

February 1, 2022
Snowflake, AWS Warm Up to Apache Iceberg

(Maksim-Kabakou/Shutterstock)
Apache Iceberg, the table format that ensures consistency and streamlines data partitioning in demanding analytic environments, is being adopted by two of the biggest data providers in the cloud, Snowflake and AWS. Customers that use big data cloud services from these vendors stand to benefit from the adoption.
Apache Iceberg emerged as an open source project in 2018 to address longstanding concerns in Apache Hive tables surrounding the correctness and consistency of the data. Hive was originally built as a distributed SQL store for Hadoop, but in many cases, companies continue to use Hive as a metastore, even though they have stopped using it as a data warehouse.
Engineers at Netflix and Apple developed Iceberg’s table format to ensure that data stored in Parquet, ORC, and Avro formats isn’t corrupted as it’s accessed by multiple users and multiple frameworks, including Hive, Apache Spark, Dremio, Presto, Flink, and others.
The Java-based Iceberg eliminates the need for developers to build additional constructs in their applications to ensure data consistency in their transactions. Instead, the data just appears as a regular SQL table. Iceberg also delivered more fine-grained data partitioning and better schema evolution, in addition to atomic consistency. The open source project won a Datanami Editor’s Choice Award last year.
At the re:Invent conference in late November, AWS announced a preview of Iceberg working in conjunction with Amazon Athena, its serverless Presto query service. The new offering, dubbed Amazon Athena ACID transactions, uses Iceberg under the covers to guarantee more reliable data being served from Athena.
“Athena ACID transactions enables multiple concurrent users to make reliable, row-level modifications to their Amazon S3 data from Athena’s console, API, and ODBC and JDBC drivers,” AWS says in its blog. “Built on the Apache Iceberg table format, Athena ACID transactions are compatible with other services and engines such as Amazon EMR and Apache Spark that support the Iceberg table format.”![]()
The new service simplifies life for big data users, AWS says.
“Using Athena ACID transactions, you can now make business- and regulatory-driven updates to your data using familiar SQL syntax and without requiring a custom record locking solution,” the cloud giant says. “Responding to a data erasure request is as simple as issuing a SQL DELETE operation. Making manual record corrections can be accomplished via a single UPDATE statement. And with time travel capability, you can recover data that was recently deleted using just a SELECT statement.”
Not to be outdone, Snowflake has also added support for Iceberg. According to a January 21 blog post by James Malone, a senior product manager with Snowflake, support for the open Iceberg table format augments Snowflake’s existing support for querying data that resides in external tables, which it added in 2019.
External tables benefit Snowflake users by allowing them explicitly define the schema before the data is queried, as opposed to determining the data schema as it’s being read from the object store, which is how Snowflake traditionally operates. Knowing the table layout, schema, and metadata ahead of time benefits users by offering faster performance (due to better filtering or patitioning), easier schema evolution, the ability to “time travel” across the table, and ACID compliance, Malone writes.
“Snowflake was designed from the ground up to offer this functionality, so customers can already get these benefits on Snowflake tables today,” Malone continues. “Some customers, though, would prefer an open specification table format that is separable from the processing platform because their data may be in many places outside of Snowflake. Specifically, some customers have data outside of Snowflake because of hard operational constraints, such as regulatory requirements, or slowly changing technical limitations, such as use of tools that work only on files in a blob store. For these customers, projects such as Apache Iceberg can be especially helpful.”
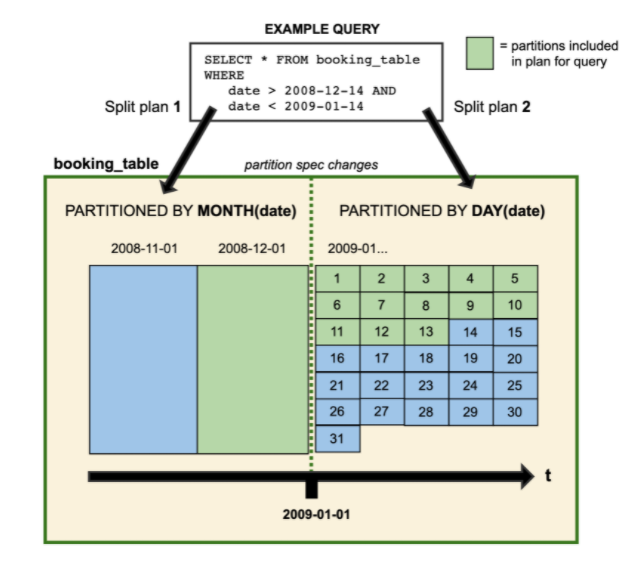
Iceberg also delivers better data partioning (Graphic courtesy Apache Iceberg)
While Snowflake maintains that customers ultimately benefit by using its internal data format, it acknowledges that there are times when the flexibility of an externally defined table will be necessary. Malone says there “isn’t a one-size-fits-all storage pattern or architecture that works for everyone,” and that flexibility should be a “key consideration when evaluating platforms.”
“In our view, Iceberg aligns with our perspectives on open formats and projects, because it provides broader choices and benefits to customers without adding complexity or unintended outcomes,” Malone continues.
Other factors that tipped the balance in favor of Iceberg includes Apache Software Foundation being “well-known” and “transparent,” and not being dependent on a single software vendor. Iceberg has succeeded “based on its own merits,” Malone writes.
“Likewise, Iceberg avoids complexity by not coupling itself to any specific processing framework, query engine, or file format,” he continues. “Therefore, when customers must use an open file format and ask us for advice, our recommendation is to take a look at Apache Iceberg.
“While many table formats claim to be open, we believe Iceberg is more than just ‘open code, it is an open and inclusive project,” Malone writes. “Based on its rapid growth and merits, customers have asked for us to bring Iceberg to our platform. Based on how Iceberg aligns to our goals with choosing open wisely, we think it makes sense to incorporate Iceberg into our platform.”
This embrace of Iceberg by AWS and Snowflake is even more noteworthy considering that both vendors have a complicated history with open source. AWS has been accused of taking free open source software and building profitable services atop to the detriment of the open source community that originally developed them (an accusation leveled by backers of Elasticsearch). In its defense, AWS says it seeks to work with open source communities and to contribute its changes and bug fixes to projects.
Snowflake’s history with open source is even more complex. Last March, Snowflake unfurled an assault on open source in general, calling into question the longstanding assumptions that “open” automatically equals better in the computing community. “We see table pounding demanding open and chest pounding extolling open, often without much reflection on benefits versus downsides for the customers they serve,” the Snowflake founders wrote.
In light of that history, Snowflake’s current embrace of Iceberg is even more remarkable.
Related Items:
Tabular Seeks to Remake Cloud Data Lakes in Iceberg’s Image
Apache Iceberg: The Hub of an Emerging Data Service Ecosystem?
Cloud Backlash Grows as Open Source Gets Less Open
Applications:
Enterprise Analytics
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States