

August 29, 2022
Teradata Unveils New Data Lake, Advanced Analytics Offerings

(Risto Viita/Shutterstock)
Teradata today rolled out a pair of new products designed to broaden its appeal to a new generation of users, including a new data lake called VantageCloud Lake that melds the workload management capabilities of its eponymous file system with the efficiency of object storage in the cloud, and ClearScape Analytics, which introduces new data prep and MLOps tools, as well as advanced time-series analytics for IoT data.
When Teradata launched Vantage four years ago, the delivery of its data warehouse in a cloud setting with elastic scaling and pricing was the big news. The company was tired of losing workloads to underwhelming Hadoop clusters, and as AWS and other clouds started gobbling up these failed Hadoop experiments, the writing was clearly on the wall: The cloud was the future.
While Teradata’s cloud pivot has been quite successful (the cloud now drives the bulk of its revenue growth), the company’s flagship product itself–an MPP, column-oriented analytics database–hasn’t changed much in the cloud. Earlier this year, the company gave a peek at the changes it was working on with object storage and separation of compute and storage. But its biggest enterprise and government accounts continue to use the relational database to power critical SQL workloads, whether in the cloud or on-prem.
That is changing with today’s launch of VantageCloud Lake, which is Teradata’s first official foray into a true “cloud native” architecture. Instead of storing data in the proprietary Teradata file system–which is fast and capable but also expensive–VantageCloud Lake stores data in Amazon S3, using one of a number of open file formats, such as Parquet, JSON, CSV, and Databricks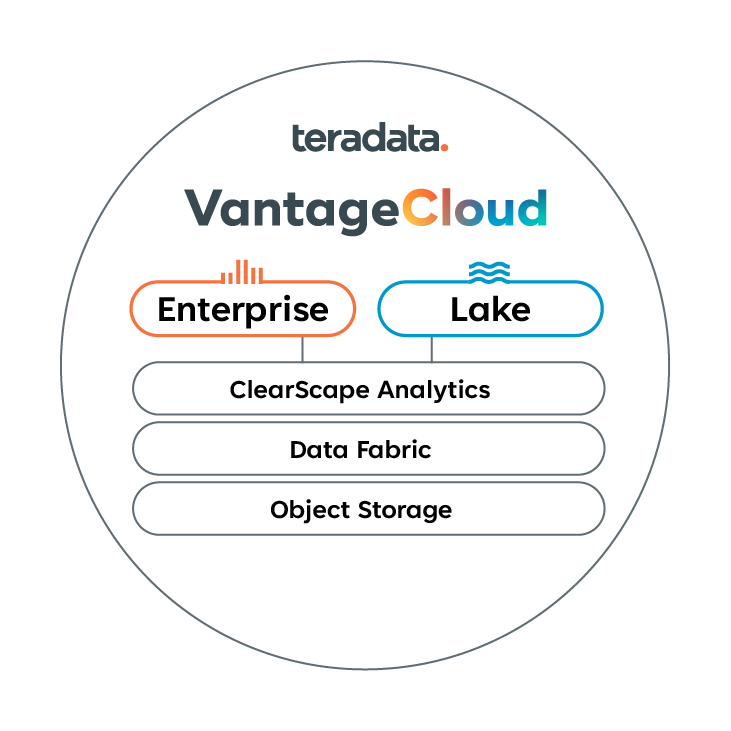 Delta Lake format (Apache Iceberg is in the works).
Delta Lake format (Apache Iceberg is in the works).
Whereas VantageCloud Enterprise continues to be optimized for high-end production analytics workloads where performance and efficiency are paramount, the new VantageCloud Lake offering is targeted more at data scientists who want to be able to spin up an exploratory analytics environment quickly and easily, and then spin it back down just as quickly, said Teradata CTO Stephen Brobst.
“The data lake users are more sophisticated, in the sense that they want to provision a data lab, they want to be able to work with data, do data exploration, data science work,” Brobst said. “There’s a self-service capability where they can just provision their own resources on demand, and when they’re done, they just shut it down.”
Downtime will basically be non-existent with VantageCloud Lake, which Teradata also calls the Cloud Lake Edition, or CLE. “In the past, if you wanted to add resources and so on, you had to take a restart. That’s all gone with the CLE,” Brobst said.
But the CLE is not a full break from VantageCloud Enterprise, the cloud version of the classic Teradata system which previously was called Teradata Vantage, as CLE is retaining workload management capabilities of Enterprise Edition as well as technological hooks.
The workload management capability in CLE is critical to avoiding the large bills that users of newer cloud-based analytic offerings sometimes get, according to Teradata. Brobst cited an analyst report that found that more than 80% of cloud analytics customer go over budget by more than 50% in the first 18 months. These are the “newbie” players, and he highlighted Snowflake as one prominent offender.

Teradata CTO Stephen Brobst
“The consumers of these newbie players that aren’t sophisticated in workload management. They’re basically giving the vendor a blank check,” Brobst told Datanami. “This is very, very painful. At Teradata, we’re much more efficient in the use of resources, and we manage within the budget constraints of the customer.”
The ability to handle concurrency is critical at enterprise scale, Brobst said. When an analytic cloud is deficient in this category, they “use elasticity as a crutch,” he said. “Above a certain concurrency, they just start spinning up more and more clusters, which are using resources very inefficiently,” he continued. “We don’t have that problem. That’s why our technology is factors–not percentages, but factors–more efficient on a cost-per-query basis.”
In addition to sharing the workload management capabilities of its bigger brother, the new CLE also gains the ability to leverage the benefits of the proprietary Teradata file system when the workload can benefit from it.
“In Cloud Lake Edition, we’re largely pivoted to the object store,” Brobst said. “We still have access to block store, and we do caching and things like that. But the configuration of the software [in Enterprise Edition] is very different for those quick in-and-out queries versus the more exploratory work that happens in the Lake Edition.
While CLE defaults to storing data in Amazon S3–or object stores from Microsoft Azure and Google Cloud, which Teradata has pledged to support with CLE in 2023–that’s not the only option. CLE also has a “curated data format” that’s a variation of how the Teradata file system reads and writes data from block storage, or Amazon Elastic Block Store (EBS).
“I wouldn’t say it’s exactly the Teradata file system, because we optimize it for object store,” he said. “We have, I’ll call it, a variation on an optimized for-cloud native storage.”
In any case, the users probably won’t notice the difference in what’s going on under the covers. And if users want to move workloads to VantageCloud Enterprise, it’s not a difficult move.
“It’s important to note that API consistency between the Lake Edition and Enterprise is there,” Brobst said. “Any workload that I built as a data scientist in the Lake Edition, I can move that to the Enterprise Edition with zero friction. So that’s something that’s very important to this unified architecture approach that we’re taking.”
The changes on the analytic front, with ClearScape Analytics, are nearly as big as the changes with the CLE.
ClearScape Analytics is a new suite of in-database analytics and machine learning tools that can run on any Teradata environment, including the two VantageCloud offerings and on-prem Vantage environments. The new offering includes existing Teradata functionality and introduces new capabilities in two big areas, including ModelOps and time-series functions.
“Analytics is more than just the scoring the model at the end. There’s a whole pipline of data preparation. Depending on who you talk to, 80% of the work is in the data wrangling and transforming the data and so on. So we have a whole bunch of capabilities in that area.”
On the time-series front, ClearScape Analytics builds on support for the time-series data type with new algorithms and other functions designed to process the time-series data.
Meanwhile, the MLOps capabilities in ClearScape are designed to help data scientists automate the machine learning lifecycle, including capturing, training, deploying, and monitoring the machine learning model in production. “That’s something that before was done with a lot of scripting and a lot of manual stuff,” Brobst said. “Now it’s completely automated.”
ClearScape is not designed to be data science workbench. Instead, Teradata intends the product to be used in conjunction with a data science notebook like Jupyter or tools from SAS, Dataiku, H2O.ai, RStudio, and others.
“This does not replace those things,” Brobst said. “The data scientist is using the best tool for them. But we then automate the process behind the scenes for the model deployment, monitoring, etc.”
ClearScape Analytics is a reflection of Teradata’s plan to be more aggressive in embracing open source in the AI era and allowing its customers to use open source predictive and prescriptive analytics with its data management platform.
“A lot of machine learning is absolutely open source,” Brobst said, citing things like TensorFlow and scikit-learn and other R and Python libraries. “But we’ve got these in-database capabilities that are uniquely aligned to the capability of the original architecture that came out of CalTech, which was kind of the origins of the Teradata technology. And we can provide those libraries with an order of magnitude, or multiple orders of magnitude, speed up.”
Teradata won’t be open sourcing its core tech anytime soon. But as the use of machine learning explodes and new deep learning techniques emerge, the company sees an opportunity to not only bring more unstructured data (the feedstock for deep learning and AI) under its wing, but also to give data scientists better tools for getting their AI creations to market.
“We are the data management platform. We’re still the best at that, and that’s where we come from,” Brobst said. “There is no AI without data. Data is the fuel. And so as I said, it is not our intent from an R&D point of view to go invest new algorithms. But we will take those algorithms invented in academic and commercial community, with partners and so on, and we will engineer them to run in parallel, to run faster. We absolutely will take that on.”
Related Items:
Teradata Puts New Cloud Architecture to the 1,000-Node Test
Teradata Rides Cloud Wave to Two-Year High
Inside Teradata’s Audacious Plan to Consolidate Analytics
Technologies:
Cloud
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States