

June 12, 2023
Researchers Pit LLMs Against Each Other in Malware Detection Smackdown

Image created by the author using Midjourney.
As the number of malicious packages published on package repositories like PyPI and npm continues to increase thanks to automation, security researchers are experimenting with different ways to employ generative AI for identifying malware.
Endor Labs researcher Henrik Plate previously designed an experiment to use large language models to assess whether a code snippet is harmful or benign. In his latest experiment, Plate compared OpenAI’s GPT-3.5-turbo with Google’s Vertex AI text-bison model using improved research methods. He also compares the performance of OpenAI’s GPT-4 in certain cases.
In his initial experiment, Plate asked the LLMs to classify open source software code as malicious or benign, but in this latest research, he asked the LLMs to respond with a risk score on a scale between 0-9 that ranged from risk ratings of little to highly suspicious. Another improvement of this research was the removal of comments in suspicious code snippets, which the team says reduces exposure to prompt injection, or the technique of manipulating AI responses through carefully crafted malicious inputs.
The two LLMs agreed in a majority of 1,098 assessments of the same code snippet, Plate found. In 488 of the assessments, both models came up with the exact same risk score, and in another 514 cases, the risk score differed by only one point.
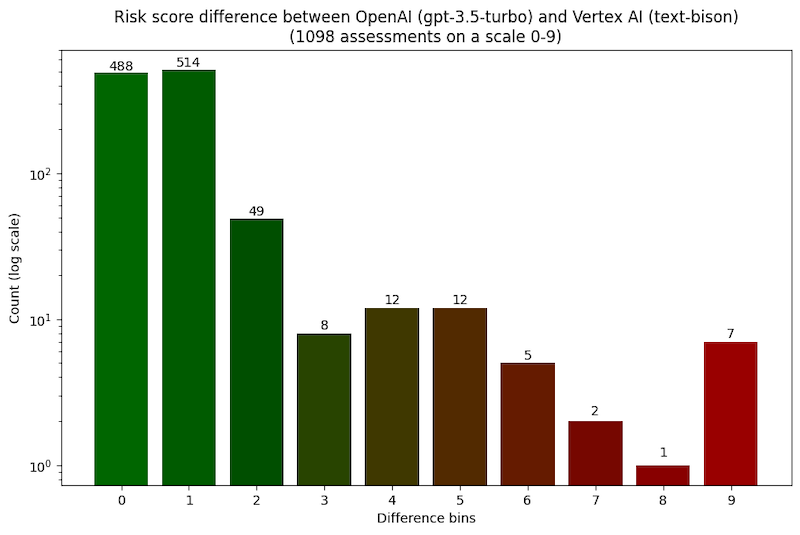
(Source: Endor Labs)
Plate concluded his initial experiment with the idea that LLM-assisted malware reviews with GPT-3.5 are not yet a viable alternative to manual reviews. He says an inherent problem is a reliance on identifiers and comments written by benign developers to understand code behavior. These comments act as an information resource but can be misused by malicious actors to trick the language model.
Despite being unsuitable for identifying malware on their own, Plate says they can be used as one additional signal and input for manual reviews. “In particular, they can be useful to automatically review larger numbers of malware signals produced by noisy detectors (which otherwise risk being ignored entirely in case of limited review capabilities),” he wrote.
In this latest experiment, Plate concludes that the risk assessment of OpenAI’s GPT-3.5-turbo and the Vertex AI text-bison model are comparable but neither performs greatly, he says. Both models gave false positives and false negatives, and OpenAI’s GPT-4 outperforms both when it comes to providing source code explanations and risk ratings for non-obfuscated code.
![]() Plate and his team also explain why they believe the risk of prompt injection is more manageable for this use case compared to others, writing, “This is mainly due to the fact that attackers do not live in a world free of rules … they still need to comply with the syntactic rules of the respective interpreters or compilers, which opens up the possibility for defenders to sanitize the prompt input.”
Plate and his team also explain why they believe the risk of prompt injection is more manageable for this use case compared to others, writing, “This is mainly due to the fact that attackers do not live in a world free of rules … they still need to comply with the syntactic rules of the respective interpreters or compilers, which opens up the possibility for defenders to sanitize the prompt input.”
For the full technical details of this experiment, read Plate’s blog at this link.
Related Items:
Data Management Implications for Generative AI
Should Employees Own the Generative AI Tools that Enhance or Replace Them?
AI Researchers Issue Warning: Treat AI Risks as Global Priority
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States