

October 9, 2023
Berners-Lee Startup Seeks Disruption of the Current Web 2.0 Big Data Paradigm

Tim Berners-Lee’s legacy as the creator of the World Wide Web is firmly cemented in history. But as the Internet strayed away from its early egalitarian roots towards something much more big and corporate, Berners-Lee decided a radical new approach to data ownership was needed, which is why he co-founded a company called Inrupt.
Instead of having your data (i.e. data about you) stored across a vast array of different corporate databases, Berners-Lee theorized, what if each individual could be in charge of his or her own data?
That is the core idea behind Inrupt, the company that Berners-Lee co-founded in 2017 with tech exec John Bruce. Inrupt is the vehicle through which the duo hope to spread a new Internet protocol, dubbed the Solid protocol, which facilitates distributed data ownership by and for the people.
The idea is radical in its simplicity, but has far-reaching implications, not just for ensuring the privacy of data, but also to improve the general quality of data for building AI, says David Ottenhimer, Inrupt’s vice president of trust and digital ethics.
“Tim Berners-Lee had a vision of the Web, which he implemented,” Ottenheimer tells Datanami. “And then he thought it needed a course correction after period of time. Primarily the forces that be centralizing data towards themselves were the opposite of what we started with.”

(Image source: Inrupt)
When Berners-Lee wrote the first proposal for the World Wide Web in 1989, the Internet was a much smaller and altruistic place than it is now. Small groups of people, largely scientists, used the Net to share their work.
As the Web grew more commercialized, the static websites of the Web 1.0 world were no longer sufficient for the challenges at hand, such as the need to maintain state for a shopping cart on an e-commerce site. That kicked off the Web 2.0 era, characterized by more JavaScript and APIs.
As Web companies morphed into giants, they built huge data centers to store vast amounts of user data to work with their application. Berners-Lee’s insight is that it’s terribly inefficient to have multiple, duplicate monoliths of user data that aren’t even that accurate. The Web 3.0 era instead will usher in the age of federated data storage and federated access.
In the Web 3.0 world that Inrupt is trying to build, data about each individual is stored in their very own personal data store, or a pod. These pods can be hosted by a company or even a government on behalf of their citizens, such as the government of Flanders is currently doing for its 6 million citizens.
Instead requiring Web giant to not lose or abuse billions of people’s data, in the Inrupt scheme of things, the individual controls his or her own data via the pod. If an individual wants to do business with a company online, they can grant access to his her pod for a specific period of time, or just for a specific type of data. The company’s application then interacts with that data, in a federated manner, to deliver whatever service it is.
“So instead of chasing 500 versions of you around the Web and trying to say ‘Update my address, update my name, update my whatever,’ they come to you and it’s your data and they can see it one place,” Ottenheimer says.
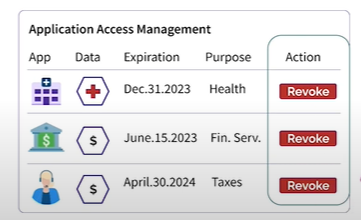
Users can delete company access to their data using the Solid protocol (Image source: Inrupt)
At a technical level, the pods are materialized as RDF stores. According to Ottenheimer, users can store any type of data they want, not just HTML pages. “Apps can write to the data store with any kind of data they can imagine. It doesn’t have to be a particular format,” he says. Whether it’s your poetry, the number of chairs you have in your home, your bank account info, or your healthcare record, it can all be stored, secured, and accessed via pods and the Solid protocol.
This approach brings obvious benefits to the individual, who is now empowered to manage his or her own data and grant companies’ access to it, if the deal is agreeable to them. It’s also a natural solution for managing consent, which is a necessity in the world of GDPR. Consent can be as granular as the user likes, and they can cancel the consent at any time, much like they can simply turn off a credit card being used to purchase a service.
“The interoperability allows you to rotate to another card. Get a new card, get a new number, so you rotate your key and then you’re back to golden,” Ottenheimer says. “You [give consent] in a way that makes sense. You’re not giving it away forever, then finding you can no longer get back the consent you gave years later and have no idea where the consents are. We called it the graveyard of past consents.”
But this approach also brings benefits to companies, because using the W3C-sanctioned Solid protocol provide a way to decouple data, applications, and identities. Companies also are alleviated of the burden of having to store and maintain private and sensitive data in accordance with GDPR, HIPAA and other rules.
Plus, it yields higher quality data, Ottenheimer says.
Inrupt’s Solid protocol could be used for customer 360 initiatives (Image source: Inrupt)
“It’s very exciting because queries are meant to be agile, more real-time, as they say,” he says. “I remember this from very big retailers I worked with years ago. You grab all this data, you pull it in, and then there’s all kinds of security requirements to prevent breaches, so you pull things into other databases. Now they’re out of sync, often stale. Seven days old is too old. And it’s impossible to get a fresh enough set of data that’s safe enough. There’s all these things conspiring against you to get a good query versus the pod model, it’s inherently high performance, high scale, and high quality.”
Companies may be loathe to give up control of data. After all, to become a “data-driven” company, you sort of have to be in the business of storing, managing, and analyzing data, right? Well, Inrupt is trying to turn that assumption on its head.
According to Ottenheimer, new academic research suggests that AI models built and operated in a federated model atop remotely stored data may outperform AI models built with a classic centrally managed datastore.
“The latest research out of Oxford in fact shows that it’s higher speed, higher performance when you distribute it,” he says. “In other words, if you run AI models and federated the data, you get higher performance and higher scale, than if you try to pull everything central and run it.”
At first, the centrally managed data set will outperform the federated one. After all, the laws of physics do apply to data, and geographic distance does add latency and complexity. But as updates to the data are required over time, the distributed model will start to outperform the centrally managed one, Ottenheimer says.
“At first, you’re going to get very fast results for a very centralized, very large data set. You’ll be like, wow,” he says. “But then when you try to get bigger and bigger and bigger, it falls over. And in fact, it gets inaccurate and that’s where it really gets scary, because once the integrity comes to bear, then how do you clean it up?
“And you can’t clean up giant data sets that are really slow,” he continues. “They become top heavy, and everybody looks at them and says, I don’t understand what’s going on inside. I don’t know what’s wrong with them. Whereas if you have highly distributed pod-based localized models and federated models using federated learning, you can clean it up.”![]()
For Ottenheiner, who has worked at a number of big data firms over the years and breaks AI models for fun, the idea of a smaller but higher quality data set brings certain advantages.
“That big data thing that I worked on in 2012–that ship sailed,” he says. “We don’t want all the data in the world because it’s a bunch of garbage. We want really good data and we want high performance through efficiency. We won’t have data centers that are the size of Sunnyvale anymore that just burn up all the energy. We want super high-efficiency compute.”
The pod approach could also pay dividends in the burgeoning world of generative AI. Currently, people predominantly are using generalized models, such as OpenAI‘s ChatGPT or Amazon’s Alexa, which was recently upgraded with GenAI capabilities. There is a single foundational model that’s been trained on hundreds of millions of past interactions, including the new ones that users are having with it today.
There many privacy and ethics challenges with GenAI. But with the pod model of personalized data and personalized models, users may be more inclined to use the models, Ottenheimer says.
“So in a pod, you can tune it, you can train the model to things that are relevant to you, and you can manage the safety of that data, so you get the confidentiality and you get the integrity,” he says. “Let’s say for example, you want it to unlearn something. Good luck [asking] Amazon…It’s like you spilled ink into their water. Good luck getting that back out of their learning system if they don’t plan ahead for that kind of problem.
“Deleting the word I just said, so that it doesn’t exist in the system, is impossible unless you start over and they’re not going to start over on a massive scale,” he continues. “But if they design it around the concept of a pod, of course you can start over. Easy. Done.”
Related Items:
AI Ethics Issues Will Not Go Away
Privacy and Ethical Hurdles to LLM Adoption Grow
Zoom Data Debacle Shines Light on SaaS Data Snooping
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States