

October 25, 2022
Uncovering the Differences Between Logical Data Fabric and Data Mesh

(greenbutterfly/Shutterstock)
Data fabric and data mesh are two concepts that are regularly covered in data and analytics circles. They both evoke the image of a flexible digital cloth but they are, in fact, very different. As a result, this has led to some confusion, but before explaining what they are, how they can be leveraged (together or separately), and why they are both so important, let’s start by looking at how both approaches have become popular, emerging data architectures.
Over the past two decades, data storage has gone through cycles of centralization vs. decentralization, including databases, data warehouses, cloud data stores, data lakes and the list goes on.
Currently, depending on format, usage and other factors, companies use data warehouses, data lakes, and other forms of monolithic repositories that attempt to collect all the available data. They also have cloud-based hyper scalers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP), not to mention cloud-based data warehousing solutions like Snowflake.
Despite all the available options the same conundrum remains: Businesses want data to be in one place because it is easy to find but collecting all the data into a single location continues to be a challenge. Physically copying the data from the different silos into another central repository takes time, effort, and money, and it requires a central IT team, who is not the subject matter expert in all data, to maintain it. Data fabric and data mesh aim to solve this centralization challenge but in different ways.
Decentralization—the Way Out

Data centralization is the problem (cybrain/Shutterstock)
Physically centralizing the data into a monolithic repository is a problem, and decentralization is a solution to overcome it. But how can business users get the unified data if it’s decentralized? Fortunately, logical data integration supports decentralization by leaving the data wherever it is, connecting to it virtually, and providing the same integrated “view of the data” thus avoiding the issues with physical data replication. In logical data integration architectures, consumers do not access data directly, but through shared semantic models that decouple the consumer from the location and physical schema of the applicable data sources.
These solutions provide virtual views of the data while leaving the source data exactly where it is. In this way, they are decentralized, distributed approaches, because all of the data remains in its various repositories, be they databases, data warehouses, or data lakes, and yet they still provide all the benefits of centralized, monolithic approaches.
Logical data fabric and data mesh are two examples of technological advances that adhere to this emerging logical paradigm. They are both progressive, distributed approaches that rely on logically connecting to disparate data sources, rather than trying to collect it in one physical location. But they do this in very different ways.
Logical Data Fabric
Like the different threads in the fabric of our clothing, a data fabric is made up of data from different locations, formats, and types. However, in this configuration, data is still understood to be physically integrated through traditional replication.
A logical data fabric replaces physical data integration with a logical data integration component, such as data virtualization. Data virtualization is a modern data integration approach that provides real-time views into disparate data sources, as needed, without having to move the data.

Data fabric centralizes data management tasks for decentralized data (CodexSerafinius/Shutterstock)
A logical data fabric seamlessly integrates data from all across the different systems in an organization. It carries very little if any of the source data: however, to do its work it stores the necessary technical and business metadata, indicating details, such as where the data is stored, who is accessing it, and all of the associated common business definitions. Information is cataloged and made available as a resource that not only offers information about the data sources, but also grants immediate access to approved users. Modern logical data fabrics also incorporate machine learning and artificial intelligence to automate many of the key processes.
Because all users in an organization access data through the same logical data fabric, it provides inherent support for security and data governance. Protocols governing access can be managed only once, in order to take effect across every component of the logical data fabric.
Logical data fabric also provides business users with the ability to add business semantics in a layer above the actual data sources, all without affecting the underlying data sources. Business users can leverage this capability to build custom-tailored data stores to meet particular needs, again without affecting the underlying data. Data scientists can use their own tools and iteratively develop their own models based on the same trusted data. As a result, they no longer have to spend most of their time collecting and preparing the data, because in a logical data fabric, the available data is ready for them to leverage.
Because logical data fabric enables data consumers to access data regardless of where it is stored, it also enables business users to continue using the data even when it is in the process of being moved, like during a large-scale modernization or migration project. A logical data fabric also abstracts data consumers from many of the complexities of data access, leaving business users free to make faster, better decisions, and reducing development cycles.
Data Mesh
In contrast with logical data fabric, which is a technology solution, data mesh is a structure for organizing data, people, processes, and activities within an organization. Like a logical data fabric, data mesh can also be implemented using the logical approach to data integration.
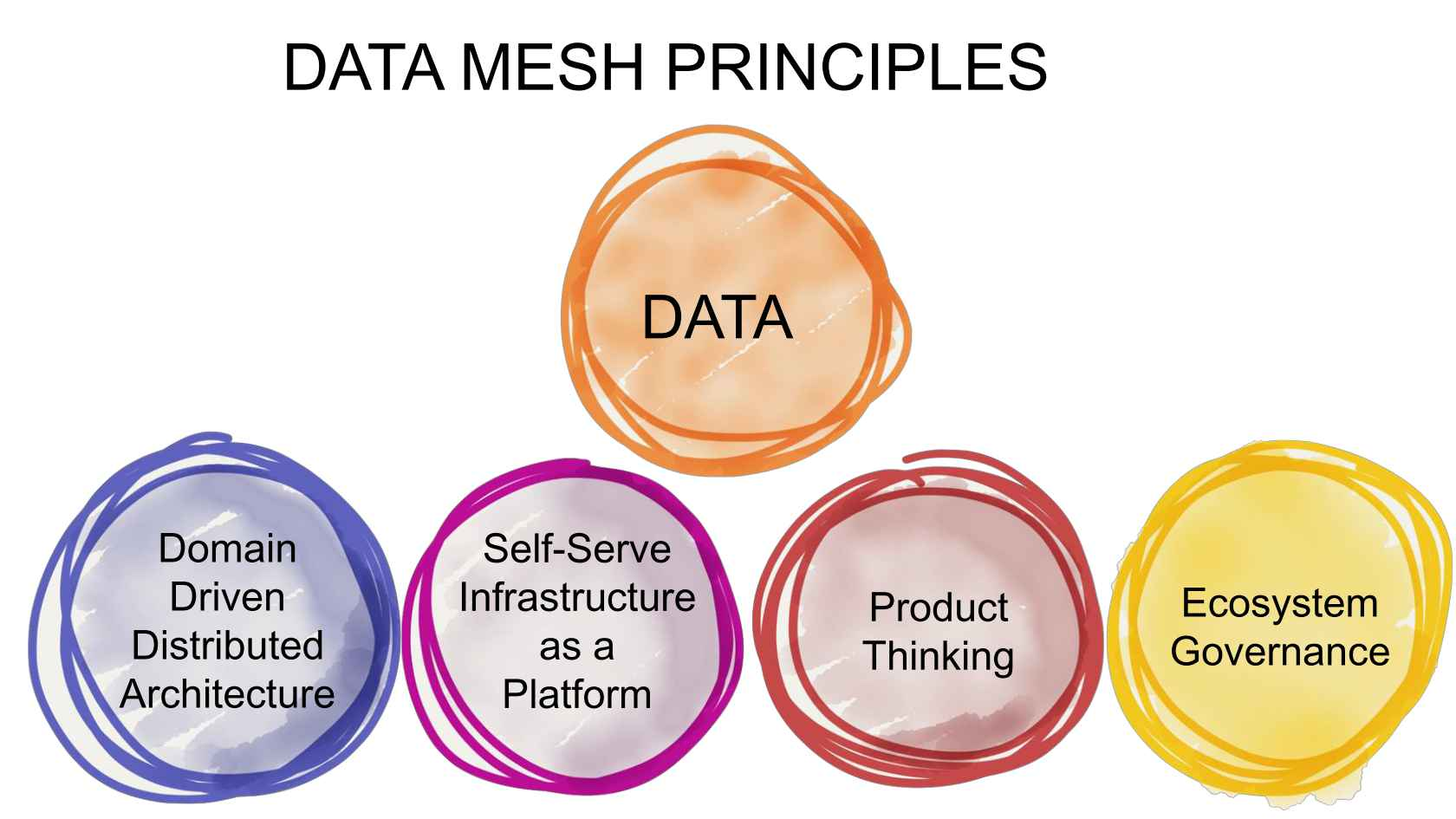
(Image courtesy Zhamak Dehghani)
Zhamak Dehghani first proposed data mesh in 2018 while with ThoughtWorks to address the challenges of centralized data infrastructures. In this infrastructure, enterprise data is managed by IT, which has only limited knowledge about the data needs of the different departments within an organization. While good in concept, this structure that has led to frustration, because business stakeholders often need to fight for preferential treatment by IT, and they often have to wait for their requests to be fulfilled or to be given access. If you think about it, most IT departments are composed of up to hundreds of people, but there could be tens of thousands of users or more in a large organization. How can IT be expected to keep up?
In contrast, in a data mesh, data is owned and managed by different “data domains” within an organization, which correspond to departments or functions. So, in this sense it is a decentralized or distributed configuration. The next principle in a data mesh is that stakeholders within each data domain would package their data as “products” to be delivered throughout the organization. Each line of business would create and maintain their own data products, such as customer data products, asset data products, finance data products, and of course product data products. Finally, a data mesh needs a central data provisioning and governance function, to ensure that data products and development is consistent throughout the organization. This is the only aspect of a data mesh that is centralized.
Therefore, like logical data fabric, when it comes to implementing a data mesh it ’is important to leverage data virtualization as a core component. With data virtualization, lines of businesses, the owners of the data domains, can create their own “views” or data products. Then, companies can establish the central provisioning and governance function in a straightforward manner.
First, data virtualization can provide the central provisioning function by serving as an abstracted data access layer above the different data sources, just as it does in a logical data fabric. Because data virtualization holds the access and business metadata in a separate layer, data virtualization can also facilitate enterprise-wide data governance across the different data domains. In addition, because data virtualization enables organizations to create semantic layers above the data sources without affecting the data sources themselves, it provides the essential building blocks for creating data domains.
Data Fabric, Data Mesh or Both?
In a nutshell, logical data fabric is an intelligent, powerful way to integrate data, and data mesh is a potentially intelligent, powerful way to organize an entire company. They are very different in size, scope, and purpose, and they address two unique issues which may be why some organizations opt for both. In fact, if a company were created according to a data mesh design, or reorganized so that it adhered to one, a logical data fabric would be a very efficient way to organize the data across the domains.
Using data virtualization, an organization can leverage the logical data integration method within both concepts—data fabric and data mesh—and immediately start realizing the benefits of these approaches. Better yet, organizations can be ready for a logical data fabric, a data mesh, or both, depending on what is needed as it provides a future-proof data framework for meeting the changing needs of the business.
About the author: Ravi Shankar is the Senior Vice President and Chief Marketing Officer at data integration and management vendor Denodo. You can follow the company on Twitter at @denodo.
Related Items:
Data Mesh: What’s In It For The Business?
Data Mesh Vs. Data Fabric: Understanding the Differences
Data Fabrics Emerge to Soothe Cloud Data Management Nightmares
Applications:
Data Management
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States