

July 11, 2022
How Intuit Is Building AI, Analytics, and Streaming on One Lakehouse

(Tada-Images/Shutterstock)
With more than 100 million customers and revenues close to $10 billion, Intuit has enterprise-scale data processing needs, as well as enterprise-scale challenges. Faced with the prospect of building independent architectures for each big data project, which would exacerbate the data silo problem, Intuit instead took a unified approach that leverages a lakehouse as the data standard across the enterprise.
Intuit is known for TurboTax and QuickBooks, two of the most successful consumer finance products of all time. But with recent developments in machine learning and the acquisitions of Credit Karma and Mailchimp, Intuit is moving forward with plans to remake itself into an AI juggernaut.
“Intuit is transforming into an AI-driven expert platform,” Alon Amit, the company’s vice president of product management, said at the Databricks’ Data + AI Summit two weeks ago. “We’re helping people prosper, and this used to mean helping you go through the motions of your taxes and your books. But now it means a lot more.”

Alon Amit, Intuit vice president of product management
For example, the company is using machine learning to help categorize transactions in QuickBooks, saving customers from the tedious task of manually categorizing them. This requires machine learning that’s very personalized, much like the Credit Karma service that automatically recommends how individuals can improve their credit score based on inputs.
Developing these new data-driven products requires having a solid data architecture upon which to build. The company wanted to avoid building disparate data systems for each of its project, and instead get the thousands of analysts, data scientists, software engineers on the same page with a single view of the data.
That architecture didn’t exist at Intuit when Amit joined the company three years ago along Manish Amde, who is now Intuit’s director of engineering. Amit and Amde both worked at Origami Logic, which was acquired by Intuit to help build out their data and AI architecture.
“Our data journey started at a place many of you would be familiar to many of you in the audience,” Amde said during a keynote address at Data + AI Summit. “Our data ecosystem was big, complex, and messy. We needed a strategy to unlock the full potential of this data for consumers and small business customers.”
One of the big challenges facing Intuit was the presence of multiple data silos. Decades of historical information contained in hundreds of thousands of database tables was critical for helping Intuit’s analysts and data scientists get insight into customer needs and to build new products. But it was scattered around the enterprise, which made it difficult to access. Copying the data is the most obvious solution, but that raises its own set of concerns around latency and correctness.
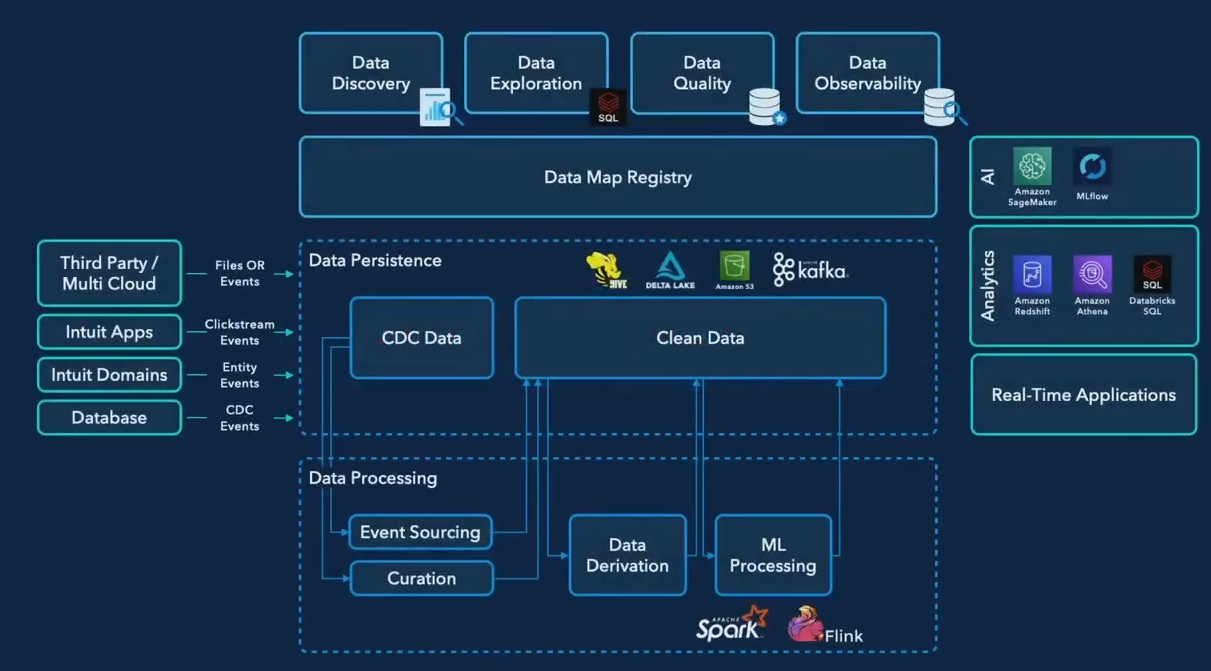
Intuit’s data architecture incorporates many moving parts (Image source: Intuit)
“To catalyze our data journey, we needed a single unified architecture that could break down the data silos and accelerate productivity for teams across the company,” Amde said. “This architecture needs to be capable of supporting diverse workloads at massive scale, for both storage and compute; to support real time applications via streaming; and it needed to be built on top of open source to give us the benefit of using best of class tools and an opportunity to give back to the community.”
A Data Journey
When Amit and Amde arrived at Intuit, they confronted a certain amount of technological baggage, like most successful, $10-billion companies would be expected to have. For starters, Intuit was an AWS shop and it ran a large “Parquet cluster” on the cloud. It was a happy RedShift and Athena customer and didn’t see a reason to leave them. It liked Apache Flink for the latency it could deliver for streaming.
Amit and Amde would need to work within these constraints (and others) for a solution. Both were already familiar with Databricks from their days at Oragami Logic, and knew what the platform was capable of. Amde also had worked with the Databricks founders back when Spark was a relatively unknown computing project at the UC Berkeley AMPLab.
“We collaborated on open source,” Amde said. “I contributed to the machine learning library back in the day. So we know how each other code. That’s where the trust comes from.”
The data leaders had several requirements for the new data architecture. For starters, internal users needed to be able to get results to queries and create data pipelines very quickly to foster an experimental culture. They also desired a storage repository capable of processing transactions.

Manish Amde, Intuit’s director of engineering
“We had Parquet and we had a humungous amount of data in our data lake,” Amde said. “But we wanted to have ACID like transactions so we can start doing almost-real time processing, both to write as well as to read, when there is business case that requires it.”
Above all, what Intuit needed was a single data architecture that could deliver data for multiple use cases.
“When we joined Intuit and started thinking about this data architecture, we did not think, oh we need to build one data architecture for the data scientists and yet another data architecture for the analytics. This was never our plan,” Amit said. “Because both of us have been around long enough to see that when you have multiple architecture, you have multiple data. People don’t read the same numbers. And we didn’t want that.”
Intuitive Rollout
Intuit decided to base its new data architecture on Databricks’ Delta Lake. By combining elements traditionally associated with a data warehouse (such as ACID transactions and quality guarantees) along with the scalability and flexibility advantages of a data lake, Databricks claimed to have found the happy medium between ungovernable data swamps and slow-to-adapt data warehouses.
A key element of Intuit’s strategy is something called a data map. The data map consists of three categories of data, including the physical layer (which contains information about where data and the code that generated it are located); the operational layer (which contains information about ownership, system dependencies, and data classifications); and the business layer (which captures the business context and exposes the logical model of the data in relation to other entities).
Automated transaction categorization is one example of AI use at Intuit (Image source: Intuit)
“All these three layers come together to help us answer all possible questions that our producers or consumers have about data in the lakehouse,” Amde said. “With that, we have been able to build a delightful data discovery experience, enabling users to search and browse data and explore relationships of other business entities.”
Two years into the new data project, things seem to be playing out pretty much as expected for Intuit. The data work isn’t done (data work is never done), but the company is starting to reap the rewards of its work.
Intuit’s lakehouse architecture accommodates Spark Streaming as well as Flink for real-time processing. Its analysts are able to access the same data set using Redshift and Athena as well as Databricks SQL and Photon-powered data science notebooks. The company is able to continue with Sagemaker as its primary data science development tool, backed up with MLFlow for automating machine learning work.
But the most important aspect of the lakehouse architecture is that different data personas at Intuit all have a consistent view of the same collection of data. That is a critical achievement that is hard to understate, according to Amit.
“[We have] emphasized how hard it is to get the culture of the company to start producing data at scale with logic and business meaning, so you don’t want to ask people to do it twice–once for the analyst and once for the data scientist,” Amit says. “It’s better because everybody is looking at the same data.”
Amit and Amde were also pleased to see that Databricks has committed to releasing the rest of its Delta Table spec into open source. The technologists had encouraged Databricks to do that, and the fact that the company did that eliminated one of the core perceived advantages of Iceberg, another open table format that the company was investigating (along with Hudi).
Related Items:
Is Real-Time Streaming Finally Taking Off?
Why the Open Sourcing of Databricks Delta Lake Table Format Is a Big Deal
Databricks Opens Up Its Delta Lakehouse at Data + AI Summit
Applications:
Enterprise Analytics
Technologies:
Middleware
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States