

December 2, 2021
Better Machine Learning Demands Better Data Labeling

(everything possible/Shutterstock)
Money can’t buy you happiness (although you can reportedly lease it for a while). It definitely cannot buy you love. And the rumor is money also cannot buy you large troves of labeled data that are ready to be plugged into your particular AI use case, much to the chagrin of former Apple product manager Ivan Lee.
“I spent hundreds of millions of dollars at Apple gathering labeled data,” Lee said. “And even with its resources, we were still using spreadsheets.”
It wasn’t much different at Yahoo. There, Lee helped the company develop the sorts of AI applications that one might expect of a Web giant. But getting the data labeled in the manner required to train the AI was, again, not a pretty sight.
“I’ve been a product manager for AI for the past decade,” the Stanford graduate told Datanami in a recent interview. “What I recognized across all these companies was AI is very powerful. But in order to make it happen, behind the scenes, how the sausage was made was we had to get a lot of training data.”
Armed with this insight, Lee founded Datasaur to develop software to automate the data labeling process. Of course, data labeling is an inherently human endeavor (at least, in the beginning of an AI project, although towards the middle or the end of a project, machine learning itself can be used to automatically label data, and synthetic data can also be generated).
Lee’s main goal with the Datasaur software was to streamline the interaction of human data labelers and to guide them through the process of creating the highest quality training data at the lowest cost. Since it targets power users who label data all day, it has created function keys that accelerate the process, among other capabilities befitting a dedicated data labeling system.
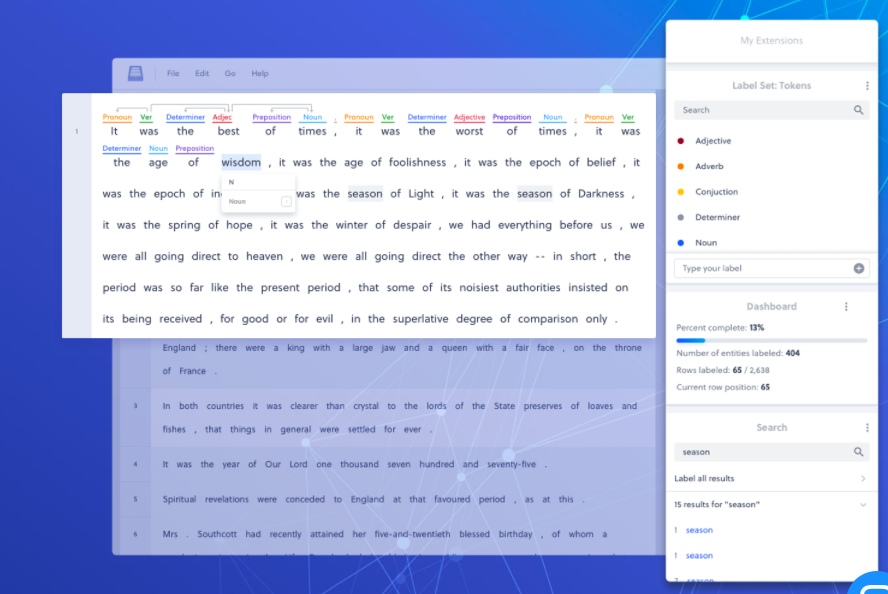
Datasaur helps customers with data labeling for NLP
But along the way, several other goals popped up for Datasaur, including the need to remove bias. Getting multiple eyeballs on a given piece of text (for NLP use cases) or an image (for computer vision use cases) helps to alleviate that. It also provides project management capabilities to clearly spell out labeling guidelines to ensure labeling standards continue to be met over time.
The subjective nature of data labeling is one of the things that makes the discipline so fraught with pitfalls. For example, when Lee was at Apple, he was asked to come up with a way to automatically label a piece of media as family appropriate or not.
“I thought, ‘Oh this is easy. I’m just going to rip off like whatever we have for movies, like PG, PG13, R,’” he said. “I thought it would be a really simple task. And then it turns out what Apple determines is appropriate is very different from what the movie industry determines is appropriate. And then there are a lot of gray area use cases. Singapore will have very different societal views on what is and is not appropriate.”
There are no shortcuts for working through those types of questions. But there are ways to help automate some of the business processes that help companies answer them, including providing a lineage of the decisions that have gone into answering those data-labeling questions. It can be done with spreadsheets, but it’s not ideal. This is what drove Lee to create Datasaur’s software.
“You wouldn’t ask your team to build out Photoshop for your designers. You just buy Photoshop off the shelf. It’s a no-brainer,” Lee said “That’s where we want Datasaur to be. You can use any tech stack you want. You can be on Amazon or Google or what have you. But if you just need to do the data labeling, we just to be that company.”
In the beginning, computer vision was the hottest AI technique for Datasaur’s customers. But lately, NLP use cases have been hot, particularly those that rely on large transformer models, like BERT and GPT-3. The company is now starting to get traction with its offering, which is being used to label a million pieces of data per week, and is used by companies like Netflix, Zoom, and Heroku.

Most of iMerit’s engagements are for computer vision
Datasaur is also used by specialized data labeling outfits, such as iMerit. With 5,000 employees spread across the world, iMerit has grown into an industry powerhouse for data labeling. The company has 100 clients, including many household names, that tap its network of data labelers to keep deep learning models flush with high-quality labeled data.
The subjective nature of data labeling keeps it from being a purely transactional thing, says Jai Natarajan, the vice president of marketing and business development for iMerit.
“Typically, we work with customers across various levels of evolution in their AI journeys,” he said. “We sit down and we try to figure out where they’re at, what the need is. It’s not exclusively tools or people or processes. It’s combination of all three. We call that our three pillars.”
Context is absolutely critical to the data labeling process. That may be because machines are so lousy at deciphering context. Or maybe it’s because AI use cases are constantly changing. Whatever the cause, the need is clear.
Natarajan shared the example of a garbageman on a truck to demonstrate how important context is to the development of high quality training data. Imagine there is a garbageman riding on the truck, and he keeps getting off at every house to empty the garbage and then gets back onto the truck. So the question for the data labeler is: Is the garbageman a pedestrian? Is he part of the truck? Or is he some other third thing?
“If you were counting vehicles, you wouldn’t care that he was getting on and off. The garbage truck would be of interest to you as an entity,” Natarajan said. “If you were trying to navigate other stuff and avoid hitting the garbageman, the garbageman’s movements will be of immense interest to you. And if you’re looking for suspicious behavior, you want to exclude the garbage man out of a set of similar behaviors where people are kind of darting out of cars and grabbing stuff from your house.”
It may not be Schrodinger’s cat. But clearly, the garbageman has different states of being, depending on one’s perspective. For the data labeler, this illustrates the fact that one piece of data can have different labels at different times. Sometimes, there’s no single answer. In other words, it’s a very subjective game.

(Image courtesy Toloka)
The subjectivity of data–and the danger to a company’s reputation if this subjectivity is ignored–is one reason why Natarajan believes companies may want to rethink how they’re going about the data labeling process. The potential for missing interesting anomalies in the data, or corner cases, is another.
“It cannot just be a transactional relationship. It has to be a partnership,” he said. “I have to be able to point out corner cases without being penalized for it on my quality metrics, because corner cases are a legit source of confusion. It doesn’t mean I’m bad at my job. It just means that, hey, we found something that doesn’t fit in the guidelines.”
Being meticulous about the data labeling process is important for improving the quality of data, which has a direct impact on the quality of the predictions made by the machine learning models. It can make the difference between having predictions that are accurate 60% to 70% of the time, and getting into that 95% range, Natarajan said.
Depending on the use case, that accuracy could be critical. For example, it a customer is building a model to identify shoplifting from a video camera, there’s a big difference between the penalty for a false negative (missing the theft) and a false positive (accusing an innocent customer), Natarajan said.
The combination of people, processes, and tools–not to mention the experience of working with hundreds of customers over the past decade–helps set iMerit apart in an increasingly crowded field of data labeling service providers, Natarajan said. The ability for a customer to have continuity with certain data labelers, as well as iMerit’s ability to guarantee a certain level of quality in the data that it labels (70% of which is image data and 30% of which is text) is a product of that experience.
“Let’s say I’m doing 100,000 images for you. Are going to review 100 images, or 1,000? What’s a good sample size? What is quality?” Natarajan said. “A services workflow by itself doesn’t every company’s problem. I think most customers in our conversation, as they evolve from stage one to two and three, they start needing more and more of that solution. They can no longer just throw images into a tool, work with random people, and satisfy their business needs through that. They outgrew that very quickly.”
Related Items:
Training Data: Why Scale Is Critical for Your AI Future
Training Your AI With As Little Manually Labeled Data As Possible
Three Ways Biased Data Can Ruin Your ML Models
Applications:
Artificial Intelligence
Sectors:
Retail
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States