

July 7, 2021
HPE Acquires Ampool to Accelerate Hybrid Analytics for Customers
July 7, 2021 — With the explosion of data and cloud capabilities, enterprises increasingly require data analytics services with cloud-like operations. The Structured Query Language (SQL) continues to be a leading database workload in many organizations. As HPE partners with customers and ISVs to make HPE Ezmeral a target software platform for the full breadth of data-intensive workloads, a clear need has emerged to modernize SQL stack. Current on-premises SQL technologies don’t account for the new requirements around hybrid cloud and scale. As a result, modernizing the SQL stack is at the forefront of analytics transformations, to address the challenges in the hybrid cloud and disparate data space.
![]() To help address this challenge, HPE’s announces the acquisition of Ampool, an innovative developer of a data platform designed to deliver a cloud-native, high-performance SQL analytics engine for data engineers and business analysts. Ampool will join the HPE Ezmeral software organization, and will play a pivotal role in accelerating HPE Ezmeral analytics runtime for interactive SQL workloads, helping to improve quality, repeatability, throughput, and time to value for our customers’ AI/ML, analytics and data-intensive workloads.
To help address this challenge, HPE’s announces the acquisition of Ampool, an innovative developer of a data platform designed to deliver a cloud-native, high-performance SQL analytics engine for data engineers and business analysts. Ampool will join the HPE Ezmeral software organization, and will play a pivotal role in accelerating HPE Ezmeral analytics runtime for interactive SQL workloads, helping to improve quality, repeatability, throughput, and time to value for our customers’ AI/ML, analytics and data-intensive workloads.
Delivering Analytics-as-a-service
HPE GreenLake provides customers with a powerful foundation to drive digital transformation through an elastic as-a-service platform that can run on premises, at the edge, or in a colocation facility. The HPE GreenLake edge to cloud platform combines simplicity and agility with the governance, compliance, and visibility that comes with hybrid IT, and provides a range of cloud services, including HPE Ezmeral Container Platform and HPE Ezmeral ML Ops.
![]() The acquisition builds on this strategy by adding Ampool’s technology components and open source expertise to the Ezmeral portfolio, which will over time turn into a set of SQL acceleration services made available through the HPE GreenLake cloud platform. This acquisition is also further evidence of HPE’s investment, focus and execution toward building out an open-source-based, IP rich capability for the HPE Ezmeral software portfolio, to deliver superior end to end analytics in fast growth markets.
The acquisition builds on this strategy by adding Ampool’s technology components and open source expertise to the Ezmeral portfolio, which will over time turn into a set of SQL acceleration services made available through the HPE GreenLake cloud platform. This acquisition is also further evidence of HPE’s investment, focus and execution toward building out an open-source-based, IP rich capability for the HPE Ezmeral software portfolio, to deliver superior end to end analytics in fast growth markets.
Boosting analytical query speeds at scale
Ampool has built a unique, scalable, data federation layer combined with a multi-tiered acceleration engine to boost analytical query processing speeds at scale. Founded by Milind Bhandarkar, Ampool brings a world-class team of engineers from Yahoo, LinkedIn, VMware/Pivotal, and Veritas. Ampool engineers also boast significant open source leadership with key contributions to projects such as Apache Geode, Presto/Trino, Apache Spark, and Apache Ranger.
The nature of SQL-based interactive workloads have dramatically changed in the last decade. Canned business intelligence and reporting on data warehouses have evolved to more sophisticated ad-hoc analytics at higher scale and more diverse data. Current on-premises SQL tools are rigid, slow, and opinionated to specific underlying storage technology such as HDFS. New innovations are required to address the challenge of high data movement costs, as well as data residency requirements.
Organizations require a set of loosely coupled cloud-native query engines that can support multiple analytics and business intelligence tools against a variety of backend data sources. These sources include file systems, object stores, and data warehouses. This need has been the guiding principle for HPE Ezmeral analytics runtime (see diagram below). HPE delivers rich offerings for cloud-native Apache Spark to support batch analytics for data engineering.
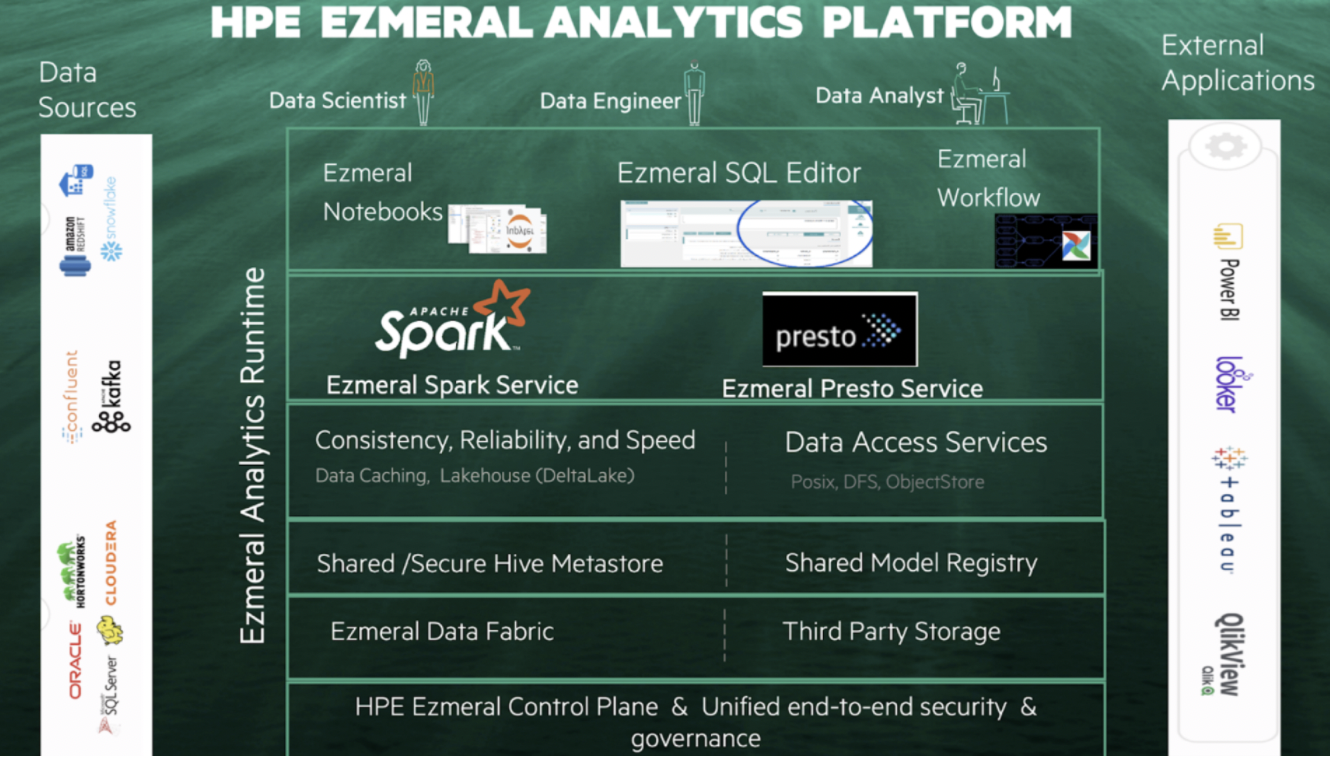
Support SQL runtimes to increase speed
Our next focus area is to support SQL runtimes, specifically open source Presto as well as best of breed ISV products for fast, interactive, ad-hoc analytics use cases. The Ampool team brings open source expertise and technology to provide a caching layer to address speed.
The use of multiple ephemeral container-based SQL compute engines, such as Presto and Spark, introduces the need for persistent metadata to be stored and managed externally. Ampool has deep expertise in building a shared metadata catalog with role-based access control, which provides a consistent view of the different backend data sources.
Source: ANANT CHINTAMANENI, HPE
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States