

August 7, 2019
Data Catalogs Seen as Difference Makers in Big Data

via Shutterstock
You can’t get insights using big data techniques without the data. That much is clear. But where, exactly, is the data you need? Where does it reside, and how can you get access to it? The answers to those questions are not always directly obvious. But with the help of data catalogs, organizations are discovering that data doesn’t have to be so hard to find after all.
More than a decade into the “big data” era, we’re finally figuring out that Hadoop isn’t the answer to all of our data problems. Instead of centralizing data in giant HDFS clusters meant to serve the data needs of entire companies or departments, organizations are once again building one-off systems to handle specific data storage, processing, and analytic tasks.
This is exacerbating the data silo problem, but many organizations would rather tackle that challenge instead of wrestling with Hadoop and dealing with the complexity that a company-wide Hadoop implementation brings. It’s the devil you know versus the devil you don’t.
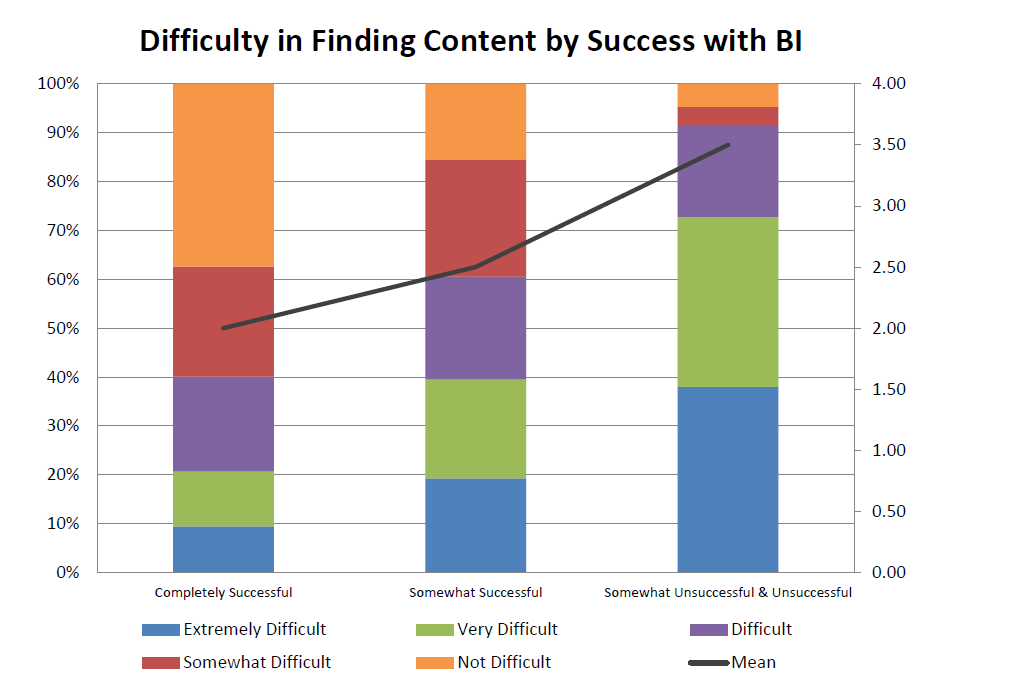
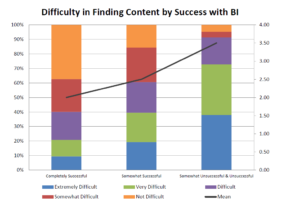
Companies report difficulty accessing data (Source: Dresner 2018 Data Catalog Study)
With momentum behind de-centralization of data, it shouldn’t be surprising that companies are reporting trouble finding their data. According to a “Wisdom of the Crowd” survey conducted by Dresner Advisory Services, 47% of respondents to a survey indicated they experienced difficulty in locating and accessing relevant analytic content (which includes data, models, and metadata).
When Dresnser sliced the data according to the level of BI success achieved by organizations, they found a clear correlation between success and the level of difficulty experienced by organizations. Organizations that are successful at BI reported much less difficulty in finding content compared to those who were less successful at BI. (It also discovered a correlation between organizations that have hired a chief analytics officer or a chief data officer and those who report difficulty finding content.)
Data catalogs present a way to reduce the difficulty of finding data, whether it’s used for a BI initiative or for machine learning and AI. In some cases, the catalogs can deliver big impacts to the bottom line. According to a Forrester report titled “Machine Learning Data Catalogs Put The Entire Business In Full View,” companies that utilize MLDCs are more than two times more effective at democratizing the use of data and enabling self-service.
“Early adopters of MLDCs have seen impressive results overcoming the most difficult challenges,” Forrester writes in the report, which was commissioned by Waterline Data, a provider of data catalog software. “They are more likely to report enhanced security and privacy, optimized use of disparate data sources, and improved data self service.”
Forrester’s survey shows that nearly half of MLDC adopters have achieved, or expect to achieve, a range of benefits, including:
- Better control over data management and data governance;
- Improved understanding of data utilization and behavior for data security and support;
- Better understanding of the data to drive insights and actions;
- and the ability to automate a significant number of developmental, administrative, and governance tasks.
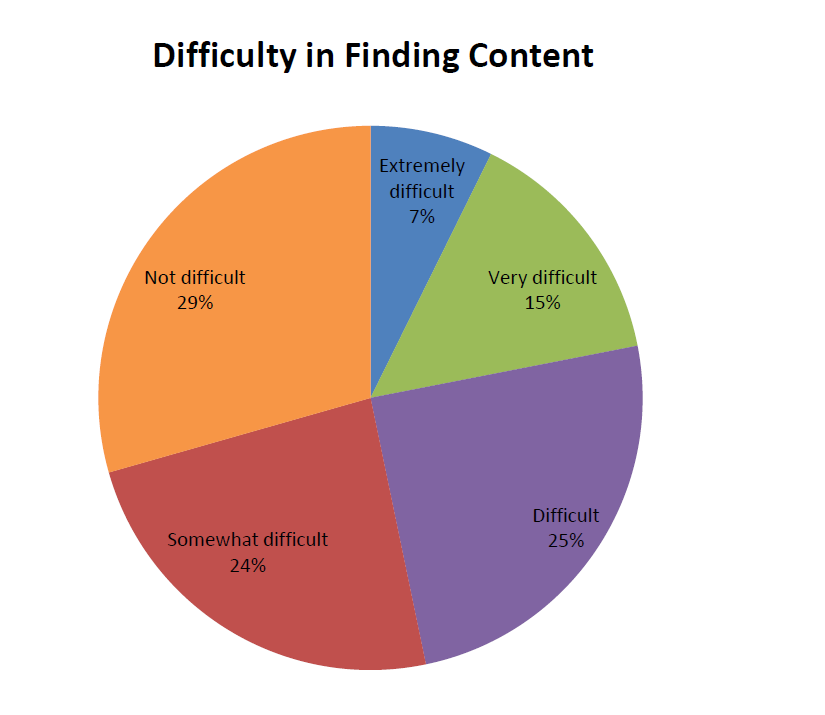
Success at BI is linked with ability to access data (Source: Dresner 2018 Data Catalog Study)
Compliance with GDPR and similar data regulations is a big driver of adoption of MLDCs and traditional data catalogs, according to Forrester, which found that 40% of firms report data security and privacy is a big factor in their MLDC deployment. Other big factors include improving the customer experience (49%), improving data governance (44%), and improving decision-making (42%). You can access the Forrester report here.
GigaOm also cited regulatory compliance as a big driver in the adoption in data catalogs. But the improved defensive posture that data catalogs can bring is just the beginning, writes analyst Andrew Brust in a December GigaOm Research Byte titled “Enterprise Data Governance with Modern Data Catalog Platforms.”
In the research brief, Brust cited compliance, improved data lake ROI, unification of the data landscape, and united data and business as major benefits of data catalog adoption. “…[C]atalogs protect enterprises from regulatory jeopardy and benefit them by delivering more value from existing assets,” he writes.
Data catalogs emerged as a hot big data technology a couple years back, and it would appear that the product category is continuing to see big adopting in 2019. Among the key players in the catalog business cited by Brust are: Alation, Collibra, IBM, Infogix, Informatica, Io-Tahoe, Podium Data (acquired by Qlik), Talend, Unifi Software, and Waterline Data.
There are a set of core capabilities that each data catalog brings. Nearly all of them include a data dictionary that defines terms, as well as a business glossary that lets users search for data sets using commonly used business terms. Hadoop and S3 integration is a prerequisite supported by most (if not all) data catalogs at this point. Shopping cart-style interfaces that allow users to browse data sets and then check them out are also quite common.

Data catalogs bring offensive and defensive benefits to big data users (Source: GigaOm)
Most (if not all) of the data catalogs utilize metadata to classify data, and also support manual tagging of specific data sets. The capability to have personally identifiable information (PII) flagged and to restrict access is fairly common. On-prem and cloud deployments can be found among a number of the data catalog players.
But there are also differences among the catalogs. You can read for yourself what Brust considers to be the benefits and advantages that each of these platforms brings. Suffice it to say, some of differentiating features that Brust identifies include:
- Automated generation of plain-English titles of data objects using machine learning;
- Use of machine learning to power data discovery and to tag data;
- Creation of KPIs for various aspects of the data, such as data quality, status, and popularity;
- Integration with non-standard data sources, including NoSQL databases and mainframes;
- Automated generation of recommended views of data for users;
- Crowdsourced ratings of data sets;
- Pre-built integration with data cleansing tools, such as Trifacta and Paxata;
- Built-in data quality monitoring;
- Built-in SQL query and visualization capabilities;
- Pre-built integration with third-party BI and visualization tools, like Tableau, Microstrategy, and Salesforce Einstein;
- Integration with Hadoop security and access tools, such as Apache Ranger, Apache Sentry, Cloudera Navigator, and MS Active Directory and open systems LDAP methods.
Data catalogs are emerging as a must-have technology for data-driven organizations. Whether it’s delivered as a stand-alone product or as part of a bigger analytic suite, the functionality that data catalogs deliver are critical to enabling self-service access to a range of stakeholders.
Related Items:
Five Tips for Winning at Data Governance
How the Machine Learning Catalogs Stack Up
Tools Emerge to Comply with California Data Law
Applications:
Data Mining
Technologies:
Frameworks
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States