

September 16, 2021
One on One with Google Cloud Product Director Irina Farooq

Irina Farooq, Director of Product Management, Smart Analytics, Google Cloud
In May, Google Cloud announced Dataplex, its entry into the world of data fabrics. Datanami recently caught up with Irina Farooq, who joined Google Cloud as director of product management of smart analytics at Google Cloud, to discuss the state of big data management, the role of data fabrics, and the pending launch of Dataplex.
Datanami: Irina, it’s nice to make your acquaintance. In your view, what are the biggest challenges that enterprises are facing as it relates to their data?
Irina Farooq: Enterprises are facing a choice of either unifying their data, and as a result having unified governance, metadata, and accessibility, or distributing their data, which results in data sprawl across disparate ecosystems. However, the reality is most enterprises have their data distributed and this will remain the case in the foreseeable future. With that, enterprises are constantly facing the challenge of “how do I enable all my end users with high quality data?” Additionally, the number of tools and the number of types of end users will only continue to grow exponentially, as the amount of data increases.
We want to enable the end user to gain access to high quality data, and make sure that they don’t compromise any of the governance or security policies. Enterprises are trying to build a lot of the glue themselves to build pipelines and manage governance, which in turn slows down innovation. That’s the kind of [environment] that we’re seeing and this is why we think they need a unified data platform to help solve some of those challenges.
Datanami: Can companies just use the tools and techniques that they’ve used in the past 10 or 20 years going forward, or does this require new tools and techniques to make it work?
Farooq: Ten to 20 years ago, the scale of data was completely different. Data was also much more segmented, almost like one room in your house, versus being the foundation for everything you do. The scale, complexity, distributed nature, and types of data has drastically changed. There is now data from many different sources such as image processing and video processing, to structured data, and all of the different use cases and innovation that we’re trying to enable within the enterprise.
Datanami: What do you see as the opportunities then for businesses to improve their data strategies?
Farooq: One opportunity is thinking about how to avoid locking yourself in, and how to build a platform that’s open, flexible, and secure. Another opportunity to consider is making sure that you’re able to leverage the latest innovation in the different tools and frameworks and services, but without compromising governance and security. That has to underpin the solution.
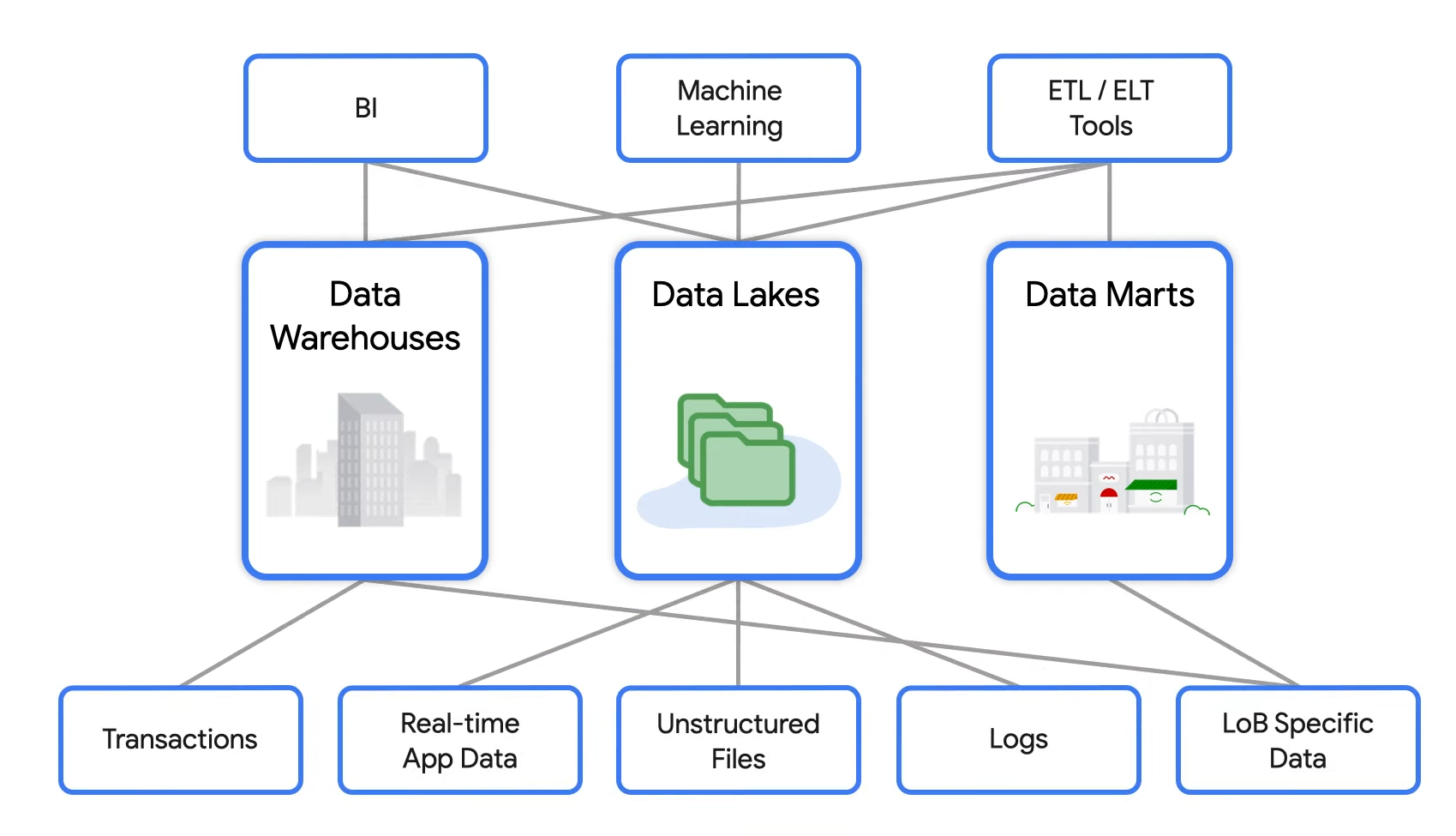
Managing and governing diverse data sets for analytics and AI use cases is a challenge (Image source: Google Cloud)
As we consider those things, it helps to think about what businesses are trying to do. Etsy is a perfect example. They completed their migration to Google Cloud two years ago, but the reality is, what they’ve been able to accomplish is shift around 15% of their workforce from thinking about infrastructure management, to thinking about the customer experience. The question now is “how do I use data to reinvent the customer experience, and increase the number of IT experiments by over 100%?’
Datanami: It seems like there’s that tension between letting the users loose on the data to do interesting things, and then also maintaining control over it. So how do you attack that problem?
Farooq: This is where some of our latest announcements that are close to my heart play a role. One product that I worked on, Dataplex, we launched this year at our inaugural Google Data Cloud Summit. It is making an impact in helping businesses to effectively automate the data management to help address that tradeoff. You need to centrally manage your data across a distributed footprint and make sure the data is accessible to all the tools with metadata-led management.
Datanami: Data fabrics are rising in popularity, but they’re not silver bullets. A data fabric can’t just magically solve all my problems, right?
Farooq: Absolutely, it’s always the people and processes. The data fabric will not magically define your governance strategy, but it will help enable governance. Data fabric will help automate the processes and the decisions that you’re trying to make and the best practices that you’re trying to put in place.
Datanami: Can you walk me through how that will impact an individual user and their individual workflow?
Farooq: Equifax is a good example. Equifax is using Dataplex to help automate its data management and governance, allowing data stewards to set up formal policies across their data, and then individual users can access the data in the tools of their choice. They know that they have access to the right data, to high quality data that they can trust, and to the fullness of data that they should have access to, irrespective of the tools they use.

Data fabrics, which provide a common management layer for diverse data assetts, are growing in popularity (amiak/Shutterstock)
Datanami: How does this data fabric fit in with Google Cloud’s multi cloud and hybrid cloud strategy?
Farooq: As you know, we’ve been committed to a multicloud and hybrid cloud initiative, through our services like BigQuery Omni. As you build your data fabric, Google Cloud will help you with the distributed footprint as you would have across a single cloud.
Datanami: How much work is involved in connecting Dataplex to all these systems?
Farooq: There’s a lot of work and intelligence that we’re building in. It’s almost like we’re automating the unglamorous work. A lot of the intelligence there is actually understanding the underlying system, connecting the metadata, propagating the metadata, and giving the assurance that you have insight and understanding of your data.
We’ve been saying to our customers that metadata is the new black. If you’re going to manage your distributed footprint, you need to understand your metadata, and from there you can manage your data to both govern and propagate that. A lot of it is automating the unglamorous work, or the glue that customers are currently doing themselves and making data more accessible.
Datanami: It almost sounds like we’re going back to the data warehouse days. The data needs to be highly structured and totally controlled right before it can be exposed to the users in the data warehouse.
Farooq: What’s different is the variety and footprint of your data. That’s exactly the point. We did data warehousing and then within that data warehouse you have the metadata, the governance, etc. You have data lakes and a prescriptive way to do that. But the reality is the customer data is distributed across warehouses and data lakes and data marts and across that multicloud as well as hybrid cloud footprint. So the difference is that we now embrace the modern variety of data, as well as distribution of the data. It used to be that BI was the destination for data warehousing. Now you have data scientists. You have smart applications. You have all of the different types of data engineers, all the different types of end users, that need to access all the data that’s distributed.
Datanami: You spoke about the need for centralization. Will centralization hold people back?
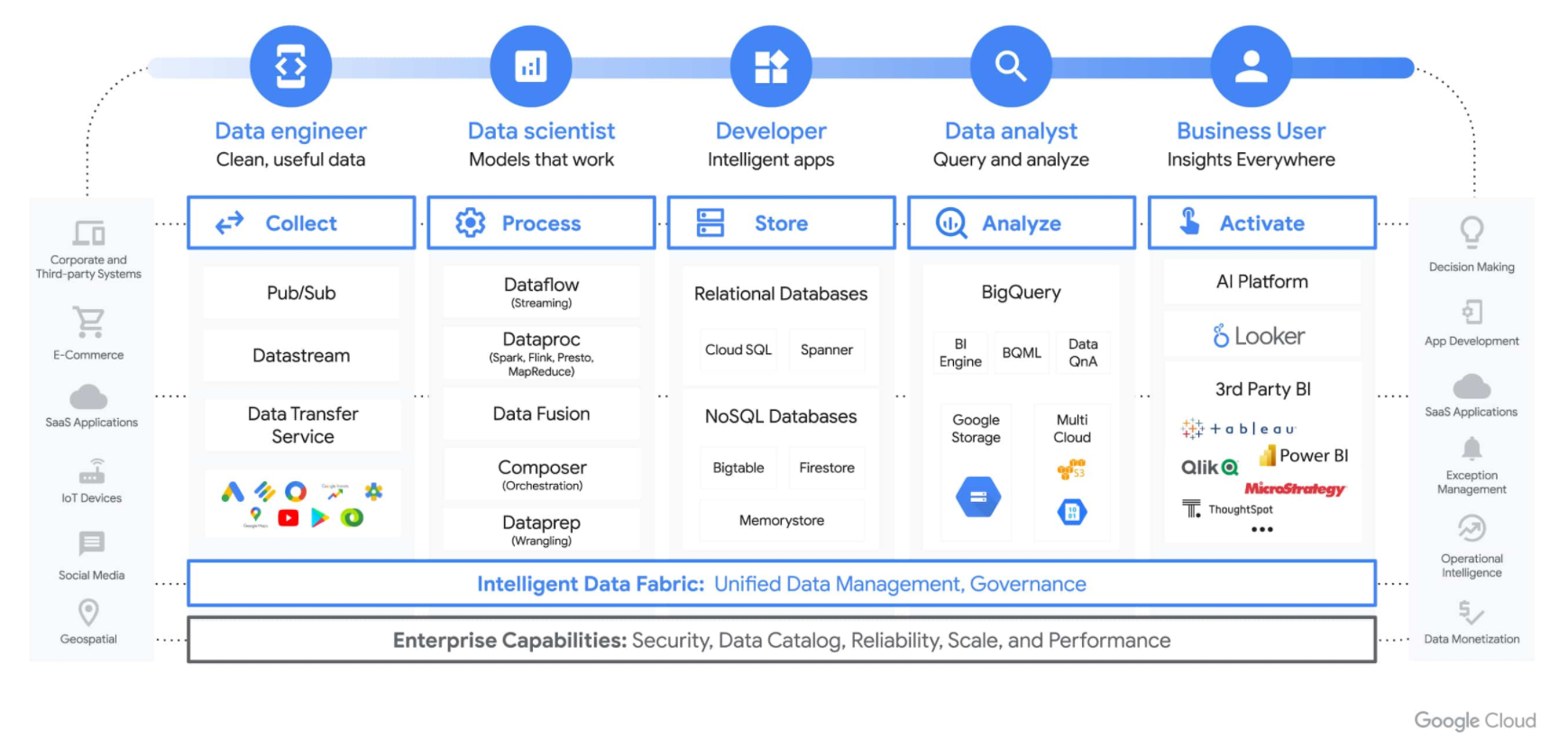
Google Cloud DataPlex is a data fabric offering that serves multiple personas involved in the modern data supply chain (Image source: Google Cloud)
Farooq: We’re not centralizing the data, and we’re not centralizing access to data. What you’re centralizing in effect is the control plane to help apply policy. But you’re not centralizing it to one single body. So for customers who want to embrace the data mesh architecture and more distributed architectures, they can allow different data owners within those organizations, provide the governance, the data quality around their data and expose it to the organizations.
Datanami: That sounds like a huge challenge is whether this is technologically a solvable problem?
Farooq: Absolutely we believe that it is. And we are not reinventing the wheel. We are standing on the shoulders of giants. There’s investments that we’ve made in Google Cloud and with the rest of our portfolio. Think about the scalability of BigQuery and Spanner. The integrations we’ve made within the cloud to make sure that we can federate, and that we democratize the data with BigQuery and Looker, for
example, and have that accessibility.
Datanami: How does AI apply to this? It plays an important role in managing data, right?
Farooq: Absolutely and we’re really investing in data intelligence capabilities to help you understand the quality and sensitivity of your data, so you can automatically apply policies to potentially sensitive data within your environment. While you may want to do Machine Learning and AI on your data, we first apply Machine Learning and AI to your data, to ensure you have high quality data in the first place. You want to do AI on data, but you need to apply AI to it to know that you have the right data.
Datanami: Is this approach going to apply to streaming data products like cloud Dataflow as well as data at rest and databases, data lakes, etc.?
Farooq: Absolutely. The goal is to start with analytics, and Dataplex out of the gate integrates with products like Dataflow, DataFusion, BigQuery, GCS, Google Cloud AI, and others. And we’re only going to expand the scope of that. But the goal is all your data, so streaming and batch data as well as structured and unstructured and semistructured data, so you have unification of that capability.![]()
Datanami: It sounds like that’s in the road map but maybe it’s not there quite yet?
Farooq: Dataplex is in preview so stay tuned for the full announcement of the capabilities. But a lot of these initial capabilities are available in our preview product.
Datanami: Can you tell me when Dataplex is going to become GA?
Farooq: We’re not sharing the date yet, but stay tuned. As you know, we have our big conference coming, Google Cloud Next, so we’ll be sharing a lot of updates on our entire product portfolio there.
Datanami: A lot of tool vendors are chasing the same problem. Is there going to be a place for them in Dataplex or is this a Google-only solution?
Farooq: The openness approach has been key to us. We want to enable partners, so even when we launched in preview, there was a broad partner ecosystem, like Starburst and Collibra and different vendors that we’re working with out of the gate. So Dataplex actually provides an open metastore API, and all the partners that are integrated with our existing metastore can take advantage of that. And then our goal is more and more to expose policies to vendors like Collibra, or analytics engines like Starburst and our partners in the broader ecosystem.
Datanami: Thank you, Irina, for your time.
Related Items:
Data Fabrics Emerge to Soothe Cloud Data Management Nightmares
Google Cloud Tackles Data Unification with New Offerings
Big Data Fabrics Emerge to Ease Hadoop Pain
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States