

November 13, 2019
Deep Learning Has Hit a Wall, Intel’s Rao Says

(HQuality/Shutterstock)
The rapid growth in the size of neural networks is outpacing the ability of hardware to keep up, said Naveen Rao, vice president and general manager of Intel’s AI Products Group, at the company’s AI Summit yesterday. Solving the problem will require rethinking how processing, network, and memory work together, he said.
“Over the last 20 years we’ve gotten a lot better at storing data,” Rao said during a one-hour presentation at Intel‘s AI Summit 2019 in San Francisco Tuesday. “We have bigger data sets than ever before. Moore’s Law has led to much greater compute capability in a single place. And that allowed us to build better and bigger…neural network models. This is kind of a virtuous cycle and it’s opened up new capabilities.”
The growing data sets means more data for training deep learning models to recognize speech, text, and images. The largest companies in the world have invested aggressively to obtain the hardware, software, and technical skills necessary to build AI solutions that give them a competitive advantage. Computers that can identify images with unparalleled accuracy and chatbots that can carry on a somewhat natural conversation are two prime examples of how deep learning is impacting people’s day-to-day lives.
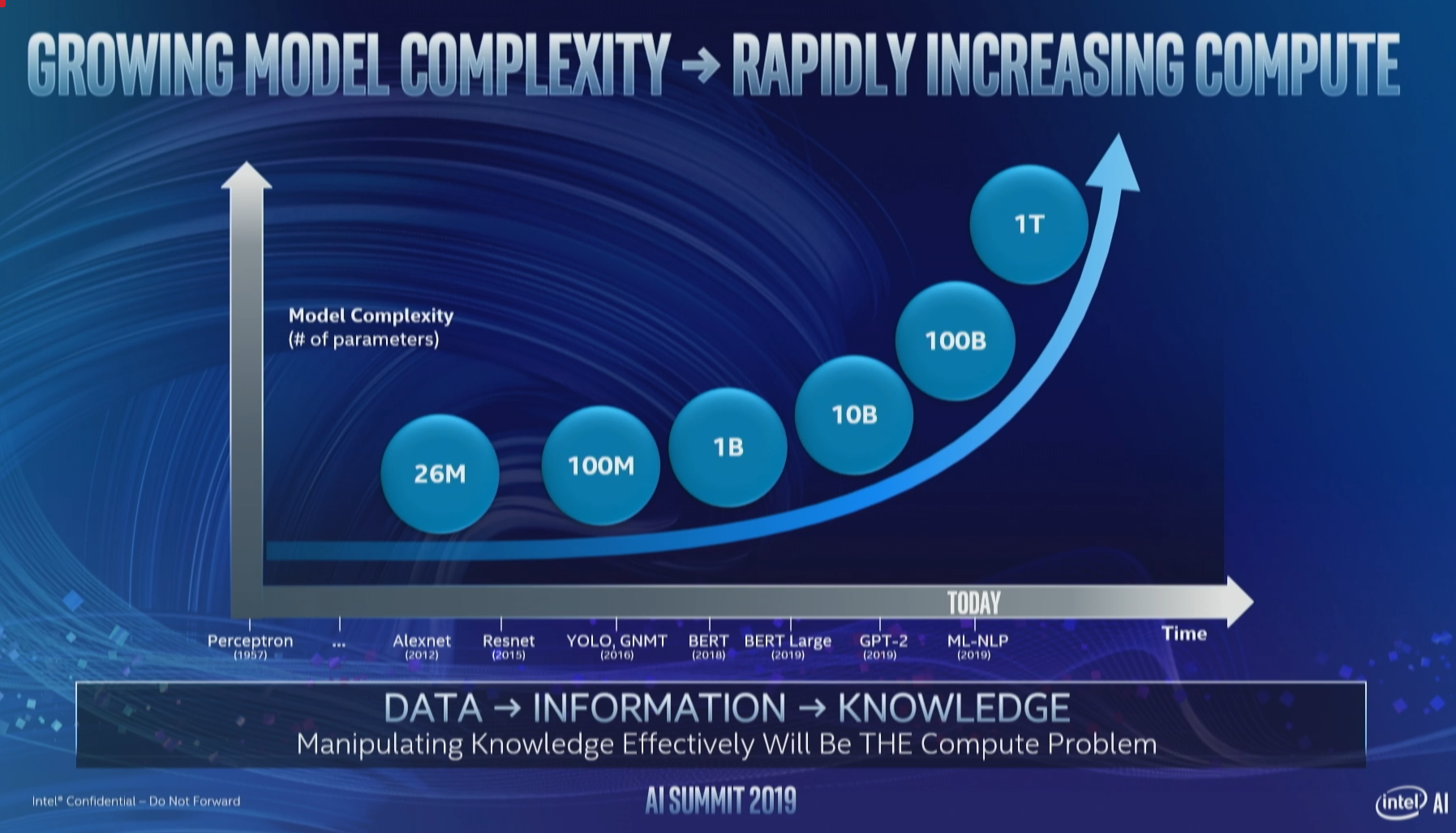
The number of parameters in the biggest neural network models is growing exponentially, Intel says (Image courtesy Intel)
This is the cutting edge of AI at the moment, but it’s only available to the biggest technology firms, such as Google and Facebook, and a handful of big companies in private industry that have the ways and means to tackle such challenges. But lately, the neural networks have grown so big, with so many parameters to calculate, that they’ve essentially maxed out the hardware they run on, Rao said.
“The trend to be aware of is that the number of parameters–call this the complexity of the model,” Rao said. “The number of parameters in a neural network model is actually increasing on the order of 10x year on year. This is an exponential that I’ve never seen before and it’s something that is incredibly fast and outpaces basically every technology transition I’ve ever seen.”
The problem is that the growth of neural networks is not sustainable given today’s hardware capacity, the co-founder of Nervana said. “So 10x year on year means if we’re at 10 billion parameters today, we’ll be at 100 billion tomorrow,” he said. “Ten billion today maxes out what we can do on hardware. What does that mean?”
Just as the slowdown in Moore’s Law due to physical limits in miniaturization of circuits and heat displacement forced chip and computer makers to get creative with how they package and deliver computers, the entire computer industry will need to get creative in how it tackles the wall looming in AI.

Naveen Rao, vice president and general manager of Intel’s AI Products Group, speaks at AI Summit on November 12, 2019
According to Rao, the solution will require taking a new approach to fitting together the compute, memory, and networking ingredients that system architects have at their disposal. Software also factors into the equation, and is something that Intel is also investing in.
“Right now our biggest customers are actually hitting hardware constraints. That seems to be the limiting factor in what allows them to go bigger,” Rao said. “When dealing with multiple racks of servers, the speed at which data can be moved is actually the bottleneck. And we’re looking to solve that through a variety of needs.”
For Intel, it means rethinking how all the parts fit together. “What we really shoot for is all those chips working in concert to solve a single problem,” Rao said. “All these capabilities – compute, memory, communication – integrated at the system level will really drive the next generation of AI solutions.”
Intel is “skating to where the puck is going” in an attempt to get in front of this looming wall, Rao said. The gravity of data and the cost in moving it seems to indicate that a good chunk of the AI work in the future is destined to move out the data center, where its Xeon processor is king, and be performed at the edge.
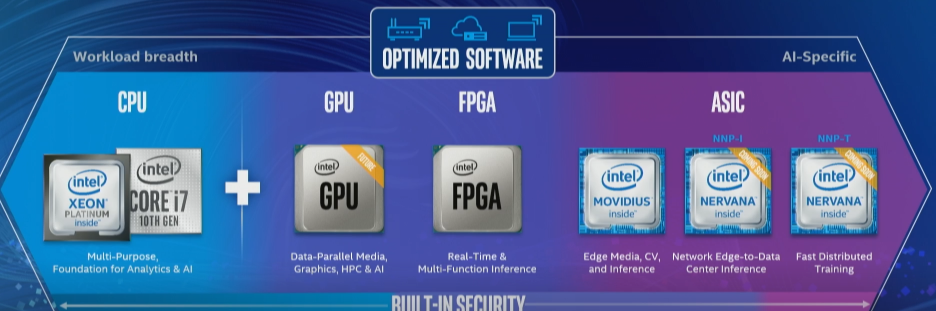
Intel is developing a range of solutions to address the AI training wall (Image courtesy Intel)
Intel is working on various chips for edge processing. It is already shipping two ASICS in its Nervana Neural Network Processors (NNP) line, including the NNP-T1000 for training and the NNP-I1000 for inference. And it also has Keem Bay, the latest edition of its Movidius Myriad Vision Processing Unit (VPU) that it unveiled yesterday.
“There’s a clear trend where the industry is headed to build ASICS for AI,” Rao said. “It’s because the growth of demand is actually outpacing what we can build in some of our other product lines.”
GPUs and FPGAs will have a place in the Intel lineup. “Beyond CPU, we’ll be bringing discreet GPU to the product family very soon,” Rao said. “This will allow us to have superior HPC performance with acceleration on a variety of applications. I mentioned FPGAs are at use in our partner Microsoft data center.”
And let’s not forget Optane, the memory-class storage technology that Intel is now shipping, and which Rao says will help “fill some gaps” in the traditional compute hierarchy. “What we bring to the market with Optane technology is actually new hierarchy that fills some of those gaps and allow you to move data closer and faster to compute.”
Intel is attacking the AI training wall at various levels, with new chip architectures and new memory technologies. And while Rao was adamant that the communications portion must also be part of the solution, Intel doesn’t seem to have a horse in that race at the moment. The company, you will remember, killed its Omni-path interconnect technology earlier this year.
Obviously, Intel can’t solve the AI processing problem on its own, and Rao was right to bring partners into the equation.
Related Items:
Intel Debuts New VPU Chip at AI Summit
Intel Confirms Retreat on Omni-Path
Applications:
Artificial Intelligence
Technologies:
Processors
Vendors:
intel
Tags:
AI Summit, ASIC, CPU, deep learning, fpga, GPU, Naveen Rao, neural network, Optane, parameter, VPU
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States