

January 29, 2020
The Next Generation of AI: Explainable AI

(BAIVECTOR/Shutterstock)
For most businesses, decisions — from creating marketing taglines to which merger or acquisition to approve — are made solely by humans using instinct, expertise, and understanding built through years of experience. However, these decisions were invariably susceptible to the nuances of human nature: decisions included bias, stereotypes and inconsistent influences.
And while humans eventually shifted into considering data, the human brain can’t process it in large amounts. Humans naturally prefer summarized content when making decisions. Unfortunately, these summaries don’t always include relevant data and details, and some are still marred with bias.
We’re now in the “Decisions with Humans + Data + AI” phase. With the advent of the cloud and the massive storage and compute power that came with it, analyzing complex data sets became fast and efficient. With the additional information processing capabilities of AI, we’re able to process vast amounts of information quickly and uncover relationships in data that would have otherwise gone unnoticed.
AI solutions produce outcomes and predictions for multiple use cases across various industries much faster than a human brain can process. From predicting cancer in patients and potential hospital stay times to making credit-lending decisions and personalizing shopping recommendations, AI has a broad reach.
There are limitations though. Humans have access to additional ambient information when they make decisions including being empathetic, and this is difficult for AI to comprehend. When we leave the decisions to AI, without intervening when needed, we might get incorrect or unusual outcomes. When we leave decisions only to AI, there are unanswered questions. Do we know why AI made those predictions? What was the reasoning behind it? Are we certain there is no inherent bias? Are we certain we can trust the outcomes? How do we course-correct if we don’t know?

(amasterphotographer/Shutterstock)
The Next Phase: Explainable AI
Complex AI systems are invariably black boxes with minimal insight into how they work. Enter Explainable AI.
Explainable AI works to make these AI black-boxes more like AI glass-boxes. Although businesses understand the many benefits to AI and how it can provide a competitive advantage, they are still wary of the potential risks when working with AI black-boxes. So now the focus is moving towards an explainability infused approach into the ‘Decisions with Humans + Data + Explainable AI’ phase.
When we unlock the AI black-box, we have access to the best possible information to make the best possible decisions. We have our human instinct, access to ambient information, as well as experience we’ve built through years of conducting business. With data, we have access to vast amounts of information that influence business decisions: From what customers did at points in time to how we consume content online, there is no dearth of information. With AI, we have the ability to process these vast amounts of information easily to generate fast and efficient decisions.
And with Explainable AI, we now know the “why” behind these decisions and how input features are influencing outputs. When humans have access to this information when making decisions, the overall decision process is better informed and results in more accurate outcomes.
Explainable AI in the Broad AI Lifecycle
To better understand Explainable AI, let’s consider the end-to-end AI lifecycle to see where and how Explainable AI fits in.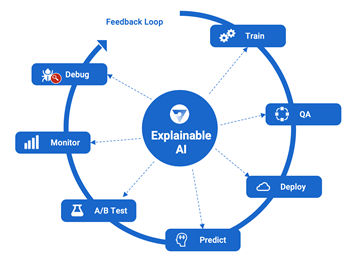
Below is how a typical AI project flows today:
- Identify a use case for AI (credit lending, cancer prediction, etc.)
- Access historical data from existing sources
- Build and train the AI model
- Test and validate the AI model
- Deploy the model into production
- Monitor the model to ensure continued optimal performance
Let’s look at an AI lifecycle example through the Explainable AI lens.
Example Use Case: Credit Lending
First let’s review the credit lending use case. A credit lending agency wants to build an AI model to generate credit decisions for their customers. These decisions could range anywhere from increasing credit card limits to selling new credit products.
Access Historical Data
In order to build this model, the firm uses existing historical data they have access to – data built over their many years of providing credit products to their customers.
Build and Train the AI Model
The firm uses this historical data to train and build a credit lending AI model.
Test and Validate the AI Model
Once they build the model, they use explanations to validate the model – what sorts of credit predictions is the model making? The model creators (data scientists and developers) can access individual explanations for each prediction to better understand what influenced that prediction.
For example, explanations provide insight into the percentage influence of a decision input to the decision. In this case, it could be that the annual income of an applicant influenced the AI model’s prediction by 20%.

(Macrovector/Shutterstock)
Model creators can also view a subset of the global training dataset to see how the input feature influence changes for a subset when compared to the global dataset. In this case, it could be that the annual income was influencing the prediction by 20% in the global dataset, but when considering just the subset of “gender = women,” the percentage influence for annual income went up to 25%. So we can infer that when the data is split by gender, the annual income plays a bigger role in determining credit decisions.
Consider another question: is the model regularly rejecting credit products for users from a particular ZIP code? Again, by slicing the data and viewing explanations for each outcome, model creators are better able to understand the “why” behind these decisions. It’s possible the historical data might not have any representatives from that ZIP code. It’s also possible that residents in this ZIP code are overwhelmingly from a particular race. The credit lending agency can then be viewed as potentially biased towards this race.
In this case, there are no direct bias-inducing factors (like race or ethnicity), but rather inferred bias factors (like ZIP code). Because these model creators (humans) have access to these explainable AI outcomes, they are now able to build and deploy better AI models into production.
Deploy the Model into Production and Monitor It
Explainable AI works for models in production in a similar manner. The data a model encounters in production might be vastly different from training data, and explanations provide much needed insight to solve critical issues. Consider the case of explainable monitoring: when a model is in production it needs continuous monitoring to watch out for operational challenges like data drift, data integrity, model decay, outliers, and bias. With explainability, model creators get access to actionable monitoring alerts that show them the ‘why’ behind these operational challenges like data drift or outliers, so they can quickly solve for them.
A Future with Explainable AI
Explainable AI is the future of business decision-making. Explainable decision making plays a role in every aspect of AI solutions from training, QA, deployment, predictions, testing, monitoring, and debugging. In the next 10 years, Explainable AI will be a prerequisite for deploying any AI solution in business. Without it, AI solutions will lack transparency and trust, and prove risky. Explainable AI enables businesses to build trustworthy, ethical, and responsible AI solutions.
About the author: Anusha Sethuraman is a technology product marketing executive with over 12 years of experience across various startups and big-tech companies like New Relic, Xamarin, and Microsoft. She’s taken multiple new B2B products to market successfully with a focus on storytelling and thought leadership. She’s currently at Fiddler Labs, an explainable AI startup, as head of product marketing.
Related Items:
Opening Up Black Boxes with Explainable AI
Real Progress Being Made in Explaining AI
Applications:
Artificial Intelligence
Technologies:
Middleware
Sectors:
Financial Services
Vendors:
Fiddler Labs
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States