

January 25, 2023
AWS Announces General Availability of Amazon OpenSearch Serverless
Jan. 25, 2023 — AWS today announced the general availability of Amazon OpenSearch Serverless, the serverless option for Amazon OpenSearch Service that makes it easier to run search and analytics workloads without even having to think about infrastructure management.
 Self-managed OpenSearch and managed OpenSearch Service are widely used to search and analyze petabytes of data. Both options give customers full control over the configuration of compute, memory, and storage resources in clusters, which allows them to optimize cost and performance for their applications.
Self-managed OpenSearch and managed OpenSearch Service are widely used to search and analyze petabytes of data. Both options give customers full control over the configuration of compute, memory, and storage resources in clusters, which allows them to optimize cost and performance for their applications.
However, customers might often run applications that could be highly variable, where the usage is not always known. Such applications may experience sudden bursts in ingestion data or irregular and unpredictable query requests. To maintain consistent performance, customers must constantly tune and resize clusters or over-provision for peak demand, which results in excess costs. Many wanted an even simpler experience to run search and analytics workloads that allows them to focus on their business applications without having to worry about the backend infrastructure and data management.
What does simpler mean? It means customers don’t want to worry about these tasks:
- Choose and provision instances.
- Manage the shard or the index size.
- Index and data management for sizing and operational purposes.
- Monitor or tune the settings continuously to meet workload demands.
- Plan for system failures and resource threshold breaches.
- Security updates and service software updates.
AWS translated this checklist into requirements and goals under the following product themes:
- Simple and secure
- Auto scaling, fault tolerance, and durability
- Cost efficiency
- Ecosystem integrations
Before delving into how OpenSearch Serverless addresses these needs, let’s review the target use cases for OpenSearch Serverless, as their distinctive characteristics heavily influenced the design approach and architecture.
Target Use Cases
The target use cases for OpenSearch Serverless are the same as OpenSearch:
- Time series analytics (also popularly known as log analytics) focuses on analyzing large volumes of semi-structured machine-generated data in real time for operational, security, and user behavior insights.
- Search powers customer applications in their internal networks (application search, content management systems, legal documents) and internet-facing applications such as ecommerce website search and content search.
Let’s understand the differences between the typical time series and search workloads (exceptions may vary):
- Time series workloads are write-heavy, whereas search workloads are read-heavy.
- Search workloads have a smaller data corpus compared to time series.
- Search workloads are more sensitive to latencies and require faster response times than time series. workloads.
- Queries for time series are run on recent data, whereas search queries scan the entire corpus.
These characteristics heavily influenced our approach to handling and managing shards, indexes, and data for the workloads. In the next section, we review the broad themes of how OpenSearch Serverless meets customer challenges while efficiently catering to these distinctive workload traits.
Simple and Secure
To get started with OpenSearch Serverless, customers need to create a collection. Collections are a logical grouping of indexed data that works together to support a workload, while the physical resources are automatically managed in the backend. Customers don’t have to declare how much compute or storage is needed, or monitor the system to make sure it’s running well.
To adeptly handle the two predominant workloads, OpenSearch Serverless applies different sharding and indexing strategies. Therefore, in the workflow to create a collection, one must define the collection type—time series or search. Customers don’t have to worry about re-indexing or rollover of indexes to support their growing data sizes, because it’s handled automatically by the system.
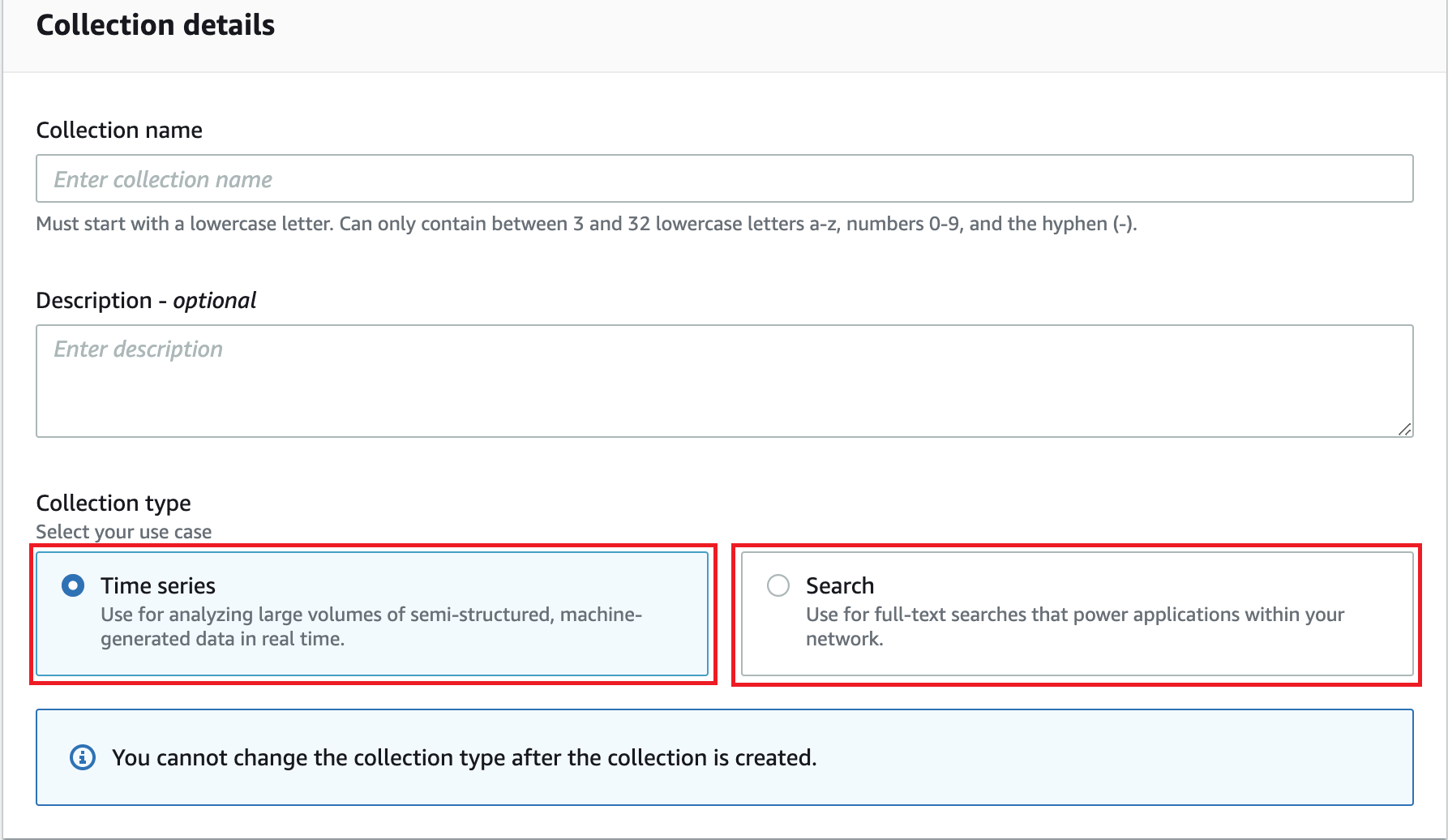 Next, customers make the configuration choices about the encryption key to use, network access to their collections (public endpoint or VPC), and who should access the collection. OpenSearch Serverless has an easy-to-use and highly effective security model that supports hierarchical policies for collections and indexes. Customers can create granular collection-level and account-level security policies for all their collections and indexes. The centralized account-level policy provides them with comprehensive visibility and control, and makes it operationally simple to secure collections at scale.
Next, customers make the configuration choices about the encryption key to use, network access to their collections (public endpoint or VPC), and who should access the collection. OpenSearch Serverless has an easy-to-use and highly effective security model that supports hierarchical policies for collections and indexes. Customers can create granular collection-level and account-level security policies for all their collections and indexes. The centralized account-level policy provides them with comprehensive visibility and control, and makes it operationally simple to secure collections at scale.
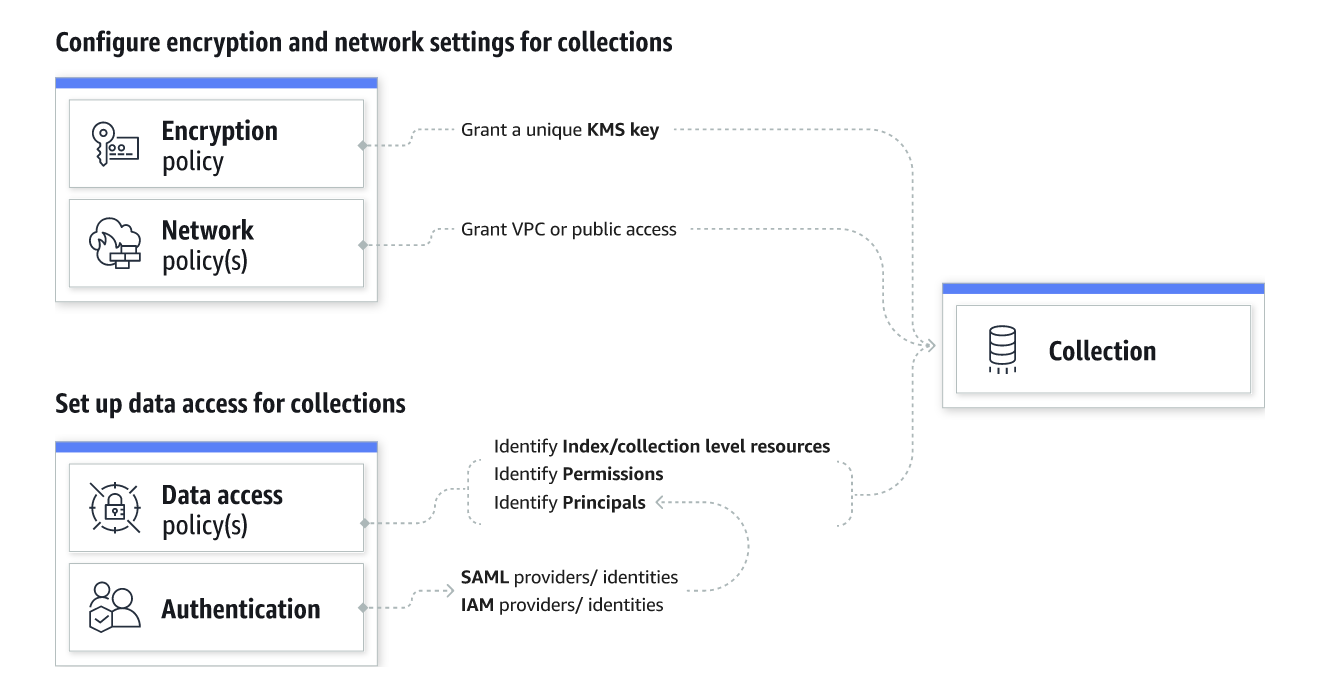
For encryption policies, customers can specify an AWS Key Management Service (AWS KMS) key for a single collection, all collections, or a subset of collections using a wildcard matching pattern. If rules from multiple policies match a collection, the rule closest to the fully qualified name takes precedence. Customers can also specify wildcard matching patterns in network and data access policies. Multiple network and data access policies can apply to a single collection, and the permissions are additive. Customers also can update the network and data access policies for their collection at any time.
OpenSearch Dashboards can now be accessed using SAML and AWS Identity and Access Management (IAM) credentials. OpenSearch Serverless also supports fine-grained IAM permissions so that customers can define who can create, update, and delete encryption, network, and data access policies, thereby enabling organizational alignment. All the data in OpenSearch Serverless is encrypted in transit and at rest by default.
Auto Scaling, Fault Tolerance, and Durability
OpenSearch Serverless decouples storage and compute, which allows for every layer to scale independently based on workload demands. This decoupling also allows for the isolation of indexing and query compute nodes so the fleets can run concurrently without any resource contention.
The compute resources like CPU, disk utilization, memory, and hot shard state are monitored and managed by the service. When these system thresholds are breached, the service adjusts capacity so customers don’t have to worry about scaling resources. For example, when an application monitoring workload receives a sudden burst of logging activities during an availability event, OpenSearch Serverless will scale out the indexing compute nodes. When these logging activities decrease and the resource consumption in the compute nodes falls below a certain threshold, OpenSearch Serverless scales the nodes back in. Similarly, when a website search engine receives a sudden spike of queries after a news event, OpenSearch Serverless automatically scales the query compute nodes to process the queries without impacting the data ingestion performance.
The following diagram illustrates this high-level architecture:
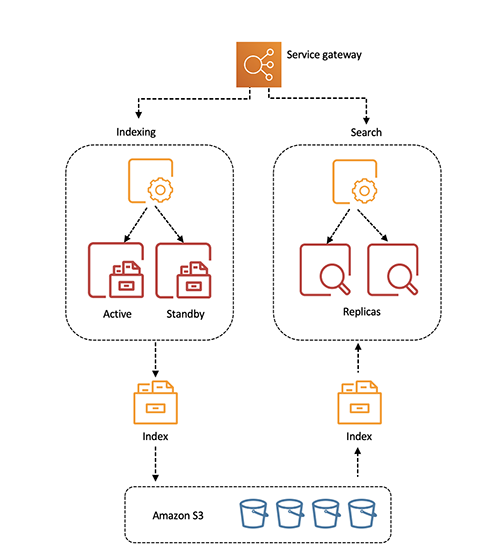
OpenSearch Serverless is designed for production workloads with redundancy for Availability Zone outages and infrastructure failures. By default, OpenSearch Serverless will replicate indexes across Availability Zones. The indexing compute nodes run in an active-standby mode. The service control plane is also built with redundancy and automatic failure recovery.
All the indexed data is stored in Amazon Simple Storage Service (Amazon S3) to provide the same data durability as Amazon S3 (11 nines). The query compute instances download the indexed data directly from Amazon S3, run search operations, and perform aggregations. Redundant query compute is deployed across Availability Zones in an active-active mode to maintain availability during failures. The refresh interval (the time from when a document is ingested by OpenSearch Serverless to when it is available to search) is currently under 15 seconds.
Cost and Cost Efficiency
With OpenSearch Serverless, customers don’t have to size or provision resources upfront, nor do they have to over-provision for peak load in production environments. They only pay for the compute and storage resources consumed by their workloads. The compute capacity used for data ingestion, and search and query is measured in OpenSearch Compute Units (OCUs). The number of OCUs corresponds directly to the CPU, memory, Amazon Elastic Block Store (Amazon EBS) storage, and the I/O resources required to ingest data or run queries. One OCU comprises 6 GB of RAM, corresponding vCPU, 120 GB of GP3 storage (used to provide fast access to the most frequently accessed data), and data transfers to Amazon S3. After data is ingested, the indexed data is stored in Amazon S3. Customers then have the ability to control retention and delete data using the APIs.
When customers create the first collection endpoint in an account, OpenSearch Serverless provisions 4 OCUs (2 ingest that include primary and standby, and 2 search that include two copies for high availability). These OCUs are instantiated even though there is no activity on the serverless endpoint to avoid any cold start latencies. All subsequent collections in that account using the same KMS key share those OCUs.
During auto scaling, OpenSearch Serverless will add more OCUs to support the compute needed by collections. These OCUs copy the indexed data from Amazon S3 before they can start responding to the indexing or query requests. Similarly, the OpenSearch Serverless control plane continuously monitors the OCUs’ resource consumption. When the indexing or search request rate decreases and the OCU consumption falls below a certain threshold, OpenSearch Serverless will reduce the OCU count to the minimum capacity required for the workload. The minimum OCUs prevent cold start delays.
OpenSearch Serverless also provides a built-in caching tier for time series workloads to provide better price-performance. OpenSearch Serverless caches the most recent log data, typically the first 24 hours, on ephemeral disk. For data older than 24 hours, OpenSearch Serverless only caches metadata and fetches the necessary data blocks from Amazon S3 based on query access. This model also helps pack more data while controlling the costs. For search collections, the query compute node caches the entire data corpus locally on ephemeral disks to provide fast, millisecond query responses.
Ecosystem Integrations
Most tools that work with OpenSearch also work with OpenSearch Serverless. Customers don’t have to rewrite existing pipelines and applications. OpenSearch Serverless has the same logical data model and query engine of OpenSearch, so customers can use the same ingest and query APIs you are familiar with, and use serverless OpenSearch Dashboards for interactive data analysis and visualization.
Because of its compatible interface, OpenSearch Serverless also supports the existing rich OpenSearch ecosystem of high-level clients and streaming ingestion pipelines—Amazon Kinesis Data Firehose, FluentD, FluentBit, Logstash, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (Amazon MSK). For more information, see Ingesting data into Amazon OpenSearch Serverless collections. AWS customers can also automate the process of collection creation using AWS CloudFormation and the AWS CDK. With Amazon CloudWatch integration, they can monitor key OpenSearch Serverless metrics and set alarms to notify you of any threshold breaches.
Choosing Between Managed Clusters and OpenSearch Serverless
Both managed clusters and OpenSearch Serverless are deployment options under OpenSearch Service, and powered by the open-source OpenSearch project. OpenSearch Serverless makes it easier to run cyclical, intermittent, or unpredictable workloads without having to think about sizing, monitoring, and tuning OpenSearch clusters. Customers may, however, prefer to use managed clusters in scenarios where they need tight control over cluster configuration or specific customizations.
With managed clusters, AWS customers can choose their preferred instances and versions, and have more control on configuration such as lower refresh intervals or data sharding strategies, which may be critical for use cases that fall outside of the typical patterns supported by OpenSearch Serverless. Also, OpenSearch Serverless currently doesn’t support all advanced OpenSearch features and plugins such as alerting, anomaly detection, and k-NN. Customers can use the managed clusters for these features until OpenSearch Serverless adds support for them.
Updates Since the Preview
With the general availability release, OpenSearch Serverless will now scale out and scale in to the minimum resources required to support workloads. The maximum OCU limit per account has been increased from 20 to 50 for both indexing and query. Additionally, customers can now use the high-level OpenSearch clients to ingest and query your data, and also migrate data from OpenSearch clusters using Logstash.
AWS also added support for three more Regions. OpenSearch Serverless is now available in eight Regions globally: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland).
Source: AWS
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States