-processing vast amounts of unstructured data so that it can be loaded into traditional tools is too time-consuming and costly.
Clearly a better approach is needed. Without a flexible and enterprise-class approach to accessing, processing, and analyzing unstructured data, IT organizations will be overrun with data, but will lack the ability to extract meaningful information from that data — this is the ‘big data’ problem.
Current market conditions and drivers
According to the Market Strategy and BI Research group, data volumes are doubling every year:
• 42.6 percent of respondents are keeping more than three years of data for analytical purposes.
• New sources are emerging at huge volumes, in different industries, such as utilities.
• 80 percent of data is unstructured and not effectively used in the organization.
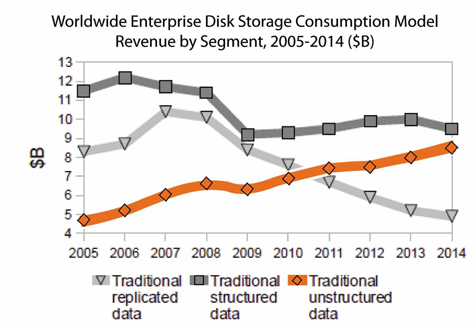
To keep pace with the need to ingest, store and process vast amounts of data, both computational and storage solutions have had to evolve leading to:
- The Emergence of new programming frameworks to enable distributed computing on large data sets (for example, MapReduce).
- New data storage techniques (for example, file systems on commodity hardware, like the Hadoop file system, or HDFS) for structured and unstructured data.
Most of the storage models already exist to support enterprise- class needs. Reliable, flexible distributed data grids have been proven to scale to very large data sizes (petabytes) and are now being offered at an affordable cost.
_____________________________________________
- NYSE is generating 1TB of data per day
- Facebook is generating 20TB of data per day—compressed!
- CERN is generating 40TB of data per day
________________________________________________
Extracting business value from the ‘big data’ contained in these unstructured, distributed file systems is becoming increasingly important. Distributed programming models such as MapReduce enable this type of capability, but the technology was not originally designed with enterprise requirements in mind. Now that MapReduce has been accepted as a working model for extracting value from big data, the next goal is to turn it into an enterprise-class solution. This has been a major focus of IBM® Platform Computing™.
Addressing Enterprise requirements
An enterprise-class implementation of the MapReduce programming model, and scalable run-time environment is desired in order to meet IT customer expectations.
A more capable MapReduce solution should:
- Enable the deployment and operation of the extraction and analysis programs across the enterprise.
- Manage and monitor large scale environments.
- Includes a workload management system to ensure quality of service and prioritization of applications based on business objectives.
- Service multiple MapReduce users and lines of businesses, as well as potentially other distributed processing needs.
- Provide flexibility to choose the right storage/file system, based on the specific application need.
Five challenges for Hadoop™ MapReduce in the Enterprise
Lack of performance and scalability – Current implementations of the Hadoop MapReduce programming model do not provide a fast, scalable distributed resource management solution fundamentally limiting the speed with which problems can be addressed. Organizations require a distributed MapReduce solution that can deliver competitive advantage by solving a wider range of data-intensive analytic problems faster. They also require the ability to harness resources from clusters in remote data centers. Ideally, the MapReduce implementation should help organizations run complex data simulations with sub-millisecond latency, high data throughput, and thousands of map/reduce tasks completed per second depending on complexity. Applications should be able to scale to tens of thousands of cores and hundreds of concurrent clients and/or applications.
Lack of flexible resource management – Current implementations of the Hadoop MapReduce programming model are not able to react quickly to real-time changes in application or user demands. Based on the volume of tasks, the priority of the job, and time-varying resource allocation policies, MapReduce jobs should be able to quickly grow or shrink the number of concurrently executing tasks to maximize throughput, performance and cluster utilization while respecting resource ownership and sharing policies.
Lack of application deployment support – Current implementations of the Hadoop MapReduce programming model do not make it easy to manage multiple application integrations on production-scale distributed system with automated application service deployment capability. An enterprise-class solution should have automated capabilities that include application deployment, workload policy management, tuning, and general monitoring and administration. The environment should promote good coding practices and version control to simplify implementation, minimize ongoing application maintenance, improve time to market and improve code quality.
Lack of quality of service assurance – Current implementations of the Hadoop MapReduce programming model are not optimized to take full advantage of modern multi-core servers. Ideally, the implementation should allow for both multi-threaded and single-threaded tasks, and be able to schedule them intelligently with a view to maximizing cache effectiveness and data locality into consideration. Application performance and scalability can be further improved by optimizing the placement of tasks on multi-core systems based on the specific nature of the MapReduce workload.
Lack of multiple data source support – Current implementations of the Hadoop MapReduce programming model only support a single distributed file system; the most common being HDFS. A complete implementation of the MapReduce programming model should be flexible enough to provide data access across multiple distributed file systems. In this way, existing data does not need to be moved or translated before it can be processed. MapReduce services need visibility to data regardless of where it resides.
A compatible enhanced approach
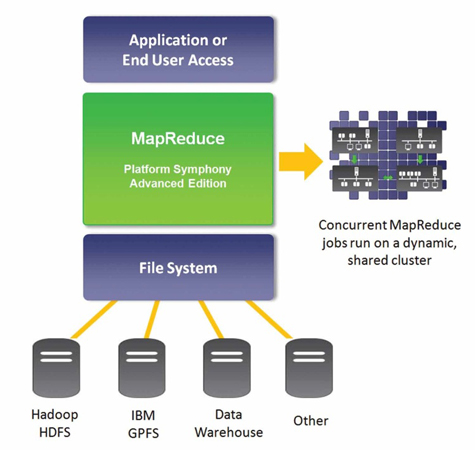
IBM Platform Computing’s MapReduce approach is to deliver enterprise-class distributed workload services for MapReduce applications. It meets Enterprise IT requirements when running MapReduce jobs, delivering availability, scalability, performance and manageability. The server is designed to work specifically with multiple distributed file system technologies, avoiding customer lock-in and enabling a single MapReduce solution across the enterprise.
IBM® Platform™ Symphony Advanced Edition supports an enhanced MapReduce implementation fully compatible with existing application architectures. It can support multiple programming languages, multiple data and storage technologies and it has a rich set of API’s including a fully-compatible Hadoop MapReduce API. This makes it easy to integrate third-party and layered big data tools so that they can take advantage of the more scalable and reliable Platform Symphony infrastructure.
MapReduce is a core capability of IBM® Platform™ Symphony Advanced Edition. Its enterprise-class capabilities include the ability to scale to thousands of cores per MapReduce application, to process big data workloads with high throughput, to offer IT manageability and monitoring while controlling workload policies for multiple lines of business users, and it has built-in high availability services to ensure the necessary quality of service.
For more information
To learn more about IBM Platform Computing, or IBM Platform Symphony, please contact your IBM marketing representative or IBM Business Partner.
Related Articles
Architecture of an Enterprise Class MapReduce Distributed Runtime Engine
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States