

July 17, 2019
Object and Scale-Out File Systems Fill Hadoop Storage Void

(sergeymansurov/Shutterstock)
The rapid growth of data and the changing nature of data applications is challenging established architectural concepts for how to store big data. Where once organizations may have first looked to large on-premise data lakes to centralize petabytes of less-structured data, they now are considering scale-out file and object storage systems that give them greater flexibility to store data in a way that meshes with the emerging multi-cloud and hybrid paradigm.
Since Hadoop’s hype bubble burst, enterprises have looked for other ways of storing the gobs of semi-structured and unstructured data that accounts for the bulk of the big data deluge. Enterprises want to use this data for a variety of use cases, not the least of which is training machine learning models to automate decision-making.
While reports of Hadoop’s death are premature, the notion that Hadoop Distributed File System (HDFS) clusters will store the majority of enterprise’s data clearly is not panning out. Hadoop, like every overhyped technology that came before it, has seen its soaring stock marked down as people reassessed its capabilities. Cloudera, the sole Hadoop distributor at this point, has been pivoting away from Hadoop for a while, and is now setting its sights on helping customers store and process data in a hybrid manner.
In light of this technological shake out in the big data space, momentum clearly is building for alternative storage methods. In particular, object storage systems are gaining ground that’s shed by Hadoop.

Amazon S3 has become the standard protocol for accessing data, in cloud and on prem.
Cloud-based object storage systems are the real winners today, particularly AWS‘s S3, which has become de facto standard interface for today’s generation of object systems. Every software company selling object storage systems and most public cloud vendors – with the exception of Microsoft Azure and its ADLS store — sports an S3-compatible API for their object stores.
Despite the rapid growth of public clouds, enterprises still are reticent to put all their data eggs in cloud baskets. This presents a quandary, since S3 itself doesn’t run on premises.
That emerging hybrid mandate has helped fuel the growth of third-party object stores, including open source options like Red Hat‘s Ceph Swift from SwiftStack and OpenStack, and Minio Object Storage, as well as proprietary options like Scality‘s Ring, Cloudian HyperStore, Dell EMC‘s Isilon, and Nutanix Objects.
With no theoretical upper storage limit, object stores are essentially massive key-value stores, able to store petabytes or exabytes in a single global namespace, and enable data to be recalled with a simple key. Like HDFS, object storage systems typically run on clusters of X86 nodes, and feature error correction routines that reduce the chance of losing data.
Object stores excel at storing massive amounts of unstructured data, such as videos and images. Companies in media and entertainment, surveillance, healthcare, and oil and gas are big users of object storage systems, thanks to the capability to store massive amounts of data.
While scalability and elasticity are big advantages of object stores, I/O performance and data locality are disadvantages. With the biggest clusters, customers might have to wait seconds for their file to be returned. For this reason, object stores are often used for backup and archive purposes, but not for serving hot data.
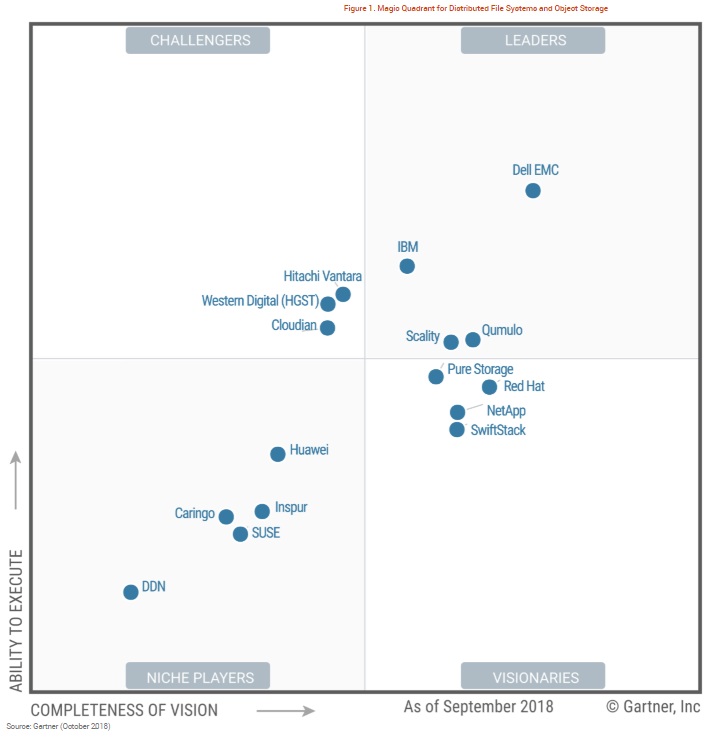
2018 Magic Quadrant for Distributed File Systems and Object Storage (Source: Gartner)
In addition to object stores, we’re also seeing the emergence of a new generation of distributed file systems, as well as modifications of existing ones like Lustre. Many of these newer distributed file systems also expose an S3 API and may share features of object stores, but which look more like traditional file systems when the covers are peeled back.
In this category, we have products like Qumulo‘s distributed file system, Elastfile Cloud File System (ECFS), WekaIO‘s Matrix, and Hedvig‘s Distributed Storage Platform, among others. In many cases, these vendors are targeting customers with workloads that require faster access.
With more sophisticated data- caching and data-tiering capabilities, these distributed file systems can deliver the speedy file I/O demanded by modern data applications and emerging machine learning and AI use cases. They also are designed to play nicely with containers like Docker and container orchestration paradigms like Kubernetes, not to mention fitting into vendors’ hyperconverged infrastructures.
This little neck of the software-defined storage wood is growing quickly. In its 2018 Magic Quadrant for Distributed File Systems and Object Storage, Gartner predicted that 80% of enterprise data will be stored in scale-out storage systems by 2022. That’s twice the amount of data that companies have stored in distributed file systems and object storage systems in 2018, when 40% of enterprise was stored in such systems.
Clearly, we are right in the thick of a period of rapid evolution in the storage space. In many cases, the lines between object stores are distributed file systems are becoming quite blurry. And many of these vendors eschew those labels entirely and call what they do a “data fabric.”
In any case, they’re all looking to deliver similar capabilities, which is to give customers the freedom to store petabytes worth of data in the place of their choosing (on-premise, cloud, or a hybrid of both), and to serve that data through a variety of interfaces, including S3 and Swift APIs but also via low-level block storage and higher-level standard NFS and SMB interfaces.
Where HDFS may have looked like the only option in town for many big data use cases, enterprises now face a plethora of big data storage options. While there are leaders in the space, there is no clear frontrunner setting the pace for all to follow (unless you count AWS’s S3 as a new standard protocol).
Like the proliferation of data silos, we’re seeing a proliferation of data storage standards. That somewhat elevates the risk for enterprises looking to avoid investing in technologies that will not last, and forces them to do their homework to find the right software-defined storage system for the right task.
Related Items:
Hitting the Reset Button on Hadoop
Mike Olson on Zoo Animals, Object Stores, and the Future of Cloudera
IBM Challenges Amazon S3 with Cloud Object Store
Applications:
Data Mining
Leading Solution Providers









Tabor Network
Sponsored Multimedia








Featured Events
-
AI & Big Data Expo North America 2024
 June 5 - June 6Santa Clara CA United States
June 5 - June 6Santa Clara CA United States -
CDAO Canada Public Sector 2024
 June 18 - June 19
June 18 - June 19 -
AI Hardware & Edge AI Summit Europe
 June 18 - June 19London United Kingdom
June 18 - June 19London United Kingdom -
AI Hardware & Edge AI Summit 2024
 September 10 - September 12San Jose CA United States
September 10 - September 12San Jose CA United States -
CDAO Government 2024
 September 18 - September 19Washington DC United States
September 18 - September 19Washington DC United States