

October 24, 2022
What’s Holding Up Progress in Machine Learning and AI? It’s the Data, Stupid

(Gorodenkoff/Shutterstock)
The lack of a solid data foundation and solid data workflows is preventing companies from making more progress with machine learning and AI, according to a new Forrester Consulting survey conducted on behalf of Capital One.
While companies are having some success in putting machine learning and AI into production, they would be further along if data management issues weren’t getting in the way, according to Capital One’s new report, “Operationalizing Machine Learning Achieves Key Business Outcomes,” which was released today.
The report, which is based in part on a July Forrester Consulting survey of 150 data management decision-makers in North America, found that 73% of decision-makers cited transparency, traceability, and explainability of data flows as key issues preventing the operationalizing of machine learning and AI applications. It also found that 57% of those surveyed said internal silos between their data scientists and their practitioners are inhibiting machine learning deployments.
“We’re still at a point where it’s not so much the machine learning algorithm itself that is the roadblock, or the hurdle to folks getting impact,” says David Kang, senior vice president and head of data insights at Capital One. “It’s still about the data.”
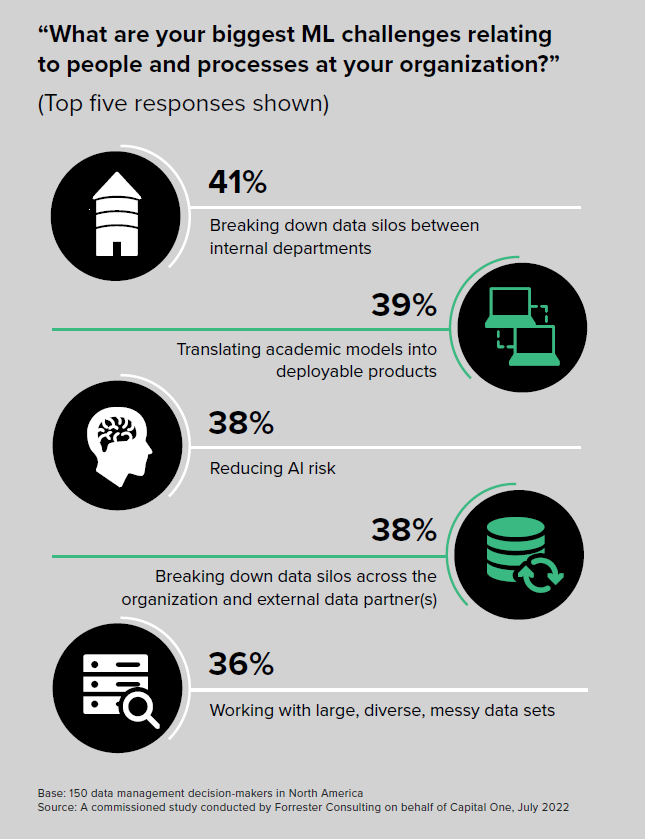
Source: Capital One report: Operationalizing Machine Learning Achieves Key Business Outcomes
When Capital One leaders commissioned the survey, they thought the big challenge was going to center around the operationalization of machine learning. As machine learning and AI adoption has grown, MLOps has emerged as its own discipline, and is an area that Capital One is investing in.
But when the report came back, the lack of progress in building a solid data foundation, including data engineering and data infrastructure, was top of mind for data decision-makers, Kang says.
“In some ways it’s disappointing,” he tells Datanami. “But I would say in other ways, it’s not surprising, because to leverage data at scale, there’s constant attention that needs to be paid to thinking about and rethinking every capability in your data ecosystem–how you produce and consume, how you monitor, how you govern data differently. And our journey to transform our data ecosystem, as you wrote about earlier this year, is an ongoing one. It’s not something that you just do once and sort of forget about it. But it requires constant care and attention.”
Capital One’s survey echoes the findings from other recent studies, which find issues with data management slowing down machine learning and AI adoption. That includes a September MIT Technology Review report, commissioned on behalf of Databricks, that highlighted data mismanagement’s role in jeopardizing AI; as well as an August IDC study commissioned by Collibra that found a correlation between companies exhibiting hallmarks of “data intelligence,” such as data cataloging, lineage, quality management, and governance, and success in the marketplace.
If there’s a common theme among these studies, it’s that, while the sophistication of available machine learning and AI technologies is growing quickly, companies are finding they haven’t done some of the core data management work that’s needed to put them in position to take advantage of that progress.
Companies may find that a machine learning or AI application is having a positive impact on a limited proof of concept (POC) but fail to take the necessary steps to ensure the rollout will go smoothly in wider production. That’s just an aspect of human nature, Capital One’s Kang says.

Data management issues are slowing down machine learning achievement (Ilyafs/Shutterstock)
“There’s a real appetite to scale that thing quickly,” he says. “And if you don’t step back and say, hey, the thing you stood up in the sandbox, let’s actually make sure that you’re systematizing it, making it widely available, putting metadata on top of it, putting traceability and flows, and doing sort of all the foundational scaffolding and infrastructure steps that are needed for this thing to be sustainable and reusable.
“That requires a ton of discipline and hygiene and potentially waiting a bit before the thing that you want to scale up starts to see impact in the marketplace,” Kang continues. “The temptation is always there. So what ends up happening, through no ill intent, is these proof of concepts start to see impact, and then and then all of a sudden you find yourself in a place where there’s a bunch of data silos and a bunch of other data engineering infrastructure challenges.”
Data science is still a fairly new discipline, and many companies are struggling to fill roles. Capital One’s report found that 57% of survey-takers indicated they intended to leverage partnerships to fill gaps among data science practitioners. That lack of in-house expertise also makes it more critical for companies to build the core data infrastructure in such a way that it makes building more advanced machine learning and AI use cases on top of it easier and more repeatable, Kang says.
“Therefore there’s a high premium on making sure whenever you’re building something…you’re building in a sustainable way,” he says. “So that you’re not just building toward one use case, but actually thinking about how those capabilities can be recycled and reused in various applications across the business. That’s exactly what…my team has been doing here, building our own internal machine learning platform.”
The Capital One survey identified other issues slowing down machine learning and AI adoption. It found 36% of survey respondents cited “large, diverse, messy data sets” as a key barrier, while 38% cited AI risk as a top challenge. Data silos across the organization and external data partners was cited by 38% who said it posed a challenge to machine learning maturity.
The data management hiccup doesn’t seem to be slowing down AI and machine learning investments (at least not yet). The Capital One survey found that 61% of decision makers plan to add new machine learning capabilities and applications over the next three years. More than half of respondents (53%) are currently prioritizing improving business efficiency by leveraging machine learning, the company says.

(everything possible/Shutterstock)
So, what are companies doing with machine learning? That’s another interesting tidbit that came out of this survey, which is that automated anomaly detection is the top machine learning use case, with 40% of survey-takers reporting that as their top use case. This resonated with Kang, who has helped build machine learning-based anomaly detection systems for Capital One.
“I was struck in seeing these applications how much they were just about hey, let’s use the machine learning capability to take a look at a really massive data set and point out anomalies, but not necessarily do anything beyond that,” he says. “It’s still going to be up to an analyst or a human to pick up that thing and then figure out the actionable next step to implement that. We’re not wiring sort of closed feedback loops of, okay, the ML finds something, it takes an action, and then it keeps cycling on its own.”
Other top use cases for machine learning and AI include: receiving transparent application and infrastructure updates automatically (39%), and meeting new regulatory and privacy requirements for responsible and ethical AI (39%).
You can download a copy of the report here.
Related Items:
MIT and Databricks Report Finds Data Management Key to Scaling AI
The Modernization of Data Engineering at Capital One
Applications:
Data Management
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States